LLaMA: Offene und Effiziente Basismodelle für Sprache
Dieser Abschnitt befindet sich in intensiver Entwicklung.
Was gibt's Neues?
Dieses Paper führt eine Sammlung von Basismodellen für Sprache ein, die zwischen 7 Milliarden und 65 Milliarden Parameter variieren.
Die Modelle wurden mit Billionen von Tokens auf öffentlich verfügbaren Datensätzen trainiert.
Die Arbeit von (Hoffman et al. 2022) (opens in a new tab) zeigt, dass Modelle mit kleinerer Anzahl von Parametern, die auf viel mehr Daten trainiert wurden, eine bessere Performance erreichen können als größere Pendants - und das bei niedrigerem Rechenbudget. Diese Arbeit empfiehlt das Training von 10-Milliarden-Parameter-Modellen auf 200 Milliarden Tokens. Die LLaMA-Studie jedoch findet heraus, dass die Performance eines 7-Milliarden-Parameter-Modells sogar nach 1 Billion Tokens weiterhin steigt.
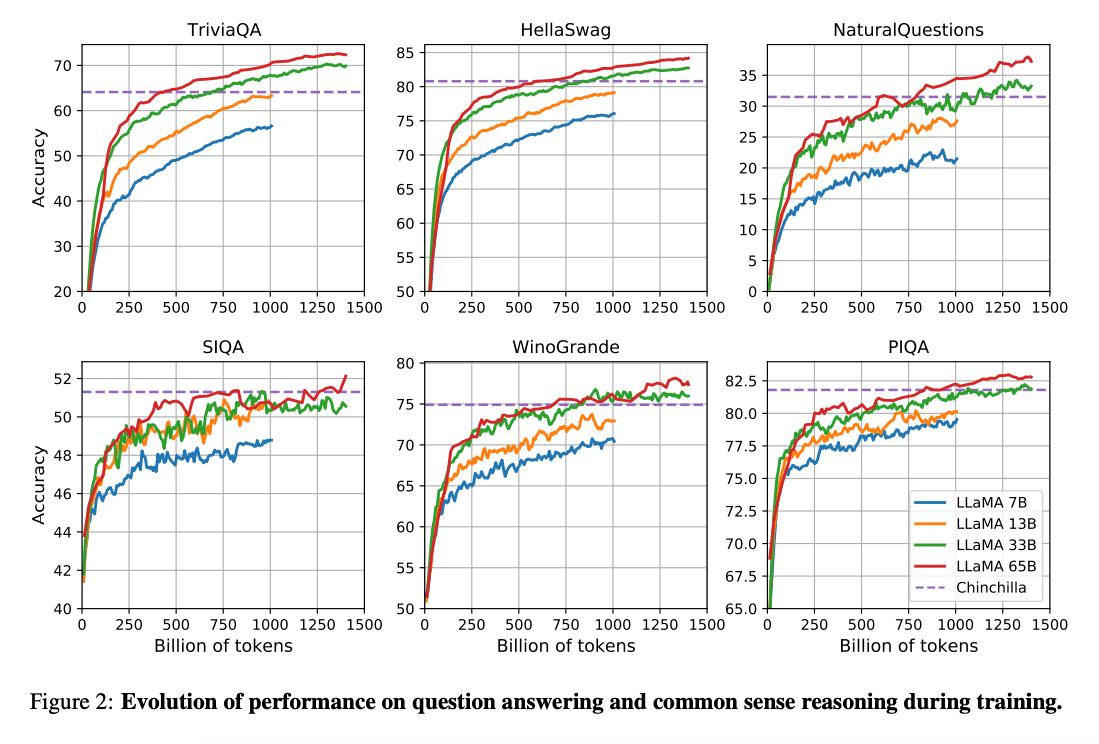
Diese Arbeit konzentriert sich darauf, Modelle (LLaMA) zu trainieren, die bei verschiedenen Inferenzbudgets die bestmögliche Leistung erzielen, indem auf mehr Tokens trainiert wird.
Fähigkeiten & Wichtigste Ergebnisse
Insgesamt übertrifft LLaMA-13B GPT-3(175B) bei vielen Benchmarks, trotz einer 10x geringeren Größe und der Möglichkeit, auf einer einzelnen GPU betrieben zu werden. LLaMA 65B ist wettbewerbsfähig mit Modellen wie Chinchilla-70B und PaLM-540B.
Paper: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Code: https://github.com/facebookresearch/llama (opens in a new tab)
Referenzes
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (März 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (März 2023)
- GPT4All (opens in a new tab) (März 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (März 2023)
- Stanford Alpaca (opens in a new tab) (März 2023) "pages/models/llama.en.mdx" [noeol] 43L, 2219B