Mixtral 8x22B
Mixtral 8x22B ist ein neues offenes großes Sprachmodell (LLM), das von Mistral AI veröffentlicht wurde. Mixtral 8x22B wird als sparsames Mischmodell aus Experten charakterisiert, mit 39 Milliarden aktiven Parametern aus insgesamt 141 Milliarden Parametern.
Fähigkeiten
Mixtral 8x22B wurde entwickelt, um ein kosteneffizientes Modell zu sein, mit Fähigkeiten, die mehrsprachiges Verständnis, mathematisches Denken, Codegenerierung, native Funktionsaufrufunterstützung und eingeschränkte Ausgabeunterstützung umfassen. Das Modell unterstützt eine Kontextfenstergröße von 64000 (64K) Token, was eine leistungsstarke Informationsabrufung bei großen Dokumenten ermöglicht.
Mistral AI behauptet, dass Mixtral 8x22B eines der besten Leistungs-Kosten-Verhältnisse unter den Community-Modellen bietet und aufgrund seiner sparsamen Aktivierungen deutlich schnell ist.
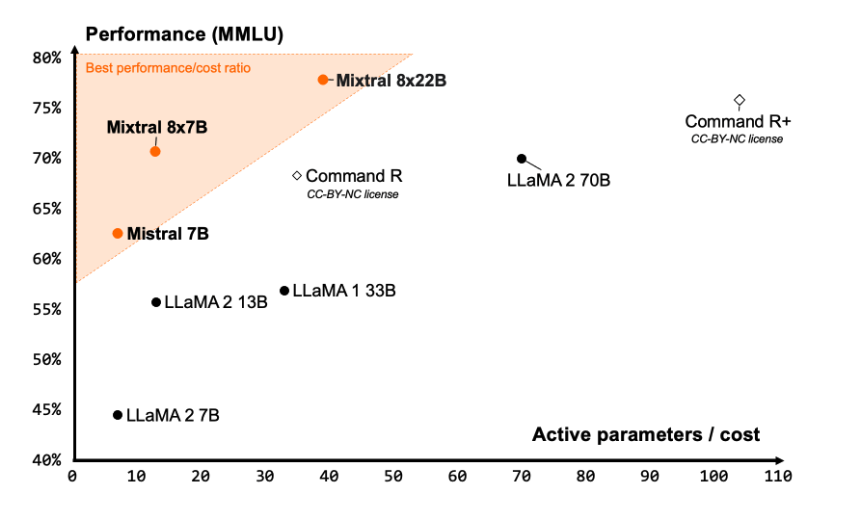 Quelle: Mistral AI Blog (opens in a new tab)
Quelle: Mistral AI Blog (opens in a new tab)
Ergebnisse
Gemäß den offiziell berichteten Ergebnissen (opens in a new tab) übertrifft Mixtral 8x22B (mit 39 Milliarden aktiven Parametern) andere Spitzenmodelle wie Command R+ und Llama 2 70B in mehreren Denk- und Wissensbenchmarks wie MMLU, HellaS, TriQA, NaturalQA unter anderen.
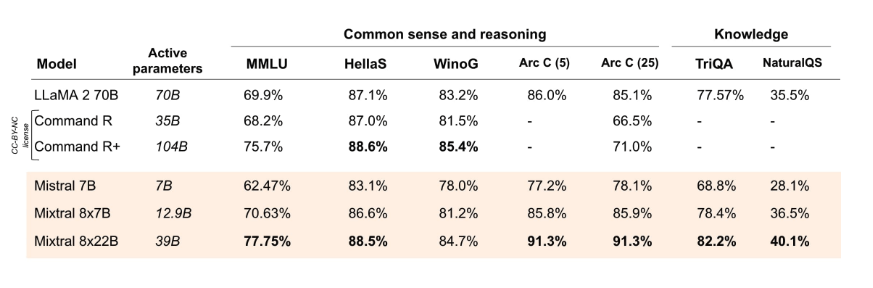 Quelle: Mistral AI Blog (opens in a new tab)
Quelle: Mistral AI Blog (opens in a new tab)
Mixtral 8x22B übertrifft alle offenen Modelle bei Programmier- und Mathematikaufgaben, wenn es anhand von Benchmarks wie GSM8K, HumanEval und Math bewertet wird. Es wird berichtet, dass Mixtral 8x22B Instruct eine Punktzahl von 90% auf GSM8K (maj@8) erreicht.
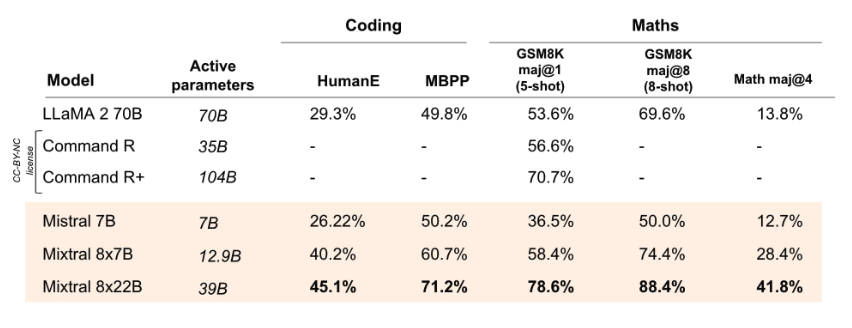 Quelle: Mistral AI Blog (opens in a new tab)
Quelle: Mistral AI Blog (opens in a new tab)
Weitere Informationen zu Mixtral 8x22B und dessen Nutzung finden Sie hier: https://docs.mistral.ai/getting-started/open_weight_models/#operation/listModels (opens in a new tab)
Das Modell wird unter einer Apache 2.0-Lizenz veröffentlicht.