Effiziente Infinite Context Transformer
Ein neues Paper (opens in a new tab) von Google integriert kompressiven Speicher in eine Vanilla Dot-Product Attention-Schicht.
Das Ziel ist es, Transformer-LLMs zu ermöglichen, effektiv unendlich lange Eingaben mit begrenztem Speicherbedarf und Rechenaufwand zu verarbeiten.
Sie schlagen eine neue Aufmerksamkeitstechnik vor, die als Infini-Attention bezeichnet wird, welche eine kompressive Speichereinheit in einen Vanilla-Aufmerksamkeitsmechanismus einbaut.
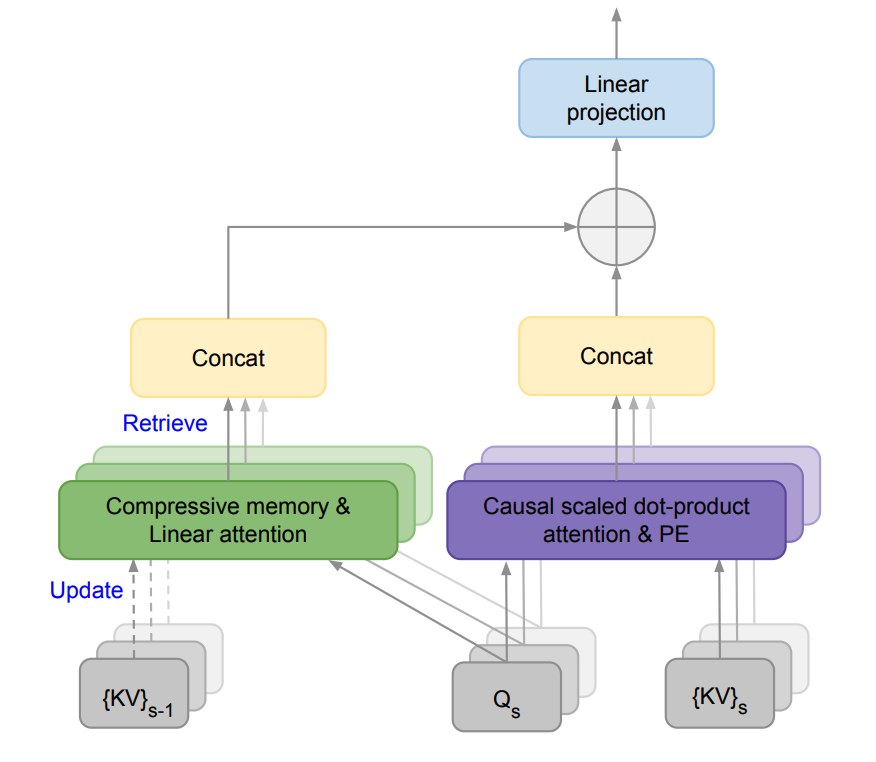
Es kombiniert sowohl maskierte lokale Aufmerksamkeit als auch langfristige lineare Aufmerksamkeit in einem einzigen Transformer-Block. Dies ermöglicht es dem Infini-Transformer-Modell, effizient sowohl lang- als auch kurzreichende Kontextabhängigkeiten zu handhaben.
Dieser Ansatz übertrifft Basismodelle beim langkontextuellen Sprachmodellieren mit einem Speicherkompressionsverhältnis von 114x!
Sie zeigen auch, dass ein 1B LLM natürlich auf eine Sequenzlänge von 1M skaliert werden kann und ein 8B-Modell ein neues SoTA-Ergebnis bei einer Buchzusammenfassungsaufgabe mit einer Länge von 500K erreicht.
Angesichts der wachsenden Bedeutung von langkontextuellen LLMs könnte ein effektives Speichersystem leistungsstarke Fähigkeiten im Bereich des Schlussfolgerns, Planens, der kontinuierlichen Anpassung und bisher in LLMs nicht gesehene Fähigkeiten freisetzen.