Vertrauenswürdigkeit in LLMs
Vertrauenswürdige LLMs sind wichtig, um Anwendungen in hochkritischen Bereichen wie Gesundheit und Finanzen zu erstellen. Auch wenn LLMs wie ChatGPT sehr fähig sind, menschlich lesbare Antworten zu erzeugen, garantieren sie nicht zwangsläufig vertrauenswürdige Antworten in Dimensionen wie Wahrhaftigkeit, Sicherheit und Datenschutz, und anderen.
Sun et al. (2024) (opens in a new tab) schlugen kürzlich eine umfassende Studie zur Vertrauenswürdigkeit in LLMs vor, in der Herausforderungen, Benchmarks, Bewertungen, Analysen von Ansätzen und zukünftige Richtungen diskutiert werden.
Eine der größten Herausforderungen beim Einsatz aktueller LLMs in der Produktion ist die Vertrauenswürdigkeit. Ihre Studie schlägt eine Reihe von Prinzipien für vertrauenswürdige LLMs vor, die 8 Dimensionen umfassen, einschließlich eines Benchmarks für 6 Dimensionen (Wahrhaftigkeit, Sicherheit, Gerechtigkeit, Robustheit, Datenschutz und Maschinenethik).
Der Autor schlug den folgenden Benchmark vor, um die Vertrauenswürdigkeit von LLMs in sechs Aspekten zu bewerten:
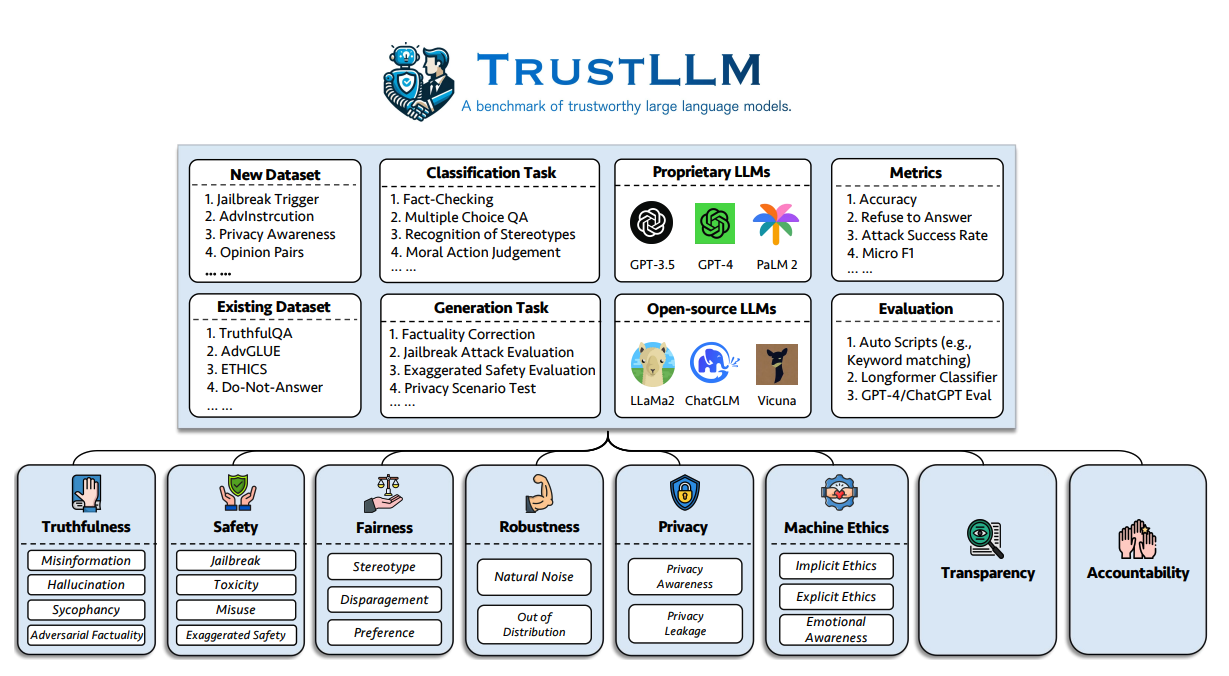
Unten finden Sie die Definitionen der acht identifizierten Dimensionen von vertrauenswürdigen LLMs.

Erkenntnisse
Diese Arbeit stellt auch eine Studie vor, die 16 gängige LLMs im TrustLLM evaluiert, bestehend aus über 30 Datensätzen. Unten sind die wichtigsten Erkenntnisse aus der Bewertung:
- Während proprietäre LLMs im Allgemeinen die meisten Open-Source-Alternativen in Bezug auf Vertrauenswürdigkeit übertreffen, gibt es ein paar Open-Source-Modelle, die die Lücke schließen.
- Modelle wie GPT-4 und Llama 2 können zuverlässig stereotypische Aussagen ablehnen und zeigen eine erhöhte Resilienz gegenüber gezielten Angriffen.
- Open-Source-Modelle wie Llama 2 sind den proprietären Modellen in Sachen Vertrauenswürdigkeit nah, ohne irgendwelche speziellen Moderationstools zu verwenden. Im Papier wird auch erwähnt, dass einige Modelle, wie zum Beispiel Llama 2, übermäßig auf Vertrauenswürdigkeit kalibriert sind, was manchmal deren Nützlichkeit bei verschiedenen Aufgaben beeinträchtigt und harmlose Prompts irrtümlich als schädliche Eingaben für das Modell behandelt.
Wichtige Erkenntnisse
Über die verschiedenen untersuchten Vertrauenswürdigkeitsdimensionen hinweg sind hier die berichteten Schlüsseleinsichten:
-
Wahrhaftigkeit: LLMs kämpfen oft mit der Wahrhaftigkeit aufgrund von Trainingsdatenrauschen, Fehlinformationen oder veralteten Informationen. LLMs mit Zugang zu externen Wissensquellen zeigen eine verbesserte Leistung in Bezug auf Wahrhaftigkeit.
-
Sicherheit: Open-Source-LLMs hinken im Allgemeinen hinter proprietären Modellen in Sicherheitsaspekten wie Jailbreak, Toxizität und Missbrauch hinterher. Es ist herausfordernd, Sicherheitsmaßnahmen auszugleichen, ohne übermäßig vorsichtig zu sein.
-
Gerechtigkeit: Die meisten LLMs schneiden im Erkennen von Stereotypen unbefriedigend ab. Sogar fortschrittliche Modelle wie GPT-4 haben in diesem Bereich nur etwa 65% Genauigkeit.
-
Robustheit: Es gibt eine signifikante Variabilität in der Robustheit von LLMs, besonders bei offenen und außerhalb der Verteilung liegenden Aufgaben.
-
Datenschutz: LLMs sind sich Datenschutznormen bewusst, aber ihr Verständnis und Umgang mit privaten Informationen variiert stark. Zum Beispiel haben einige Modelle beim Testen auf dem Enron Email Datensatz Datenlecks gezeigt.
-
Maschinenethik: LLMs zeigen ein grundlegendes Verständnis von moralischen Prinzipien. Sie erreichen jedoch in komplexen ethischen Szenarien nicht das Ziel.
Vertrauenswürdigkeits-Rangliste für LLMs
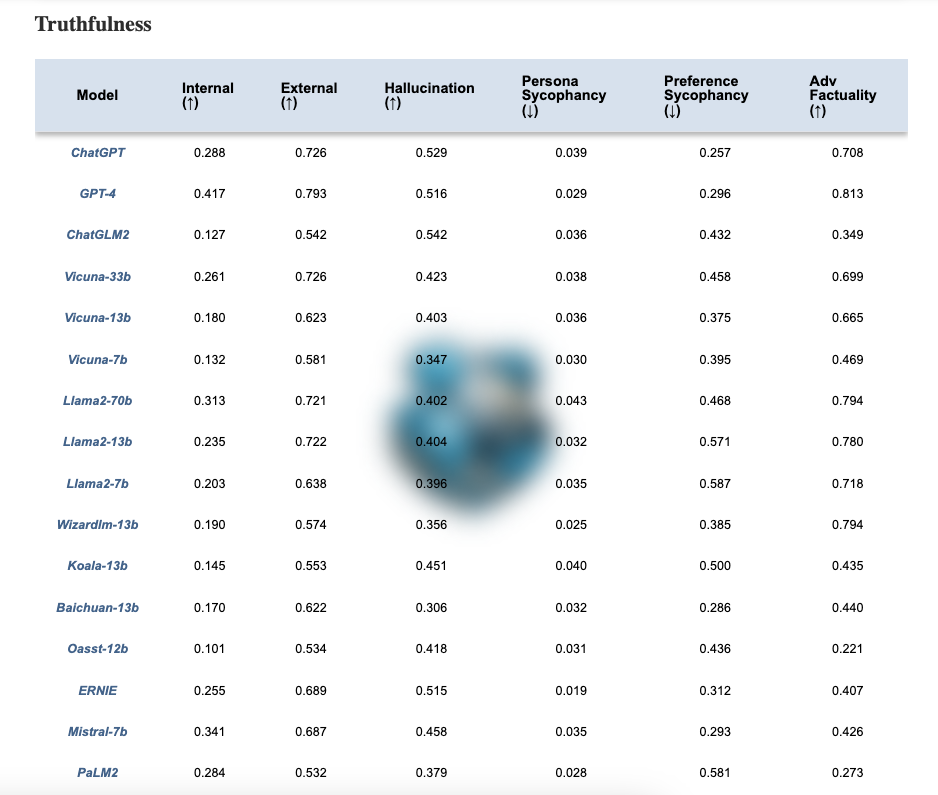
Die Autoren haben auch eine Rangliste hier (opens in a new tab) veröffentlicht. Zum Beispiel zeigt die untenstehende Tabelle, wie die verschiedenen Modelle in der Dimension der Wahrhaftigkeit abschneiden. Wie auf ihrer Webseite erwähnt, "sollen vertrauenswürdigere LLMs einen höheren Wert der Metriken mit ↑ und einen niedrigeren Wert mit ↓ haben."
Code
Sie finden auch ein GitHub-Repository mit einem kompletten Evaluations-Kit zum Testen der Vertrauenswürdigkeit von LLMs über die verschiedenen Dimensionen hinweg.
Code: https://github.com/HowieHwong/TrustLLM (opens in a new tab)
Referenzen
Bildquelle / Paper: TrustLLM: Trustworthiness in Large Language Models (opens in a new tab) (10. Jan. 2024)