Erste Schritte mit Gemini
In diesem Leitfaden geben wir Ihnen einen Überblick über die Gemini-Modelle und wie Sie sie effektiv nutzen können. Der Leitfaden beinhaltet auch Funktionen, Tipps, Anwendungen, Grenzen, wissenschaftliche Papiere und zusätzliches Lese- und Informationsmaterial zu den Gemini-Modellen.
Einführung in Gemini
Gemini ist das neueste und leistungsfähigste KI-Modell von Google Deepmind. Es wurde von Grund auf mit multimodalen Fähigkeiten erstellt und zeigt beeindruckende fächerübergreifende Denkprozesse über Texte, Bilder, Videos, Audios und Code.
Gemini gibt es in drei Größen:
- Ultra - das leistungsfähigste Modell der Serie, geeignet für hochkomplexe Aufgaben
- Pro - gilt als das beste Modell, um über ein breites Spektrum von Aufgaben hinweg skaliert zu werden
- Nano - ein effizientes Modell für speicherbeschränkte Aufgaben auf Geräten; es umfasst Modelle mit 1,8 Milliarden (Nano-1) und 3,25 Milliarden (Nano-2) Parametern und ist von größeren Gemini-Modellen abgeleitet und auf 4 Bit quantisiert.
Laut dem dazugehörigen technischen Bericht (opens in a new tab) bringt Gemini die Technologie in 30 von 32 Benchmarks weiter, die Aufgaben wie Sprache, Programmieren, Schlussfolgern und multimodales Denken umfassen.
Es ist das erste Modell, das menschenähnliche Leistungen auf dem MMLU (opens in a new tab) (ein beliebter Prüfstand) erreicht, und beansprucht Spitzenpositionen in 20 multimodalen Benchmarks. Gemini Ultra erreicht auf MMLU 90,0 % und auf dem MMMU-Benchmark (opens in a new tab), der Kenntnisse und Denkprozesse auf Hochschulniveau erfordert, 62,4 %.
Die Gemini-Modelle sind darauf trainiert, eine Kontextlänge von 32k zu unterstützen und basieren auf Transformer-Decodern mit effizienten Aufmerksamkeitsmechanismen (z.B. Multi-Query Attention (opens in a new tab)). Sie unterstützen textuelle Eingaben, die mit Audio- und Bildeingaben vermischt sind, und können Text- und Bildausgaben erzeugen.
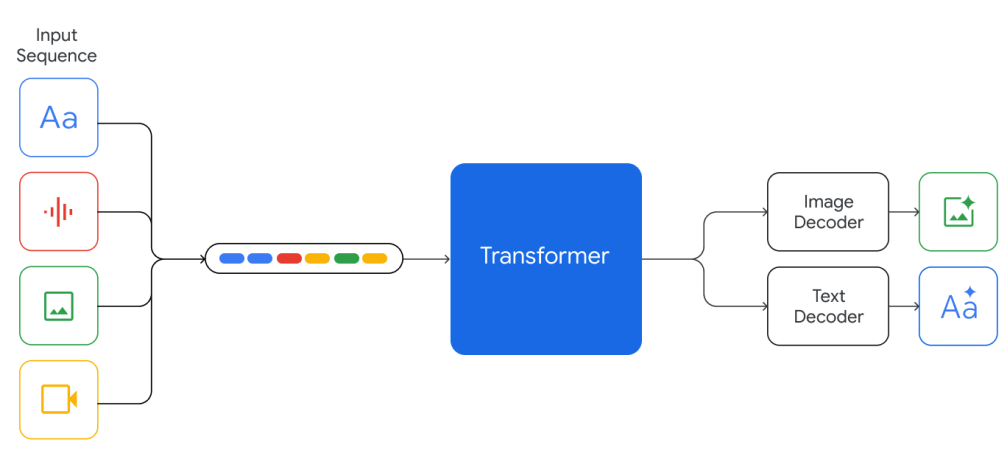
Die Modelle werden sowohl auf multimodalen als auch mehrsprachigen Daten wie Webdokumenten, Büchern und Code-Daten trainiert, einschließlich Bilder, Audios und Videos. Die Modelle werden gemeinsam über alle Modalitäten hinweg trainiert und zeigen starke fächerübergreifende Denkfähigkeiten und sogar starke Fähigkeiten in jedem einzelnen Bereich.
Experimentelle Ergebnisse von Gemini
Gemini Ultra erreicht die höchste Genauigkeit in Kombination mit Ansätzen wie Chain-of-Thought (CoT) Prompting (opens in a new tab) und Selbstkonsistenz (opens in a new tab), die dabei helfen, die Unsicherheit des Modells zu bewältigen.
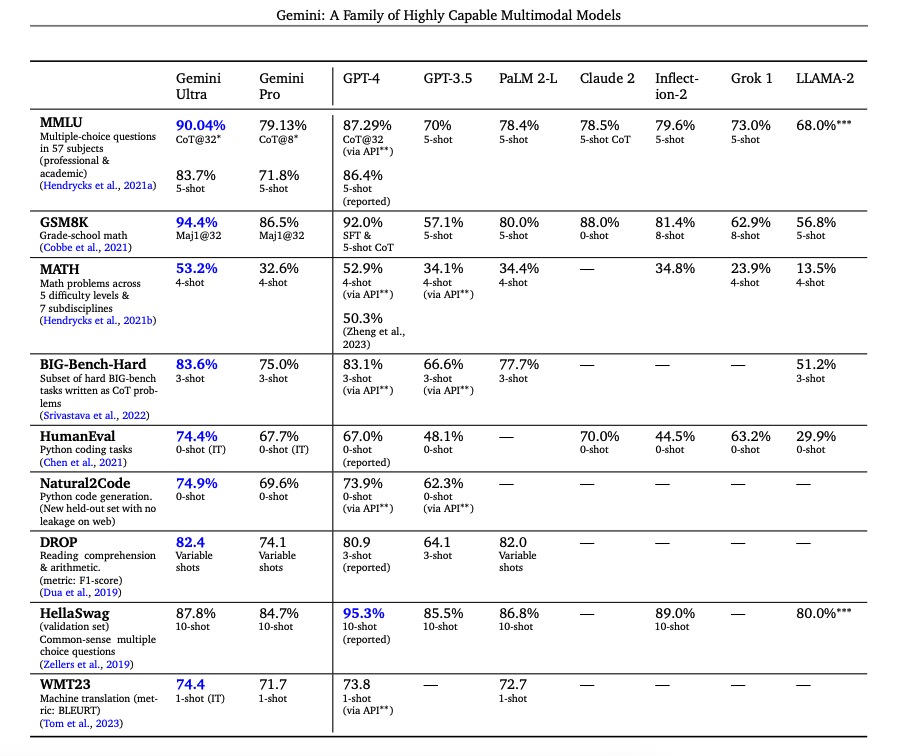
Wie im technischen Bericht dargestellt wird, verbessert Gemini Ultra seine Leistung im MMLU von 84,0 % mit Greedy Sampling auf 90,0 % mit dem durch Unsicherheiten geleiteten Chain-of-Thought-Ansatz (der CoT und Mehrheitsentscheidung umfasst) bei 32 Stichproben, während es sich marginal auf 85,0 % mit der Verwendung von nur 32 Chain-of-Thought-Stichproben verbessert. Ebenso erreicht CoT und Selbstkonsistenz eine Genauigkeit von 94,4 % beim GSM8K-Mathematik-Benchmark für Grundschüler. Darüber hinaus löst Gemini Ultra korrekt 74,4 % der HumanEval (opens in a new tab) Code-Vervollständigungsaufgaben. Unten ist eine Tabelle, die die Ergebnisse von Gemini zusammenfasst und wie die Modelle im Vergleich zu anderen bemerkenswerten Modellen stehen.
Die Gemini Nano-Modelle zeigen ebenfalls starke Leistungen bei Faktenorientierung (d.h. Aufgaben im Zusammenhang mit der Datenwiederbeschaffung), Schlussfolgern, STEM, Programmierung, multimodalen und mehrsprachigen Aufgaben.
Neben den standardmehrsprachigen Fähigkeiten zeigt Gemini eine große Leistung bei mehrsprachigen Mathematik- und Zusammenfassungs-Benchmarks wie MGSM (opens in a new tab) und XLSum (opens in a new tab).
Die Gemini-Modelle sind auf eine Sequenzlänge von 32K trainiert und zeigen, dass sie bei Abfragen über die gesamte Kontextlänge in 98 % der Fälle korrekte Werte abrufen können. Dies ist eine wichtige Fähigkeit, um neue Anwendungsfälle wie die Informationssuche in Dokumenten und das Verständnis von Videos zu unterstützen.
Die anweisungsoptimierten Gemini-Modelle werden von menschlichen Bewertenden bei wichtigen Fähigkeiten wie Anweisungsbefolgung, kreativem Schreiben und Sicherheit konstant bevorzugt.
Multimodale Denkfähigkeiten von Gemini
Gemini wird nativ mit multimodalen Fähigkeiten trainiert und zeigt die Fähigkeit, Fähigkeiten über Modalitäten hinweg mit den Denkfähigkeiten des Sprachmodells zu kombinieren. Zu den Fähigkeiten gehören unter anderem die Extraktion von Informationen aus Tabellen, Diagrammen und Bildern. Weitere interessante Fähigkeiten umfassen das Erkennen feiner Details aus Eingaben, das Aggregieren von Kontext über Raum und Zeit hinweg und das Kombinieren von Informationen aus verschiedenen Modalitäten.
Gemini übertrifft konsequent bestehende Ansätze bei Bildverständnisaufgaben wie der Erkennung von Objekten auf hohem Niveau, die Transkription feinkörniger Details, das Verstehen von Diagrammen und multimodales Denken. Einige der Bildverständnis- und Generierungsfähigkeiten übertragen sich auch auf eine vielfältige Reihe von globalen Sprachen (z. B. die Erzeugung von Bildbeschreibungen in Sprachen wie Hindi und Rumänisch).
Textzusammenfassung
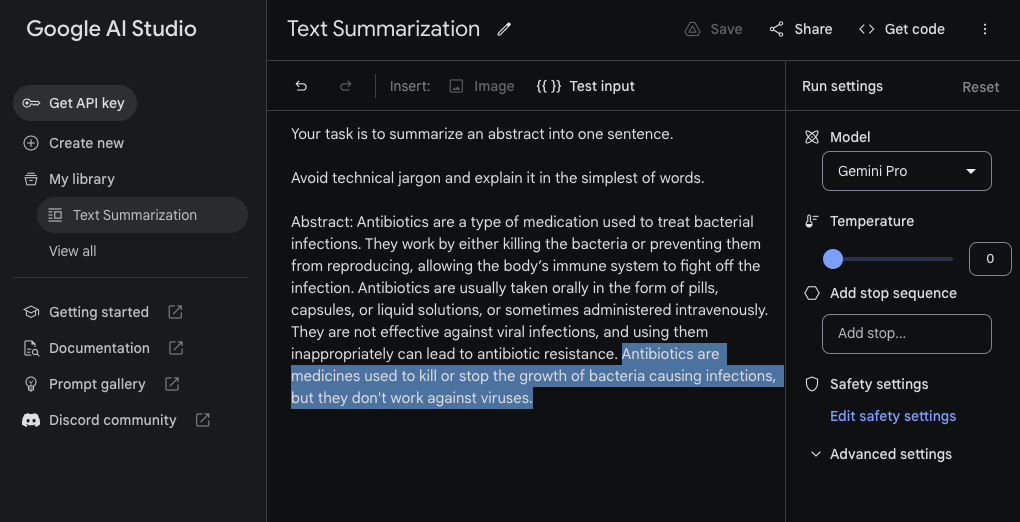
Obwohl Gemini als multimodales System trainiert wird, besitzt es viele der Fähigkeiten, die in modernen großen Sprachmodellen wie GPT-3.5, Claude und Llama vorhanden sind. Unten ist ein Beispiel für eine einfache Textzusammenfassungsaufgabe, die mit Gemini Pro durchgeführt wurde. Wir nutzen für dieses Beispiel das Google AI Studio (opens in a new tab) mit einem Temperaturwert von 0.
Prompt:
Your task is to summarize an abstract into one sentence.
Avoid technical jargon and explain it in the simplest of words.
Abstract: Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance.Gemini Pro-Ausgabe:
Antibiotics are medicines used to kill or stop the growth of bacteria causing infections, but they don't work against viruses.Hier ist der Screenshot, wie die Aufgabe und die Modellantwort (hervorgehoben) innerhalb des Google AI Studio aussehen.
Informationsgewinnung
Hier ist ein weiteres Beispiel für eine Aufgabe, die ein Stück Text analysiert und die gewünschten Informationen extrahiert. Beachten Sie, dass dies mit Zero-Shot-Prompting verwendet wird, sodass das Ergebnis nicht perfekt ist, aber das Modell schneidet relativ gut ab.
Prompt:
Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\"model_name\"]. If you don't find model names in the abstract or you are not sure, return [\"NA\"]
Abstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…Gemini Pro-Ausgabe:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]Visuelle Fragebeantwortung
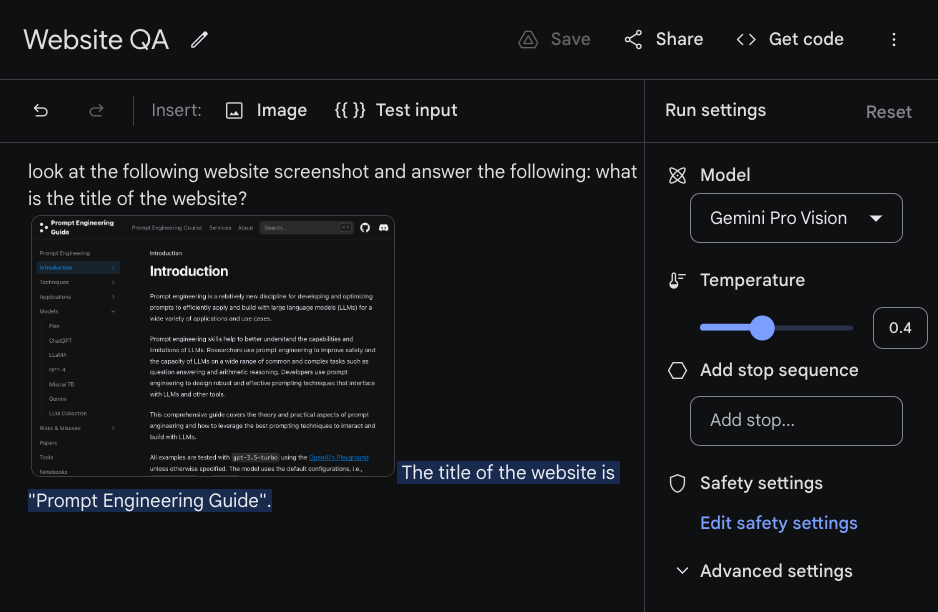
Visuelle Fragebeantwortung beinhaltet, dem Modell Fragen über ein Bild zu stellen, das als Eingabe übermittelt wird. Die Gemini-Modelle zeigen unterschiedliche multimodale Denkfähigkeiten für das Verständnis von Bildern über Diagramme, natürliche Bilder, Memes und viele andere Arten von Bildern. Im folgenden Beispiel stellen wir dem Modell (Gemini Pro Vision, zugegriffen über Google AI Studio) eine Textanweisung und ein Bild zur Verfügung, das eine Momentaufnahme dieses Leitfadens zum Prompt-Engineering darstellt.
Das Modell antwortet "Der Titel der Webseite ist 'Prompt Engineering Guide'", was angesichts der gestellten Frage die richtige Antwort zu sein scheint.
Hier ist ein weiteres Beispiel mit einer anderen Eingangsfrage. Google AI Studio ermöglicht es Ihnen, mit verschiedenen Eingaben zu experimentieren, indem Sie auf die Option {{}} Testeingabe oben klicken. Sie können dann die Prompts, die Sie testen, in der untenstehenden Tabelle hinzufügen.
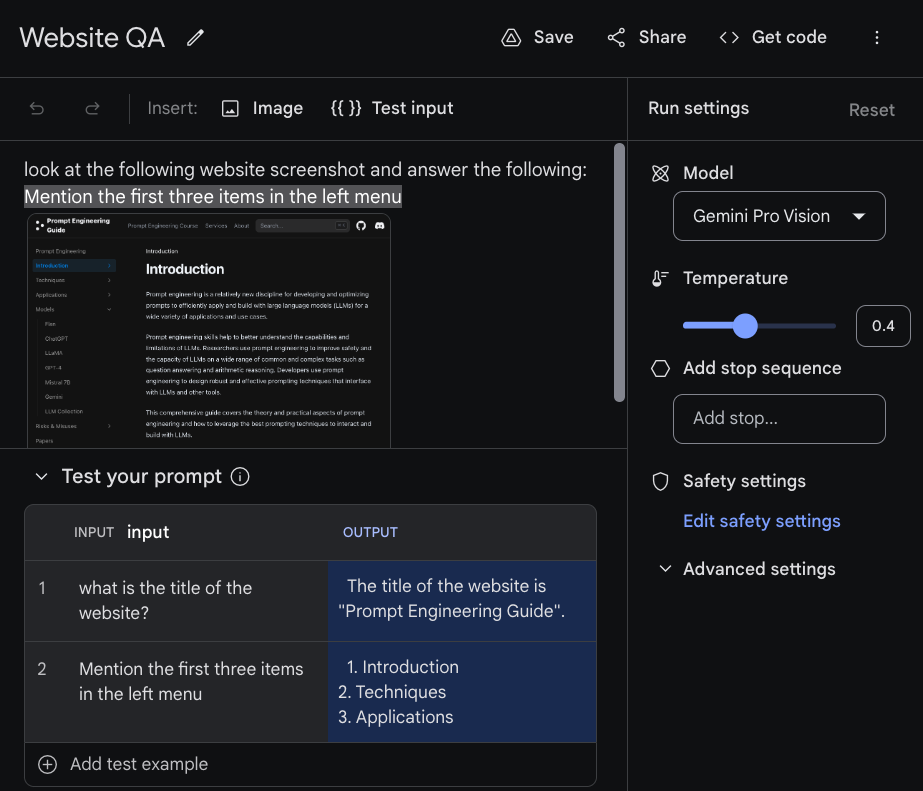
Fühlen Sie sich frei, zu experimentieren, indem Sie Ihr eigenes Bild hochladen und Fragen stellen. Es wird berichtet, dass Gemini Ultra bei diesen Arten von Aufgaben viel besser abschneiden kann. Dies ist etwas, womit wir weiterhin experimentieren werden, wenn das Modell verfügbar gemacht wird.
Verifizierung und Korrektur
Die Gemini-Modelle zeigen beeindruckende fächerübergreifende Denkfähigkeiten. Zum Beispiel zeigt die untenstehende Abbildung eine Lösung für ein physikalisches Problem, die von einem Lehrer gezeichnet wurde (links). Gemini wird dann dazu aufgefordert, über die Frage nachzudenken und zu erklären, wo der Schüler bei der Lösung einen Fehler gemacht hat, falls dies der Fall ist. Das Modell erhält außerdem die Anweisung, das Problem zu lösen und LaTeX für die mathematischen Teile zu verwenden. Die Antwort (rechts) ist die vom Modell bereitgestellte Lösung, welche das Problem und die Lösung detailreich erläutert.

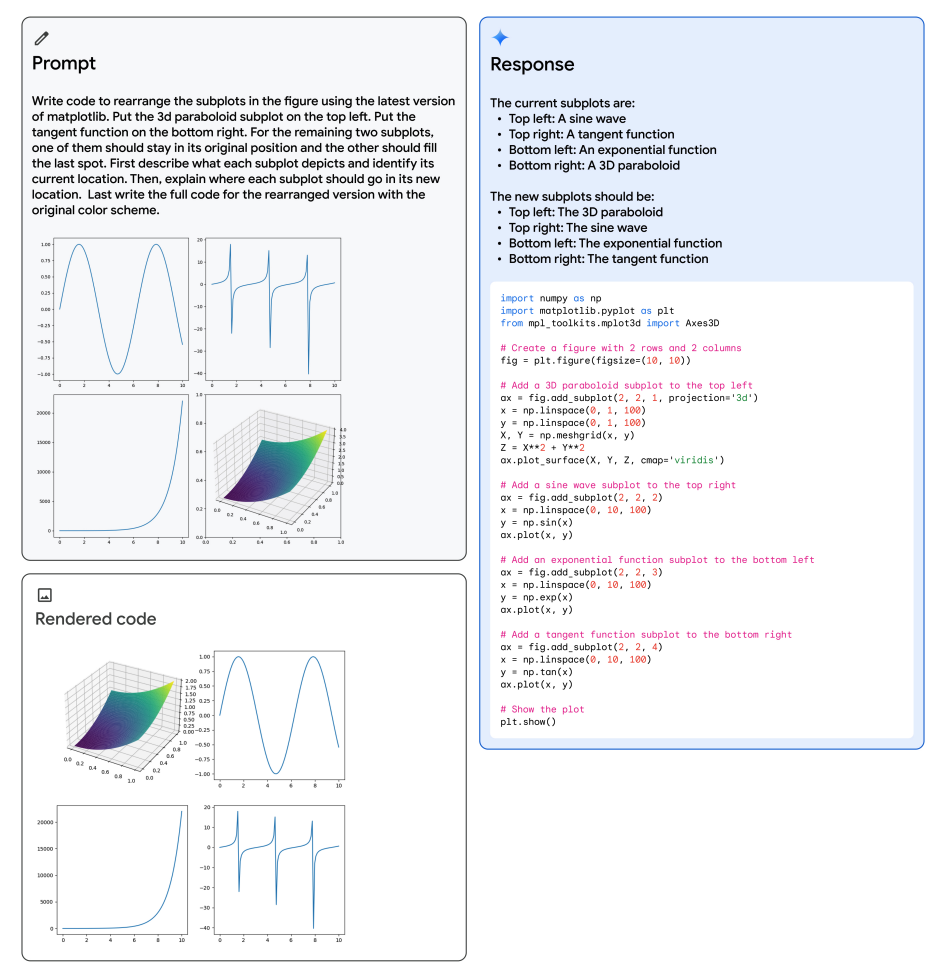
Umordnung von Abbildungen
Unten ist ein weiteres interessantes Beispiel aus dem technischen Bericht, das zeigt, wie Gemini die multimodalen Denkfähigkeiten nutzt, um Matplotlib-Code für das Umordnen von Unterplots zu erzeugen. Das multimodale Prompt wird oben links gezeigt, der erzeugte Code rechts und der gerenderte Code unten links. Das Modell nutzt mehrere Fähigkeiten, um die Aufgabe zu lösen, wie die Erkennung, Code-Erstellung, abstraktes Denken über die Position der Unterplots und das Befolgen von Anweisungen, um die Unterplots in die gewünschten Positionen zu bringen.
Videoverständnis
Gemini Ultra erreicht Spitzenresultate bei verschiedenen Few-Shot-Aufgaben zur Videobeschreibung und beim Zero-Shot-Video-Fragenbeantworten. Das untenstehende Beispiel zeigt, dass das Modell ein Video und eine Textanweisung als Eingabe erhalten hat. Es kann das Video analysieren und über die Situation nachdenken, um eine angemessene Antwort zu geben oder in diesem Fall Empfehlungen darüber, wie die Person ihre Technik verbessern könnte.

Bildverständnis
Gemini Ultra kann auch Few-Shot-Prompts verwenden und Bilder erzeugen. Zum Beispiel kann es, wie im Beispiel unten gezeigt, mit einem Beispiel von abwechselnden Bildern und Text aufgefordert werden, bei dem der Nutzer Informationen über zwei Farben und Bildvorschläge bereitstellt. Das Modell nimmt daraufhin die letzte Anweisung im Prompt und antwortet dann mit den Farben, die es sieht, zusammen mit einigen Ideen.

Kombination von Modalitäten
Die Gemini-Modelle zeigen auch die Fähigkeit, eine Folge von Audio- und Bildern nativ zu verarbeiten. An dem Beispiel können Sie beobachten, dass das Modell Prompts aus einer Reihe von Audioeingaben und Bildern verarbeiten kann. Das Modell ist dann in der Lage, eine Textantwort zurückzusenden, die den Kontext jeder Interaktion berücksichtigt.

Gemini als allgemeiner Programmieragent
Gemini wird auch verwendet, um einen generalistischen Agenten namens AlphaCode 2 (opens in a new tab) aufzubauen, der seine Denkfähigkeiten mit Suche und Werkzeugnutzung kombiniert, um kompetitive Programmierprobleme zu lösen. AlphaCode 2 rangiert innerhalb der besten 15 % der Teilnehmer auf der Codeforces-Plattform für kompetitive Programmierproblemen.
Few-Shot-Prompting mit Gemini
Few-Shot-Prompting ist ein Ansatz, der nützlich ist, um dem Modell die Art der gewünschten Ausgabe zu signalisieren. Dies ist nützlich für verschiedene Szenarien, wie wenn Sie die Ausgabe in einem bestimmten Format (z.B. JSON-Objekt) oder Stil möchten. Google AI Studio ermöglicht dies auch in der Benutzeroberfläche. Unten ist ein Beispiel dafür, wie man Few-Shot-Prompting mit den Gemini-Modellen verwendet.
Wir sind daran interessiert, einen einfachen Emotionsklassifikator mit Gemini zu erstellen. Der erste Schritt ist die Erstellung eines "Strukturierten Prompts" durch Klicken auf "Create New" oder "+". Der Few-Shot-Prompt kombiniert Ihre Anweisungen (Beschreibung der Aufgabe) und die von Ihnen bereitgestellten Beispiele. Die untenstehende Abbildung zeigt die Anweisung (oben) und die Beispiele, die wir dem Modell übergeben. Sie können den INPUT-Text und den OUTPUT-Text verwenden, um aussagekräftigere Indikatoren zu haben. Das untenstehende Beispiel verwendet "Text:" als Eingabe und "Emotion:" als die Eingabe- und Ausgabeindikatoren.
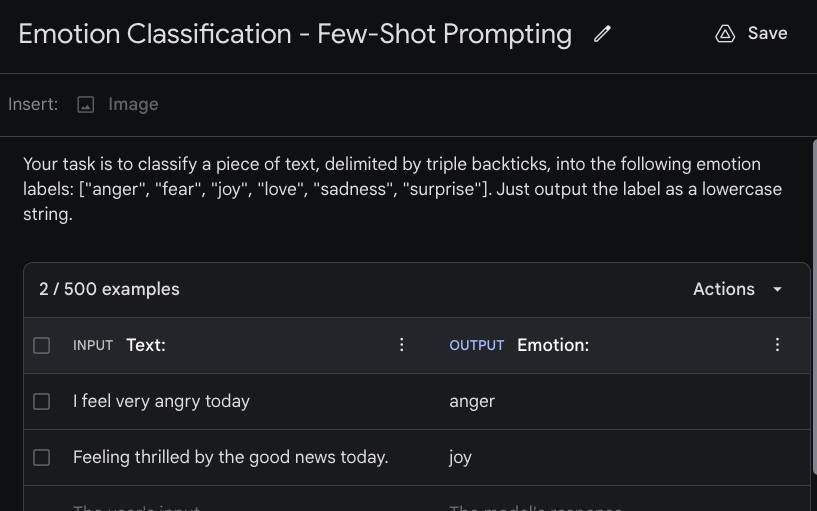
Das gesamte kombinierte Prompt lautet wie folgt:
Your task is to classify a piece of text, delimited by triple backticks, into the following emotion labels: ["anger", "fear", "joy", "love", "sadness", "surprise"]. Just output the label as a lowercase string.
Text: I feel very angry today
Emotion: anger
Text: Feeling thrilled by the good news today.
Emotion: joy
Text: I am actually feeling good today.
Emotion:Sie können dann den Prompt testen, indem Sie Eingaben im Abschnitt "Test your prompt" hinzufügen. Wir verwenden das Beispiel "I am actually feeling good today" als Eingabe und das Modell gibt korrekt das Label "joy" aus, nachdem auf "Run" geklickt wurde. Siehe das Beispiel in der untenstehenden Abbildung:
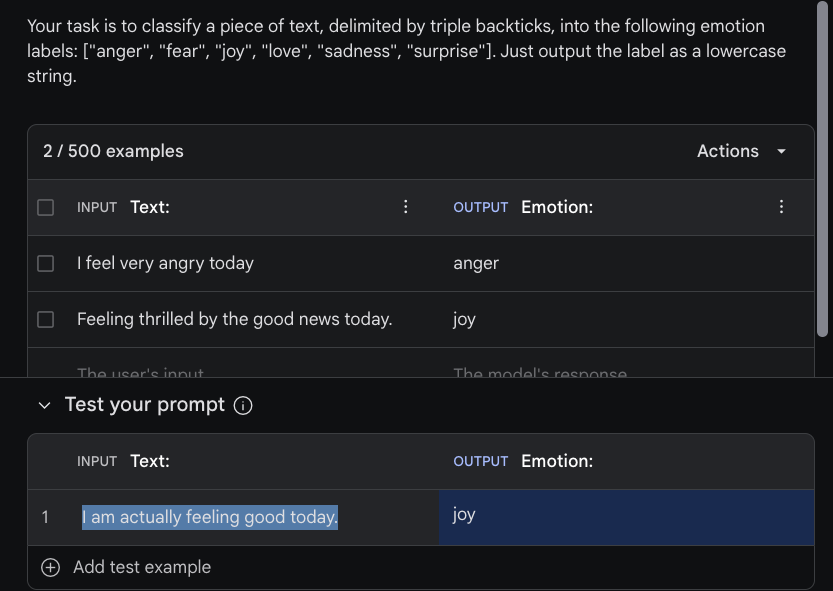
Bibliotheksverwendung
Unten ist ein einfaches Beispiel, das zeigt, wie Sie das Gemini Pro-Modell mit Hilfe der Gemini API nutzen können. Sie müssen die google-generativeai Bibliothek installieren und einen API-Schlüssel vom Google AI Studio erhalten. Das Beispiel unten ist der Code, um dieselbe Informationsgewinnungsaufgabe durchzuführen, die in den vorherigen Abschnitten verwendet wurde.
"""
Innerhalb der Kommandozeile müssen Sie nur einmal folgenden Befehl ausführen, um das Paket über pip zu installieren:
$ pip install google-generativeai
"""
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Das Modell einrichten
generation_config = {
"temperature": 0,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)
prompt_parts = [
"Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\\\"model_name\\\"]. If you don't find model names in the abstract or you are not sure, return [\\\"NA\\\"]\n\nAbstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…",
]
response = model.generate_content(prompt_parts)
print(response.text)Die Ausgabe ist die gleiche wie zuvor:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]Referenzen
- Introducing Gemini: our largest and most capable AI model (opens in a new tab)
- How it’s Made: Interacting with Gemini through multimodal prompting (opens in a new tab)
- Welcome to the Gemini era (opens in a new tab)
- Prompt design strategies (opens in a new tab)
- Gemini: A Family of Highly Capable Multimodal Models - Technical Report (opens in a new tab)
- Fast Transformer Decoding: One Write-Head is All You Need (opens in a new tab)
- Google AI Studio quickstart (opens in a new tab)
- Multimodal Prompts (opens in a new tab)
- Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases (opens in a new tab)
- A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise (opens in a new tab)