Getting Started with Gemini
In this guide, we provide an overview of the Gemini models and how to effectively prompt and use them. The guide also includes capabilities, tips, applications, limitations, papers, and additional reading materials related to the Gemini models.
Introduction to Gemini
Gemini is the newest most capable AI model from Google Deepmind. It's built with multimodal capabilities from the ground up and can showcases impressive crossmodal reasoning across texts, images, video, audio, and code.
Gemini comes in three sizes:
- Ultra - the most capable of the model series and good for highly complex tasks
- Pro - considered the best model for scaling across a wide range of tasks
- Nano - an efficient model for on-device memory-constrained tasks and use-cases; they include 1.8B (Nano-1) and 3.25B (Nano-2) parameters models and distilled from large Gemini models and quantized to 4-bit.
According to the accompanying technical report (opens in a new tab), Gemini advances state of the art in 30 of 32 benchmarks covering tasks such as language, coding, reasoning, and multimodal reasoning.
It is the first model to achieve human-expert performance on MMLU (opens in a new tab) (a popular exam benchmark), and claim state of the art in 20 multimodal benchmarks. Gemini Ultra achieves 90.0% on MMLU and 62.4% on the MMMU benchmark (opens in a new tab) which requires college-level subject knowledge and reasoning.
The Gemini models are trained to support 32k context length and built of top of Transformer decoders with efficient attention mechanisms (e.g., multi-query attention (opens in a new tab)). They support textual input interleaved with audio and visual inputs and can produce text and image outputs.
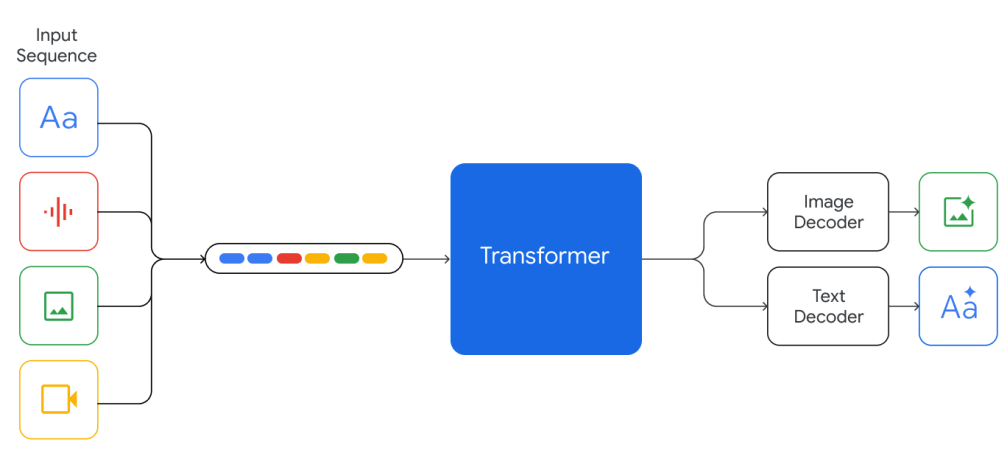
The models are trained on both multimodal and multilingual data such as web documents, books, and code data, including images, audio, and video data. The models are trained jointly across all modalities and show strong crossmodal reasoning capabilities and even strong capabilities in each domain.
Gemini Experimental Results
Gemini Ultra achieves highest accuracy when combined with approaches like chain-of-thought (CoT) prompting (opens in a new tab) and self-consistency (opens in a new tab) which helps dealing with model uncertainty.
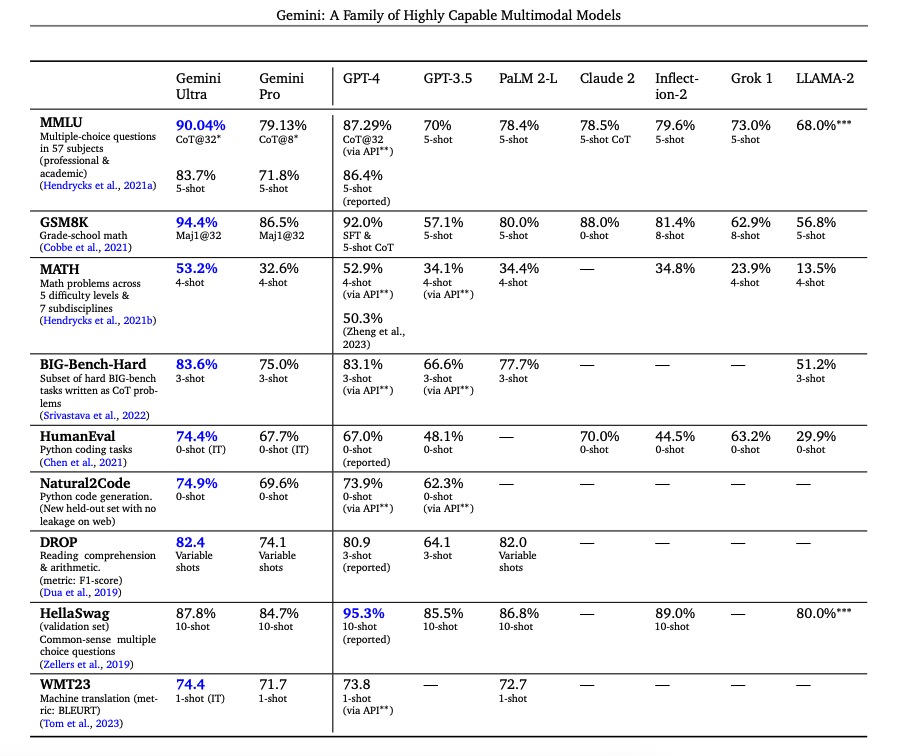
As reported in the technical report, Gemini Ultra improves its performance on MMLU from 84.0% with greedy sampling to 90.0% with uncertainty-routed chain-of-thought approach (involve CoT and majority voting) with 32 samples while it marginally improves to 85.0% with the use of 32 chain-of-thought samples only. Similarly, CoT and self-consistency achieves 94.4% accuracy on the GSM8K grade-school math benchmark. In addition, Gemini Ultra correctly implements 74.4% of the HumanEval (opens in a new tab) code completion problems. Below is a table summarizing the results of Gemini and how the models compare to other notable models.
The Gemini Nano Models also show strong performance on factuality (i.e. retrieval-related tasks), reasoning, STEM, coding, multimodal and multilingual tasks.
Besides standard multilingual capabilities, Gemini shows great performance on multilingual math and summarization benchmarks like MGSM (opens in a new tab) and XLSum (opens in a new tab), respectively.
The Gemini models are trained on a sequence length of 32K and are found to retrieve correct values with 98% accuracy when queried across the context length. This is an important capability to support new use cases such as retrieval over documents and video understanding.
The instruction-tuned Gemini models are consistently preferred by human evaluators on important capabilities such as instruction following, creative writing, and safety.
Gemini Multimodal Reasoning Capabilities
Gemini is trained natively multimodal and exhibits the ability to combine capabilities across modalities with the reasoning capabilities of the language model. Capabilities include but not limited to information extraction from tables, charts, and figures. Other interesting capabilities include discerning fine-grained details from inputs, aggregating context across space and time, and combining information across different modalities.
Gemini consistently outperforms existing approaches across image understanding tasks such as high-level object recognition, fine-grained transcription, chart understanding, and multimodal reasoning. Some of the image understanding and generation capabilities also transfer across a diverse set of global language (e.g., generating image descriptions using languages like Hindi and Romanian).
Text Summarization
While Gemini is trained as a multimodal system it possess many of the capabilities present in modern large language models like GPT-3.5, Claude, and Llama. Below is an example of a simple text summarization task using Gemini Pro. We are using Google AI Studio (opens in a new tab) for this example with a temperature value of 0.
Prompt:
Your task is to summarize an abstract into one sentence.
Avoid technical jargon and explain it in the simplest of words.
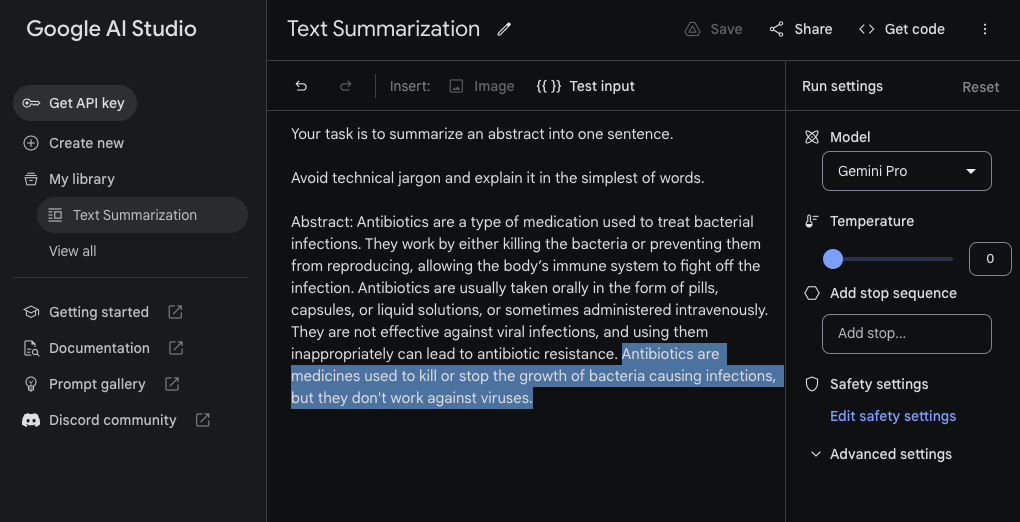
Abstract: Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance.Gemini Pro Output:
Antibiotics are medicines used to kill or stop the growth of bacteria causing infections, but they don't work against viruses.Here is the screenshot of how the task and model response (highlighted) looks inside Google AI Studio.
Information Extraction
Here is another example of a task that analyzes a piece of text and extracts the desired information. Keep in mind that this is using zero-shot prompting so the result is not perfect but the model is performing relatively well.
Prompt:
Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\"model_name\"]. If you don't find model names in the abstract or you are not sure, return [\"NA\"]
Abstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…Gemini Pro Output:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]Visual Question Answering
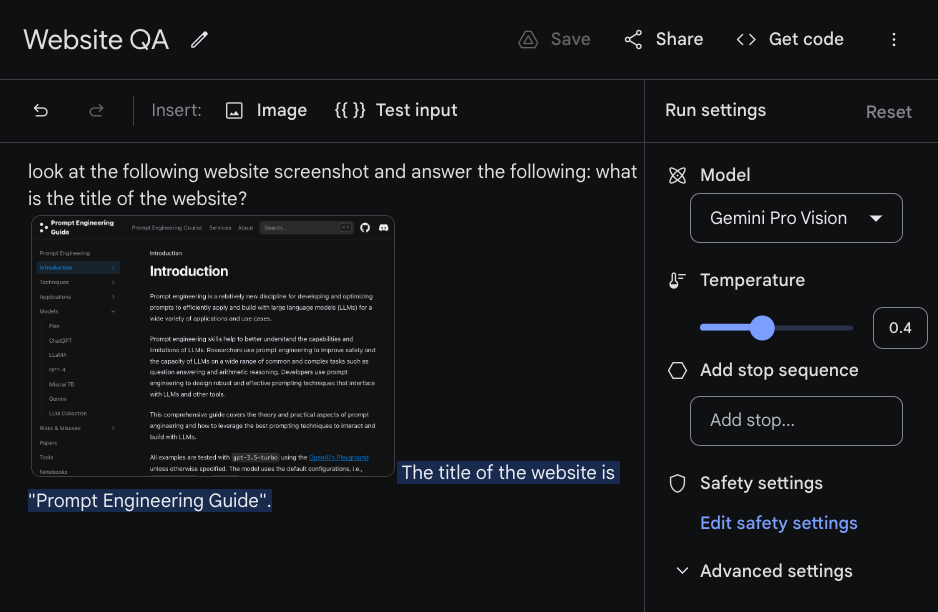
Visual question answering involves asking the model questions about an image passed as input. The Gemini models show different multimodal reasoning capabilities for image understanding over charts, natural images, memes, and many other types of images. In the example below, we provide the model (Gemini Pro Vision accessed via Google AI Studio) a text instruction and an image which represents a snapshot of this prompt engineering guide.
The model responds "The title of the website is "Prompt Engineering Guide"." which seems like the correct answer based on the question given.
Here is another example with a different input question. Google AI Studio allows you to test with different inputs by click on the {{}} Test input option above. You can then add the prompts you are testing in the table below.
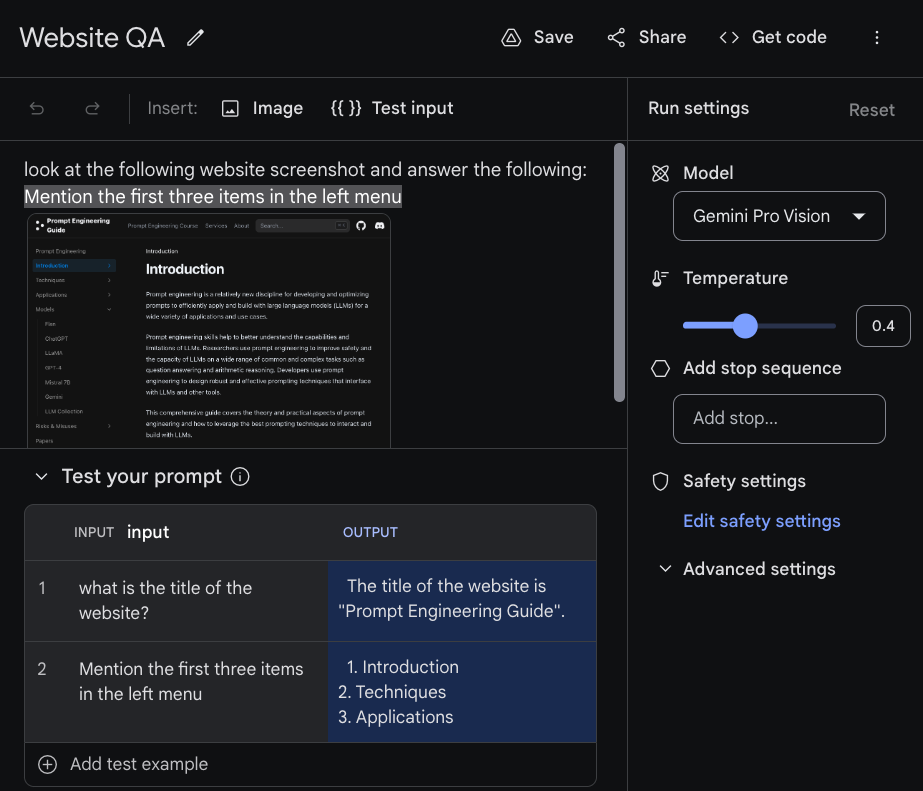
Feel free to experiment by uploading your own image and asking questions. It's reported that Gemini Ultra can do a lot better at these types of tasks. This is something we will experiment more with when the model is made available.
Verifying and Correcting
Gemini models display impressive crossmodal reasoning capabilities. For instance, the figure below demonstrates a solution to a physics problem drawn by a teacher (left). Gemini is then prompted to reason about the question and explain where the student went wrong in the solution if they did so. The model is also instructed to solve the problem and use LaTeX for the math parts. The response (right) is the solution provided by the model which explains the problem and solution with details.

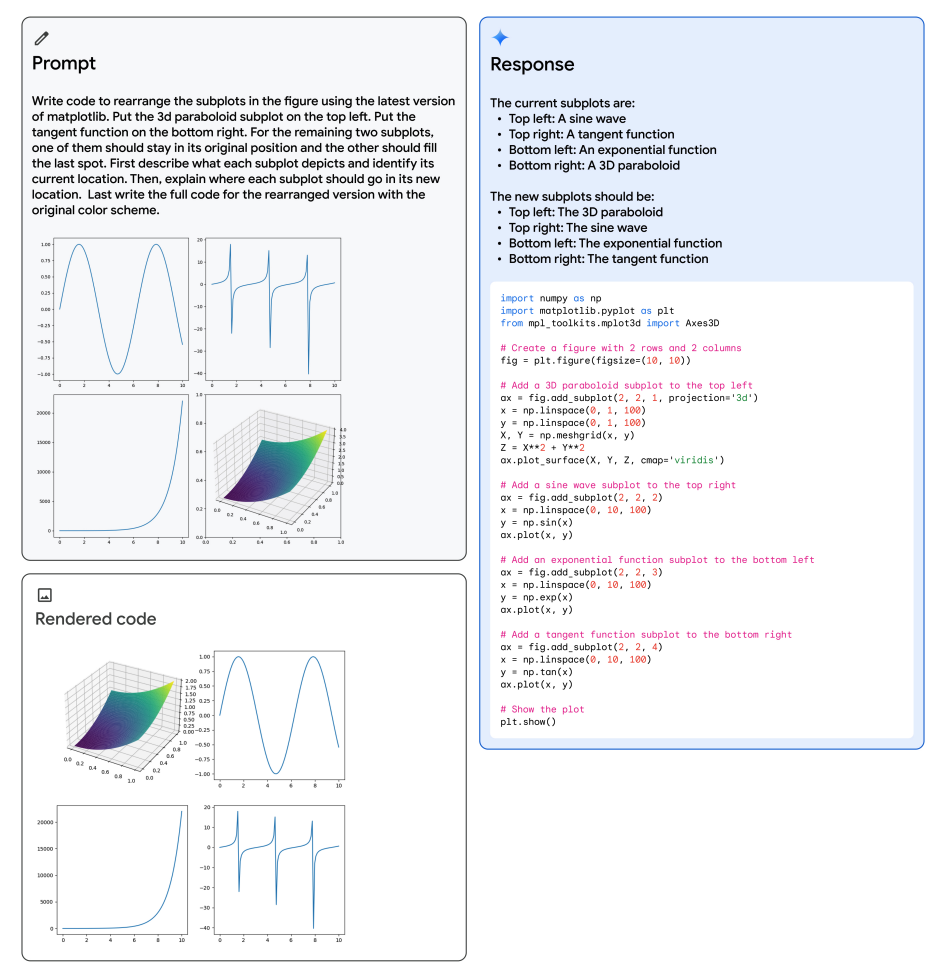
Rearranging Figures
Below is another interesting example from the technical report showing Gemini's multimodal reasoning capabilities to generate matplotlib code for rearranging subplots. The multimodal prompt is shown on the top left, the generated code on the right, and the rendered code on the bottom left. The model is leveraging several capabilities to solve the task such as recognition, code generation, abstract reasoning on subplot location, and instruction following to rearrange the subplots in their desired positions.
Video Understanding
Gemini Ultra achieves state-of-the-art results on various few-shot video captioning tasks and zero-shot video question answering. The example below shows that the model is provided a video and text instruction as input. It can analyze the video and reason about the situation to provide an appropriate answer or in this case recommendations on how the person could improve their technique.

Image Understanding
Gemini Ultra can also take few-shot prompts and generate images. For example, as shown in the example below, it can be prompted with one example of interleaved image and text where the user provides information about two colors and image suggestions. The model then take the final instruction in the prompt and then respond with the colors it sees together with some ideas.

Modality Combination
The Gemini models also show the ability to process a sequence of audio and images natively. From the example, you can observe that the model can be prompted with a sequence of audio and images. The model is able to then send back a text response that's taking the context of each interaction.

Gemini Generalist Coding Agent
Gemini is also used to build a generalist agent called AlphaCode 2 (opens in a new tab) that combines it's reasoning capabilities with search and tool-use to solve competitive programming problems. AlphaCode 2 ranks within the top 15% of entrants on the Codeforces competitive programming platform.
Few-Shot Prompting with Gemini
Few-shot prompting is a prompting approach which is useful to indicate to the model the kind of output that you want. This is useful for various scenarios such as when you want the output in a specific format (e.g., JSON object) or style. Google AI Studio also enables this in the interface. Below is an example of how to use few-shot prompting with the Gemini models.
We are interested in building a simple emotion classifier using Gemini. The first step is to create a "Structured prompt" by clicking on "Create new" or "+". The few-shot prompt will combine your instructions (describing the task) and examples you have provided. The figure below shows the instruction (top) and examples we are passing to the model. You can set the INPUT text and OUTPUT text to have more descriptive indicators. The example below is using "Text:" as input and "Emotion:" as the input and output indicators, respectively.
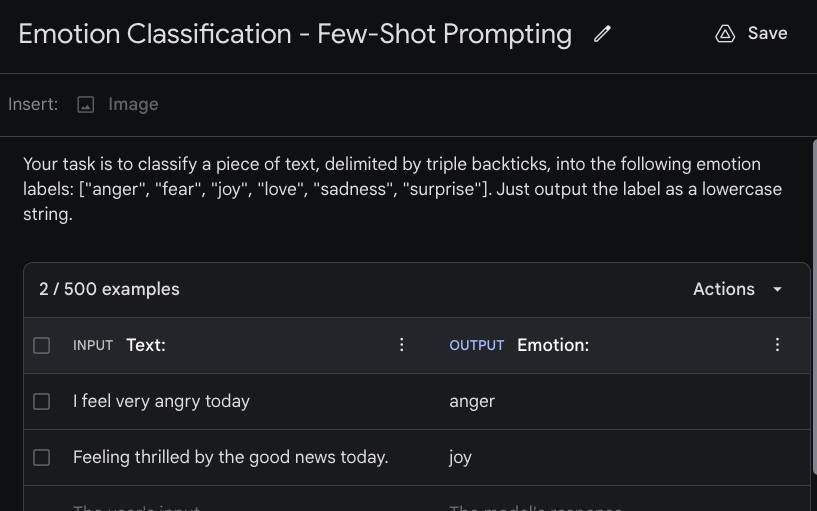
The entire combined prompt is the following:
Your task is to classify a piece of text, delimited by triple backticks, into the following emotion labels: ["anger", "fear", "joy", "love", "sadness", "surprise"]. Just output the label as a lowercase string.
Text: I feel very angry today
Emotion: anger
Text: Feeling thrilled by the good news today.
Emotion: joy
Text: I am actually feeling good today.
Emotion:You can then test the prompt by adding inputs to under the "Test your prompt" section. We are using the "I am actually feeling good today." example as input and the model correctly outputs the "joy" label after clicking on "Run". See the example in the figure below:
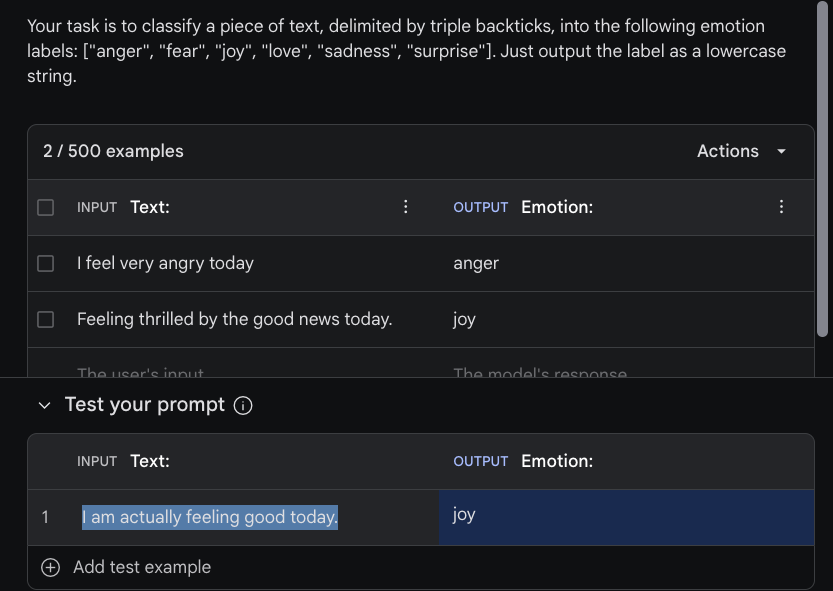
Library Usage
Below is a simple example that demonstrates how to prompt the Gemini Pro model using the Gemini API. You need install the google-generativeai library and obtain an API Key from Google AI Studio. The example below is the code to run the same information extraction task used in the sections above.
"""
At the command line, only need to run once to install the package via pip:
$ pip install google-generativeai
"""
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Set up the model
generation_config = {
"temperature": 0,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)
prompt_parts = [
"Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\\\"model_name\\\"]. If you don't find model names in the abstract or you are not sure, return [\\\"NA\\\"]\n\nAbstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…",
]
response = model.generate_content(prompt_parts)
print(response.text)The output is the same as before:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]References
- Introducing Gemini: our largest and most capable AI model (opens in a new tab)
- How it’s Made: Interacting with Gemini through multimodal prompting (opens in a new tab)
- Welcome to the Gemini era (opens in a new tab)
- Prompt design strategies (opens in a new tab)
- Gemini: A Family of Highly Capable Multimodal Models - Technical Report (opens in a new tab)
- Fast Transformer Decoding: One Write-Head is All You Need (opens in a new tab)
- Google AI Studio quickstart (opens in a new tab)
- Multimodal Prompts (opens in a new tab)
- Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases (opens in a new tab)
- A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise (opens in a new tab)