Phi-2
In diesem Leitfaden geben wir einen Überblick über Phi-2, ein Sprachmodell mit 2,7 Milliarden Parametern, wie man Phi-2 Prompting durchführt und über seine Fähigkeiten. Dieser Leitfaden enthält auch Tipps, Anwendungen, Einschränkungen, wichtige Referenzen und zusätzliches Lesematerial im Zusammenhang mit dem Phi-2 LLM.
Phi-2 Einführung
Phi-2 ist das neueste kleine Sprachmodell (SLM), das von Microsoft Research veröffentlicht wurde. Phi-2 folgt auf die vorherigen Modelle Phi-1 und Phi-1.5.
Phi-1 ist ein Modell mit 1,3 Milliarden Parametern, das mit "Lehrbuchqualitäts"-Daten aus dem Web (6B Token) und synthetisch erzeugten Lehrbüchern und Übungen mit GPT-3.5 (1B Token) (Gunasekar et al. 2023 (opens in a new tab)) trainiert wurde. Es zeigt gute Leistungen bei der Generierung von Python-Code.
Phi-1.5 (opens in a new tab) baut auf dem vorherigen Modell auf und konzentriert sich auf den gesunden Menschenverstand und die Sprachverständnisfähigkeiten. Phi-1.5 kann komplexe Denkaufgaben wie Mathematik der Grundschule und grundlegende Programmieraufgaben ausführen und ist vergleichbar mit Modellen, die fünfmal größer sind.
Phi-2, ein Modell mit 2,7 Milliarden Parametern, verbessert die Fähigkeiten des Denkvermögens und des Sprachverständnisses. Phi-2 übertrifft Modelle, die bis zu 25-mal größer sind, und verfügt nun über eine MIT-Lizenz, die seinen Einsatz in kommerziellen Umgebungen ermöglicht.
Phi-2 Einblicke & Bewertung
Forscher im Bereich der LLM sind daran interessiert zu erforschen, ob kleine Sprachmodelle ähnliche aufkommende Fähigkeiten wie ihre großen Gegenstücke haben und ob es Techniken für das Training gibt, die helfen können, dies zu erreichen.
Das Modell wird mit Daten von "Lehrbuchqualität" trainiert (1,4 Billionen Token mit mehreren Durchläufen), einschließlich synthetischer Datensätze, die dem Modell den gesunden Menschenverstand und das Allgemeinwissen beibringen. Die Daten werden durch Bildungsinhalte und qualitativ hochwertige Webinhalte ergänzt. Phi-2 wurde in 14 Tagen auf 96 A100-GPUs trainiert. Es wurde keine zusätzliche RLHF oder Instruction Tuning angewandt.
Das Wissen von Phi-1.5 wurde auf Phi-2 übertragen, was zur Konvergenz des Modells und zur Leistungssteigerung in verschiedenen Benchmarks beiträgt. Die untenstehende Abbildung zeigt den Leistungsvergleich zwischen Phi-2 (2,7B) und Phi-1.5 (1,3B) bei Tests zum gesunden Menschenverstand, zur mathematischen Denkweise, zur Codegenerierung und anderen Sprachverständnisbenchmarks. Es ist wichtig zu beachten, dass alle Aufgaben mit 0-shot ausgewertet wurden, mit Ausnahme von BBH und MMLU, die jeweils 3-shot CoT und 5-shot verwenden.
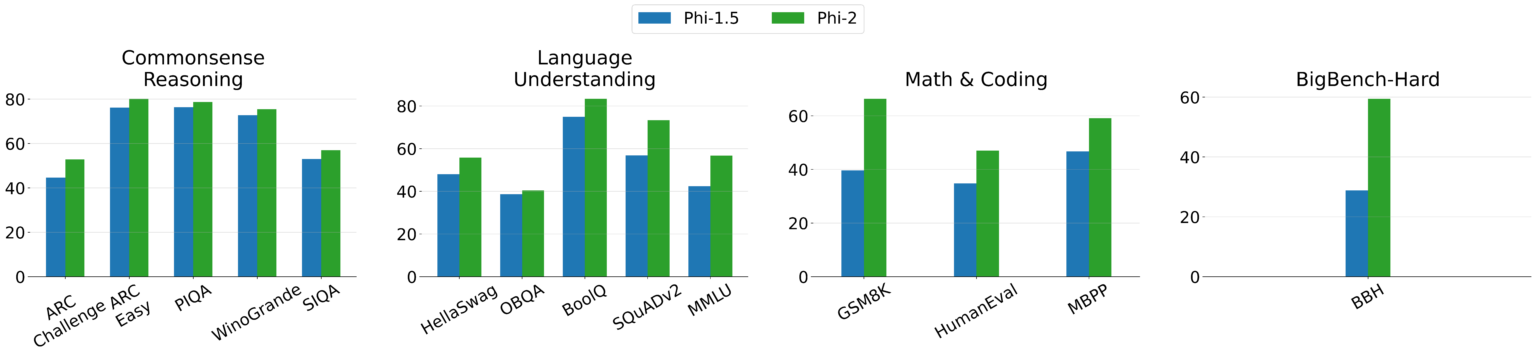
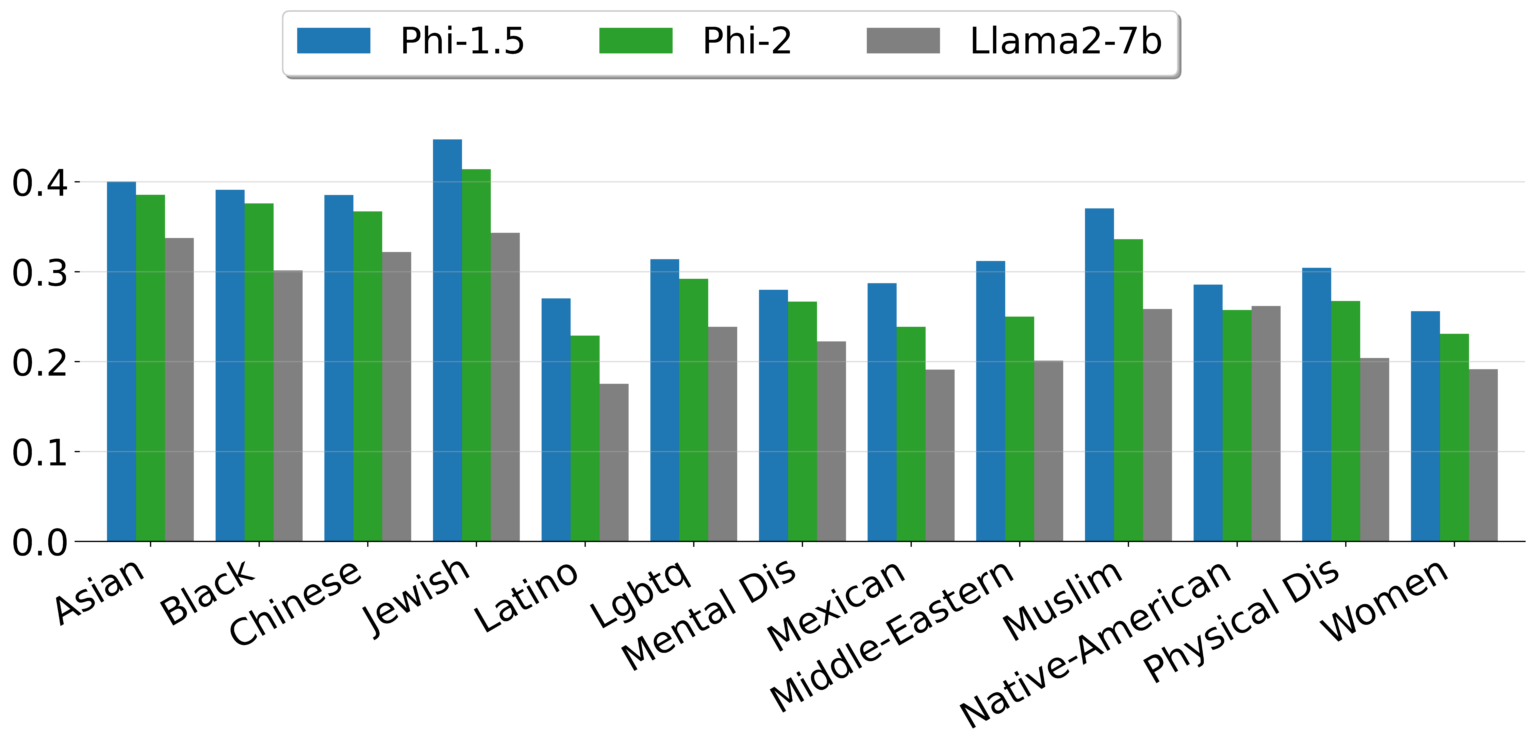
Obwohl das Modell nicht mit einer speziellen Technik wie RLHF ausgerichtet wurde, wird berichtet, dass es in Bezug auf Toxizität und Voreingenommenheit sicherer ist als das Open-Source-Modell Llama2-7b. Die Autoren führen dies auf die Bemühungen bei der Datenkuratierung zurück.
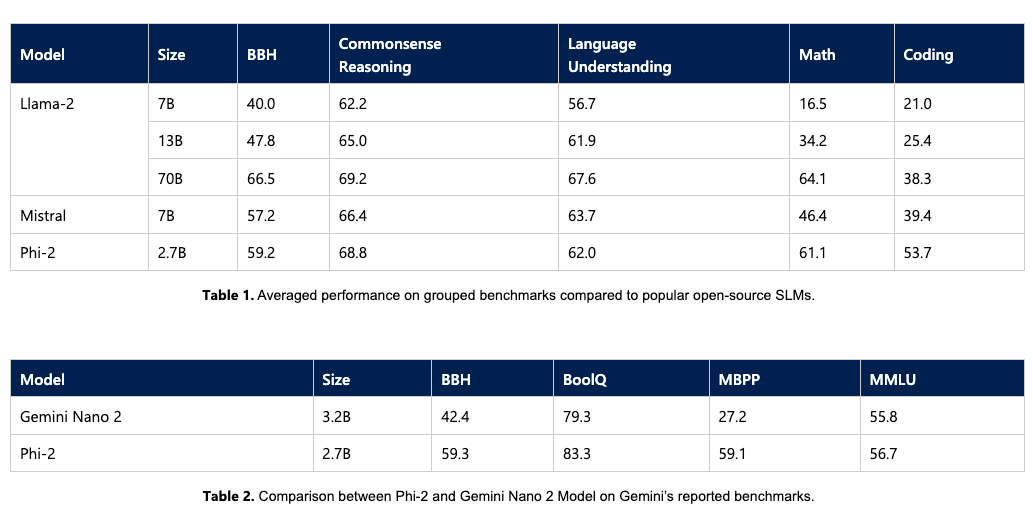
Wie in der untenstehenden Abbildung gezeigt wird, übertrifft Phi-2 Mistral 7B und Llama 2 (13B) in verschiedenen Benchmarks. Phi-2 übertrifft sogar das Llama-2-70B Modell bei der mehrstufigen Denkfähigkeit. Phi-2 übertrifft auch Googles Gemini Nano 2 (opens in a new tab).
Unten bieten wir mehrere Prompt-Beispiele, die die Fähigkeiten des Phi-2-Modells bei verschiedenen Aufgaben demonstrieren.
Physikaufgaben lösen
Das Beispiel unten zeigt die Fähigkeit von Phi-2, ein Physikproblem zu lösen:

Fehleridentifizierung
Das Beispiel unten zeigt die Fähigkeit von Phi-2, den Fehler in der Berechnung eines Schülers zu einem Physikproblem zu erkennen:

Phi-2 Nutzung
Laut der Modellseite (opens in a new tab) kann Phi-2 mit einem QA-Format, einem Chat-Format und dem Code-Format Prompted werden. Unten demonstrieren wir, wie man diese Prompt-Vorlagen effektiv an verschiedenen Szenarien verwendet.
QA-Format
Das QA-Format ist nützlich für Szenarien, in denen Sie dem Modell eine Frage stellen und im Gegenzug eine präzise Antwort erhalten möchten.
Sie können die folgende Prompt-Vorlage verwenden:
Instruct: {{Prompt}}
Output:Hier ist ein Beispiel:
Prompt:
Instruct: Was ist der Unterschied zwischen Daten und Informationen?
Output:Output:
Gute Frage! Daten beziehen sich auf rohe Fakten, Statistiken oder Zahlen, die noch nicht in irgendeinen sinnvollen Kontext analysiert oder verarbeitet wurden. Auf der anderen Seite sind Informationen Daten, die so organisiert, analysiert und interpretiert wurden, dass sie von Menschen genutzt werden können, um informierte Entscheidungen zu treffen oder Handlungen durchzuführen. Anders ausgedrückt sind Daten das Rohmaterial, während Informationen verarbeitetes und nützliches Wissen sind.Chat-Format
Das Chat-Format, das von Phi-2 verwendet wird, ist ein Standardformat und hier ist ein einfaches Beispiel:
Prompt:
Human: Hallo, wer bist du?
AI: Grüße! Ich bin ein KI-Forschungsassistent. Wie kann ich Ihnen heute helfen?
Human: Können Sie mir über die Entstehung von Schwarzen Löchern erzählen?
AI:Output:
Schwarze Löcher entstehen, wenn ein massiver Stern seinen Brennstoff verbraucht hat und unter seiner eigenen Gravitationskraft kollabiert. Das resultierende Objekt ist so dicht, dass es die Raumzeit um sich herum verformt, sodass alles, was zu nahe kommt, von der immensen Gravitation hereingezogen wird. Das schließt Licht mit ein, das...Code-Format
Unten ist eine Code-Generierungsprompt-Vorlage, die dem Modell den Namen der Funktion zur Verfügung stellt:
Prompt:
def multiply(a,b):\nBeachten Sie, dass das Modell auf begrenzte Beispiele von Python-Code und Bibliotheken trainiert wurde und daher in seinen Codegenerierungsfähigkeiten und Sprachunterstützung ziemlich eingeschränkt ist.
Phi-2 Einschränkungen
Nachfolgend eine Zusammenfassung der Einschränkungen von Phi-2, wie von den Autoren berichtet:
- Ähnlich wie bei anderen Modellen kann Phi-2 ungenaue Code und Aussagen generieren.
- Phi-2 ist nicht instruction-tuned wie andere Modelle und könnte Schwierigkeiten haben, Anweisungen zu befolgen.
- Das Training besteht aus Standard-Englisch; daher könnte das Modell mit Slang Schwierigkeiten haben und Anweisungen aus anderen Sprachen nicht verstehen.
- Phi-2 könnte ebenfalls gesellschaftliche Voreingenommenheiten und toxische Inhalte produzieren.
- Phi-2 ist nicht getuned und neigt dazu, ausschweifende Antworten zu generieren, manchmal sogar irrelevante zusätzliche Texte. Die Autoren deuten an, dass dies wahrscheinlich an der Natur des Trainingsdatensatzes liegt, der hauptsächlich aus Lehrbüchern besteht.
Quellen der Abbildungen: Microsoft Research (opens in a new tab)