Umgang mit generierten Datensätzen und deren Vielfalt
Im vorhergehenden Kapitel (opens in a new tab) haben wir das Potenzial der Verwendung von LLMs für die Erzeugung synthetischer Datensätze diskutiert, um ein lokales Retriever-Modell weiterzuführen. Diese Methode ist aufgrund der Verfügbarkeit eines großen Korpus an nicht gekennzeichneten Dokumenten möglich. Jedes Dokument wird verwendet, um eine oder mehrere synthetische Anfragen zu generieren und ein Abfrage-Dokument-Paar zu bilden.
Aber was, wenn Information Retrieval nicht Ihre Aufgabe ist? Nehmen wir an, Sie arbeiten an einem Problem der Klassifizierung juristischer Dokumente, dürfen aber keine Daten an eine externe API senden. In dieser Situation müssten Sie ein lokales Modell trainieren. Die Datensammlung könnte jedoch zu einem erheblichen Hindernis werden und Verzögerungen in der Produktentwicklung verursachen.
Der Einfachheit halber nehmen wir an, das Ziel ist es, Kindergeschichten zu generieren. Diese Aufgabe war der Ausgangspunkt für die Forschung von Eldan et al. (2023) (opens in a new tab). Jede Geschichte besteht aus 2-3 Absätzen, die einem einfachen Handlungsverlauf und Thema folgen, während der gesamte Datensatz das Vokabular und das faktische Wissen eines Kindes abdeckt.
Sprache ist nicht nur ein System aus Regeln und Symbolen; sie übermittelt und interpretiert Bedeutung. Die Hauptherausforderung bei der Verwendung großer Sprachmodelle zur Erzeugung von Trainingsdaten besteht darin, die Vielfalt des Datensatzes sicherzustellen. Selbst mit hoher Erzeugungstemperatur (opens in a new tab) können Modelle repetitive Datensätze ohne die notwendige Vielfalt erzeugen (sogar für eine Kindersprache). Kohärenz und Relevanz sind weitere Herausforderungen in der Generierung natürlicher Sprache.
Um das Problem der Vielfalt anzugehen, bereiteten die Autoren einen Wortschatz von etwa 1500 Grundwörtern vor, der einem typischen Kinderwortschatz entspricht, unterteilt in Substantive, Verben und Adjektive. Bei jeder Erzeugung wurde ein Verb, ein Substantiv und ein Adjektiv zufällig ausgewählt. Das Modell generiert dann eine Geschichte, die diese zufälligen Wörter integriert.
Diese Technik erweiterte die Vielfalt des Datensatzes erheblich und stellte sicher, dass die Geschichten den gesamten Wortschatz eines Kindes und verschiedene Konzeptkombinationen abdecken. Zusätzlich integrierten die Autoren mögliche Merkmale der Geschichte (wie Dialoge, Handlungswendungen, schlechte Enden oder moralische Lektionen). Eine zufällige Teilmenge dieser Merkmale wurde für jede Geschichte ausgewählt und das Modell wurde aufgefordert, sie einzuschließen.
Prompt:
Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”{random.choice(verbs_list)}”, the noun ”{random.choice(nouns_list)}” and the adjective ”{random.choice(adjectives_list)}”. The story should have the following features: {random.choice(features_list)}, {random.choice(features_list)}. Remember to only use simple words!Nehmen wir an, die Lücken wurden wie folgt gefüllt:
Prompt:
Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”decorate”, the noun ”thunder” and the adjective ”ancient”. The story should have the following features: the story should contain at least one dialogue, the story has a bad ending. Remember to only use simple words!Output:
Once upon a time, in an ancient house, there lived a girl named Lily. She loved to decorate her room with pretty things. One day, she found a big box in the attic. She opened it and saw many shiny decorations. Lily was very happy and decided to use them in her room. As Lily was decorating her room, the sky outside became dark. There was a loud thunder sound, and Lily got scared. She ran to her mom and said, ”Mommy, the thunder is so loud!” Her mom hugged her and said, ”Don’t worry, it will pass soon.” But the thunder did not stop. It got louder and louder, and the ancient house started to shake. Suddenly, the roof fell down on the pretty decorations. Lily was sad because her room was not pretty anymore. The end.Hier verlassen wir uns auf die neuesten Textgenerierungsmodelle (GPT-3.5 und GPT-4), die große Mengen an synthetischem Inhalt gemäß den Anweisungen erzeugen können. Da wir das Prompt jedes Mal zufällig formulieren und das Modell ihm genau folgt, werden die Geschichten unglaublich vielfältig. Selbst wenn ein oder zwei Wörter gleich bleiben, ist die Erzählung völlig anders. Im Wesentlichen wenden wir diese Technik an, um Zufälligkeit in den Prompt einzuführen und so einen vielfältigen Datensatz zu erzeugen.
Der Ablauf ist also wie folgt:
- Identifizieren Sie, welche Parameter/Entitäten zwischen verschiedenen Proben in Ihrem synthetischen Datensatz variieren könnten;
- Erstellen oder generieren Sie eine Sammlung dieser Entitäten, um die Lücken zu füllen;
- Erzeugen Sie den Datensatz, indem Sie Entitäten zufällig für die Einfügung auswählen. Es ist am besten, die Erzeugungstemperatur höher als standardmäßig, aber unter dem Maximum einzustellen;
- Trainieren Sie ein lokales Modell auf den Erzeugungsergebnissen von ChatGPT/GPT-4.
Es ist wichtig zu beachten, dass eine der Entitäten, die als Ausgangspunkt verwendet wurden, ein Klassenlabel sein könnte. Zum Beispiel können Sie im Aufgabenbereich der Sentiment-Klassifikation "positiv" oder "negativ" direkt im Prompt erwähnen, um einen generierten Text mit dem entsprechenden Label zu erhalten. Danach wird ein lokaler Klassifikator mit diesen Daten trainiert.
Iterative (hierarchische) synthetische Datengenerierung
Das Format kann durch die Verwendung noch mehrerer Entitäten komplexer gestaltet werden, von denen einige zuvor vom LLM selbst erzeugt wurden. Zum Beispiel könnte man mit der Aufforderung beginnen, eine Zusammenfassung einer Geschichte zu erzeugen und einen Satz niederzuschreiben, der in der Geschichte vorkommen muss. Später verwenden Sie einfach diese generierten Zwischendaten in der endgültigen Anfrage.
Prompt:
Zusammenfassung: {eine von LLM erzeugte kurze Zusammenfassung, die den obigen Ansatz verwendet}
Merkmale: {kopieren Sie die Merkmale aus dem ursprünglichen Prompt}
Satz: {ein von LLM erzeugter Satz, der in der Geschichte vorkommen soll}
Wörter: {kopieren Sie die Wörter aus dem ursprünglichen Prompt}
Geschichte:Beispiel für einen ausgefüllten Prompt:
Prompt:
Zusammenfassung: Lily und Timmy bauen zusammen eine Sandburg und lernen Kompromisse zu schließen, aber sie wird von einer Windböe umgestoßen. Sie finden Schönheit in der zerbrochenen Sandburg und spielen glücklich mit einem Schmetterling.
Merkmale: Dialog, Vorahnung, Wendung
Satz: Eines Tages ging sie in den Park und sah einen schönen Schmetterling.
Wörter: streiten, Netzwerk, schön
Geschichte:Output:
Es war einmal ein kleines Mädchen namens Lily. Sie liebte es, mit ihren Spielzeugen und ihren Freunden zu spielen. Eines Tages ging sie in den Park und sah einen schönen Schmetterling. Sie versuchte ihn zu fangen, aber er flog weg. Lilys Freund Timmy kam, um mit ihr zu spielen. Sie beschlossen, eine Sandburg zu bauen, aber sie waren unterschiedlicher Meinung, wie sie gebaut werden sollte. Lily wollte sie hoch bauen, während Timmy sie breit haben wollte. Sie stritten eine Weile, kamen aber schließlich überein, sie sowohl hoch als auch breit zu machen. Während sie die Sandburg bauten, bemerkten sie eine Gruppe von Ameisen, die zusammenarbeiteten. Sie stellten fest, dass die Ameisen ein Netzwerk von Tunneln bauten. Plötzlich kam eine Windböe und stieß ihre Sandburg um. Sie waren traurig, sahen dann aber wieder den Schmetterling. Er landete auf den Überresten ihrer Sandburg und sie erkannten, dass sie immer noch schön war, selbst in ihrem zerbrochenen Zustand. Sie lächelten und spielten glücklich zusammen.So ist es möglich, Hunderttausende von sehr vielfältigen Beispielen zu erzeugen, um das Modell zu trainieren. Nehmen wir an, Sie müssen einen Klassifikator trainieren, der bestimmt, ob ein Text einen Dialog oder eine Handlungswendung enthält. Da das ursprüngliche Prompt Labels enthält, ist bekannt, welcher Zielwert für jede generierte Probe vorhergesagt werden muss.
Lehrbücher sind alles, was Sie brauchen
Eine entscheidende Frage, die sich aus diesem Ansatz ergibt, ist, ob die Synthese eines Datensatzes tatsächlich Vorteile bietet, wenn Netzwerke für reale Anwendungen trainiert werden. Glücklicherweise gingen die Autoren auf diese Frage ein, indem sie ihre Untersuchung durchführten und die Wirksamkeit des Trainings kleinerer Sprachmodelle mit Hilfe von synthetischen Daten, die von State-of-the-Art LLMs abgeleitet wurden, validierten.
In ihrer Studie betonen Gunasekar et al. (2023) (opens in a new tab) die Bedeutung von hochwertigen Trainingsdaten bei ihrem Modell. Sie argumentieren, dass Sprachmodelle effektiver wären, wenn sie auf Materialien trainiert würden, die die Eigenschaften eines angesehenen "Lehrbuchs" ähneln: klar, umfassend, informativ und unvoreingenommen.
Diese Prinzipien bildeten die Grundlage für die Erstellung eines semi-synthetischen Datensatzes für das Training eines LLMs namens Phi-1. Die Hauptbewertungsaufgabe besteht darin, eine Python-Funktion zu generieren, die einer gegebenen Textbeschreibung oder einem Docstring folgt. Die Qualität des Modells wird anhand des HumanEval-Benchmarks (Chen et al., 2021 (opens in a new tab)) bewertet.
Die Autoren heben die Bedeutung der Vielfalt in diesem Ansatz aus mehreren Gründen hervor. Sie konfrontiert das Sprachmodell mit einer Vielzahl von Programmierausdrücken und Problemlösungsansätzen, reduziert das Risiko des Overfittings oder der Abhängigkeit von bestimmten Mustern und verbessert die Fähigkeit des Modells, unbekannte oder innovative Aufgaben zu bewältigen.
Um die Herausforderung des Code-Schreibens zu bewältigen, erstellten die Autoren lehrbuchähnliche Dokumente, die sich auf Themen konzentrieren, die das logische Denken und die grundlegenden algorithmischen Fähigkeiten fördern. Sie erreichten Vielfalt durch die Festlegung von Beschränkungen bei:
- Themen
- Zielgruppe
Leider gaben die Autoren keine spezifischen Informationen über die Vorlage des Prompts, die zur Erzeugung der synthetischen Daten verwendet wurde. Sie zeigten jedoch das resultierende Ergebnis. Sie entschieden sich dafür, ChatGPT (GPT-3.5) anstelle von GPT-4 zu verwenden, und selbst diese Strategie lieferte ausgezeichnete Ergebnisse, da sie das Modell mit synthetischen Daten feinabstimmten.

Bildquelle: Gunasekar et al. (2023) (opens in a new tab)
Es ist wesentlich, auf die Beschränkung der Zielgruppe zu achten. Eine Zielgruppe festzulegen ist eine ausgezeichnete Möglichkeit, die Vielfalt der synthetischen Daten zu erhöhen. Ein Schüler der Sekundarstufe, ein Bachelor-Student der Informatik und ein Doktorand formulieren ihre Erklärungen und verarbeiten Informationen sicherlich unterschiedlich, wodurch die erzeugten Daten noch vielfältiger werden. Lassen Sie uns versuchen, das Prompt nachzustellen.
Prompt:
Schreiben Sie einen Auszug aus einem Informatik-Lehrbuch für einen Bachelorstudenten im ersten Jahr. Die Programmiersprache ist Python 3.6.
Dies ist ein Auszug aus der Mitte des folgenden Themas: Singuläre Matrizen.
Der Auszug beginnt mit einer Übersicht über das Thema auf hoher Ebene. Dann präsentiert er ein Beispiel und beschreibt die Lösung in natürlicher Sprache. Danach liefert er 1-2 Code-Snippets, die dem Beispiel folgen. Jedes Snippet hat höchstens 10 Zeilen. Nach den Code-Snippets sollte kein Text stehen.
Beachten Sie, dass der Auszug knapp sein sollte und nur ein Konzept auf einmal erklären sollte. Der Code sollte eine Python-Funktion und deren Aufruf darstellen. Alle gängigen ML/DS-Bibliotheken sind verfügbar.
Seien Sie nicht zu wortreich. Die erwartete Länge des Auszugs beträgt höchstens zwei Absätze.Output:
**Singuläre Matrizen**
In der linearen Algebra wird eine Matrix als "singulär" bezeichnet, wenn sie keine Inverse besitzt. Eine weitere äquivalente Definition ist, wenn die Determinante der Matrix Null ist. Singuläre Matrizen sind entscheidend, da sie Systeme linearer Gleichungen repräsentieren, die keine eindeutige Lösung haben.
Betrachten Sie eine 2x2-Matrix `[[a, b], [c, d]]`. Wenn das Produkt aus `ad` und `bc` dasselbe ist (also `ad = bc`), dann ist diese Matrix singulär. Lassen Sie uns dies anhand eines Beispiels untersuchen: Gegeben sei die Matrix `[[2, 4], [1, 2]]`, finden Sie heraus, dass das Produkt der Diagonalen das gleiche Ergebnis liefert (2 * 2 = 4 * 1), somit ist es eine singuläre Matrix.
import numpy as np
def is_singular(matrix):
determinant = np.linalg.det(matrix)
return abs(determinant) < 1e-9
matrix_example = np.array([[2, 4], [1, 2]])
print(is_singular(matrix_example)) # gibt True zurückZiemlich nah dran!
Insgesamt generierten die Autoren 1B Tokens, um das Training des Modells zu ergänzen, wodurch ein kleineres Modell (mit nur 1,5 Milliarden Parametern) mit Modellen konkurrieren kann, die zehnmal so groß sind (weitere Details finden Sie im Artikel Gunasekar et al. (2023) (opens in a new tab)).
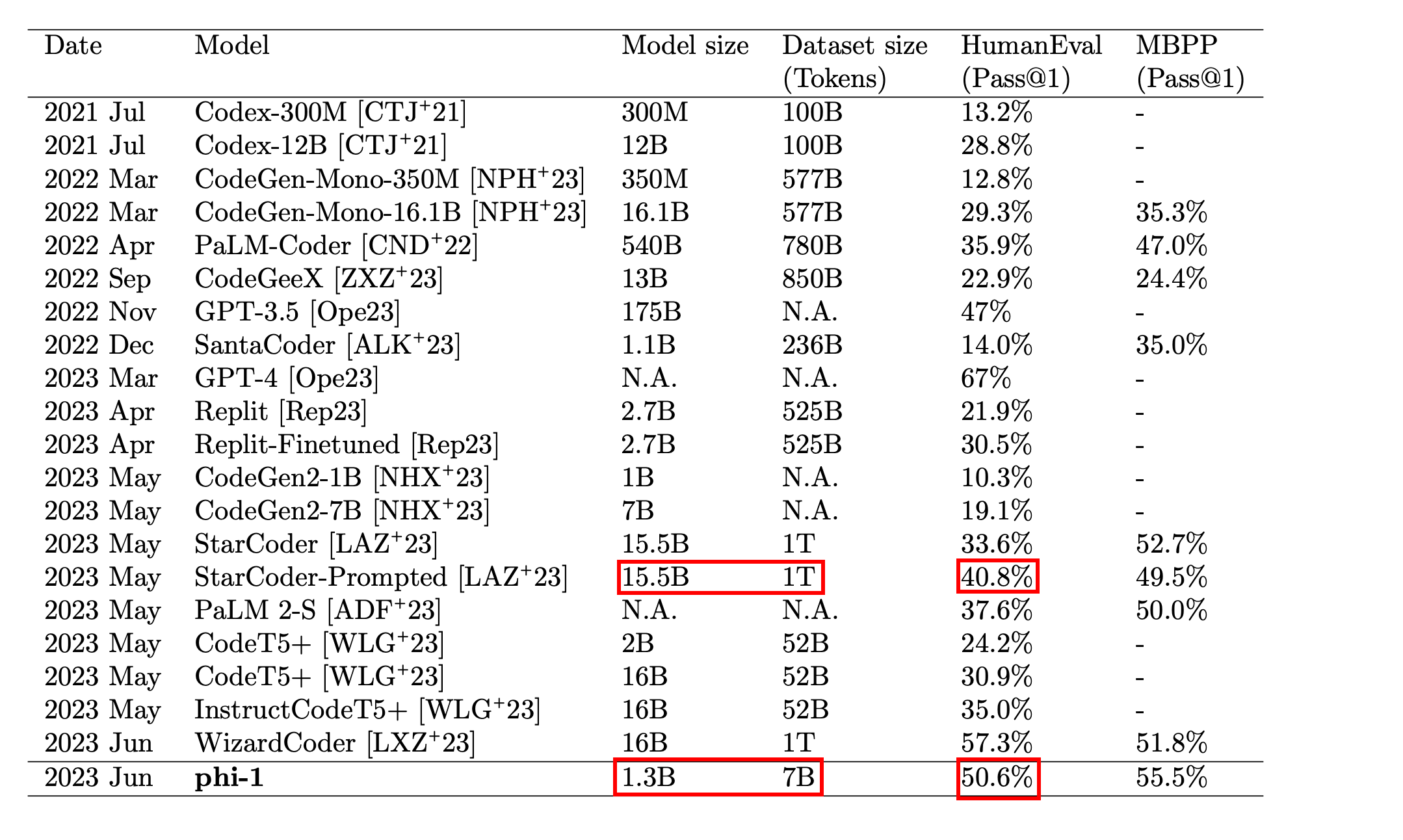
Bildquelle: Gunasekar et al. (2023) (opens in a new tab)
Für Ihre Aufgabe benötigen Sie wahrscheinlich keine so große Menge an synthetischen Daten (da die Autoren das Pretraining untersuchten, das erhebliche Ressourcen erfordert). Doch selbst als Schätzung, zum Preis von $0.002 pro 1k Tokens (Standardpreis von ChatGPT), würde es $2000 für die generierten Tokens kosten und etwa den gleichen Betrag für die Prompts.
Beachten Sie, dass das Feintuning mit synthetischen Daten wertvoller wird, je spezifischer die Domäne wird, besonders wenn die Sprache von Englisch abweicht (neben anderen Faktoren). Zusätzlich funktioniert diese Methode gut mit Chain-of-Thought (CoT) (opens in a new tab) und hilft dem lokalen Modell, seine Argumentationsfähigkeiten zu verbessern. Auch andere Prompting-Techniken funktionieren. Und vergessen Sie nicht, dass Open-Source-Modelle wie Alpaca (Taori et al., (2023) (opens in a new tab)) und Vicuna (Zheng et al., (2023) (opens in a new tab)) durch das Feintuning mit synthetischen Daten glänzen.