Skalierung von anleitungsfeinabgestimmten Sprachmodellen
Was ist neu?
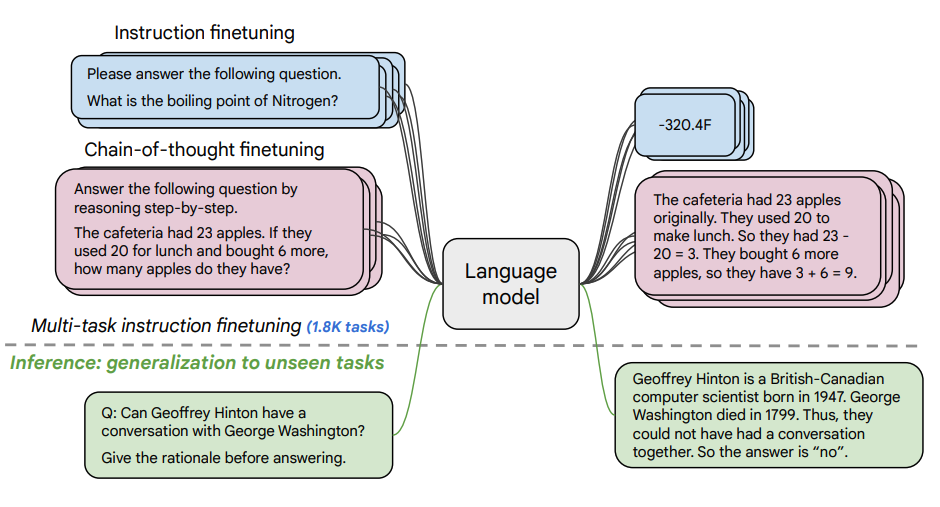
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Dieser Artikel untersucht die Vorteile des Skalierens von instruction finetuning (opens in a new tab) und wie es die Leistung einer Vielzahl von Modellen (PaLM, T5), Prompting-Setups (Zero-Shot, Few-Shot, CoT) und Benchmarks (MMLU, TyDiQA) verbessert. Dies wird anhand folgender Aspekte erforscht: Skalierung der Anzahl von Aufgaben (1,8K Aufgaben), Skalierung der Größe des Modells sowie Feinabstimmung auf Chain-of-Thought-Daten (9 Datensätze verwendet).
Feinabstimmungsverfahren:
- 1,8K Aufgaben wurden als Anleitungen formuliert und zum Feinabstimmen des Modells verwendet
- Verwendet sowohl mit als auch ohne Exemplare und mit bzw. ohne Chain of Thought (CoT)
Feinabstimmungsaufgaben und zurückgehaltene Aufgaben unten dargestellt:
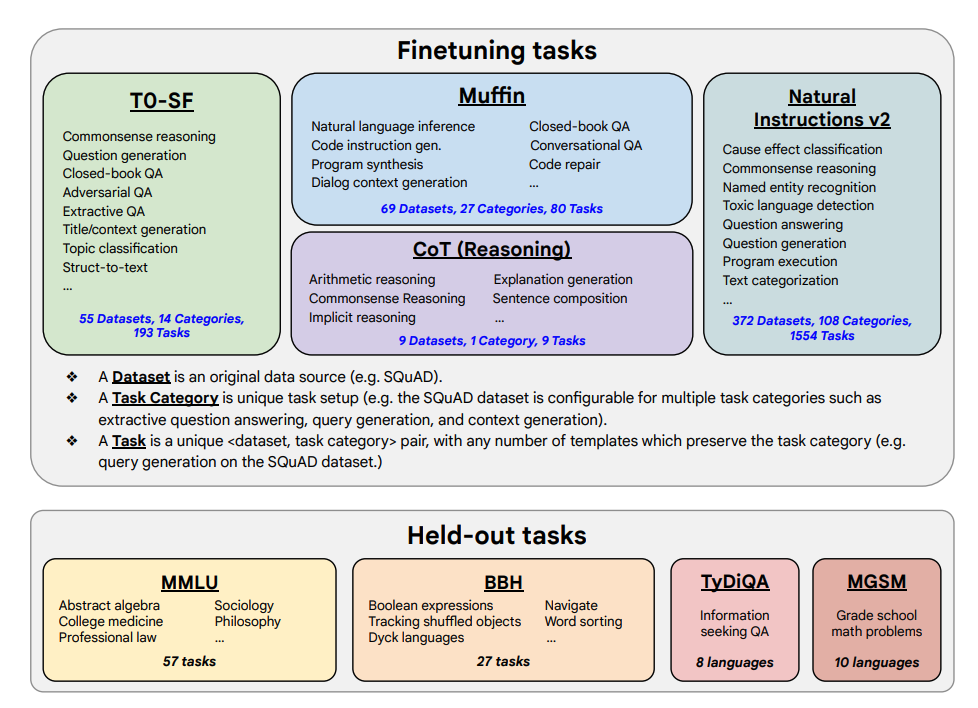
Fähigkeiten & Hauptergebnisse
- Anleitungsfeinabstimmung (instruction finetuning) skaliert gut mit der Anzahl von Aufgaben und der Größe des Modells; dies legt die Notwendigkeit nahe, die Anzahl der Aufgaben und die Größe des Modells weiter zu skalieren
- Das Hinzufügen von CoT-Datensätzen in die Feinabstimmung ermöglicht gute Leistung bei Aufgaben, die schlussfolgerndes Denken erfordern
- Flan-PaLM hat verbesserte multilinguale Fähigkeiten; 14,9% Verbesserung bei One-Shot TyDiQA; 8,1% Verbesserung bei arithmetischem Schlussfolgern in unterrepräsentierten Sprachen
- Plan-PaLM zeigt auch gute Leistungen bei Fragen zur offenen Textgenerierung, was ein guter Indikator für verbesserte Benutzbarkeit ist
- Verbessert die Leistung über verantwortungsbewusste KI (RAI)-Benchmarks hinweg
- Mit Anleitungen feinabgestimmte Flan-T5-Modelle demonstrieren starke Few-Shot-Fähigkeiten und übertreffen öffentliche Checkpoints wie T5
Die Ergebnisse beim Skalieren der Anzahl von Feinabstimmungsaufgaben und der Modellgröße: Es wird erwartet, dass weitere Skalierungen sowohl der Größe des Modells als auch der Anzahl der Feinabstimmungsaufgaben die Leistung weiter verbessern, obwohl die Skalierung der Anzahl der Aufgaben abnehmende Erträge hat.
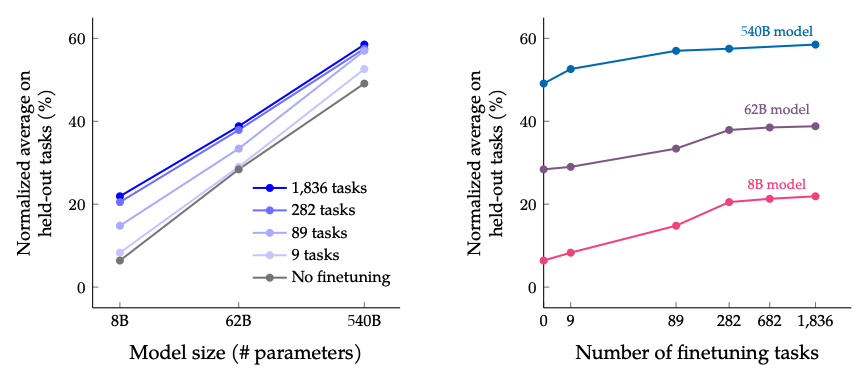
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Die Ergebnisse beim Feinabstimmen mit nicht-CoT und CoT-Daten: Die gemeinsame Feinabstimmung auf nicht-CoT und CoT-Daten verbessert die Leistung bei beiden Bewertungen im Vergleich zur Feinabstimmung auf nur eine von beiden.
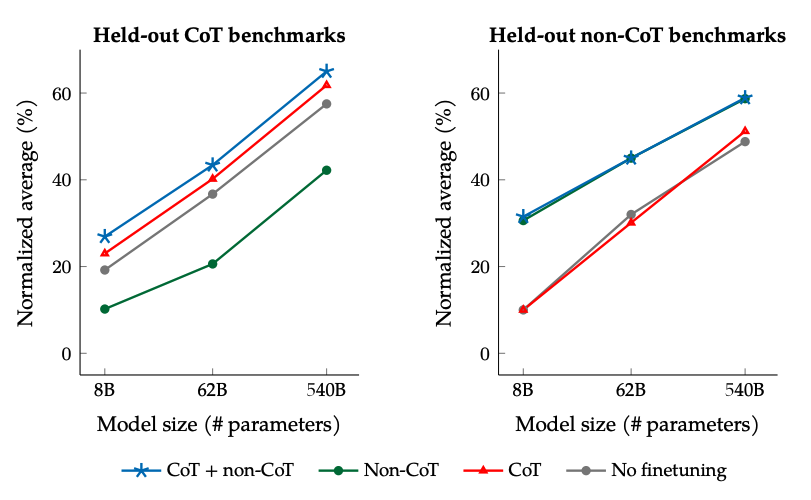
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Außerdem erreicht Selbstkonsistenz in Kombination mit CoT State-of-the-Art-Ergebnisse bei mehreren Benchmarks. CoT + Selbstkonsistenz verbessert auch signifikant die Ergebnisse bei Benchmarks, die Matheprobleme beinhalten (z.B. MGSM, GSM8K).
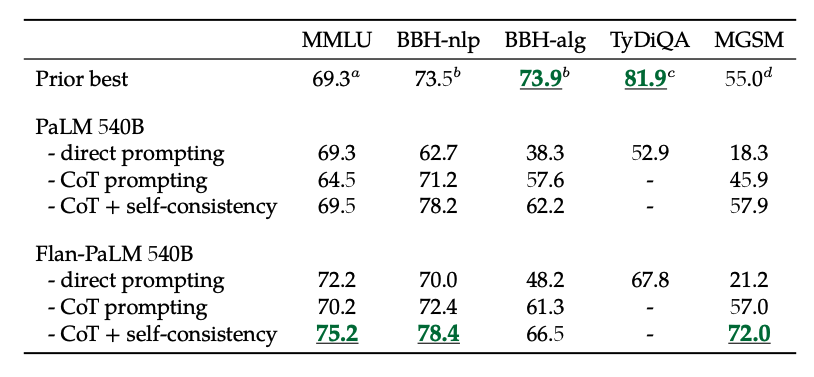
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoT-Feinabstimmung ermöglicht Zero-Shot-Schlussfolgerung, ausgelöst durch die Phrase "denken wir Schritt für Schritt", bei BIG-Bench-Aufgaben. Im Allgemeinen übertrifft Zero-Shot CoT Flan-PaLM Zero-Shot CoT PaLM ohne Feinabstimmung.
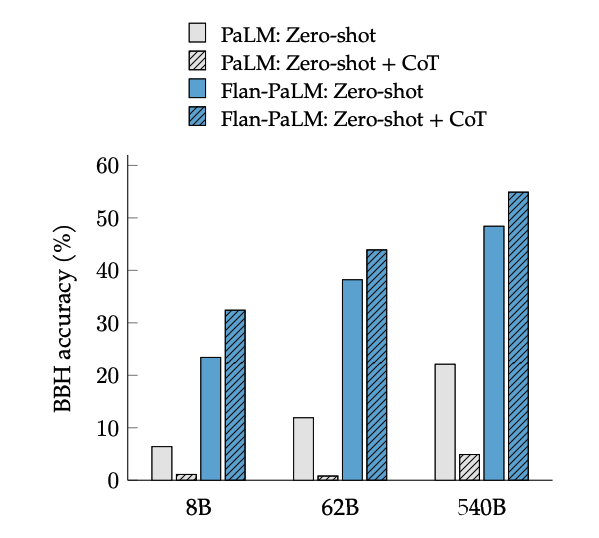
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Unten sind einige Demonstrationen von Zero-Shot CoT für PaLM und Flan-PaLM bei ungesehenen Aufgaben aufgeführt.
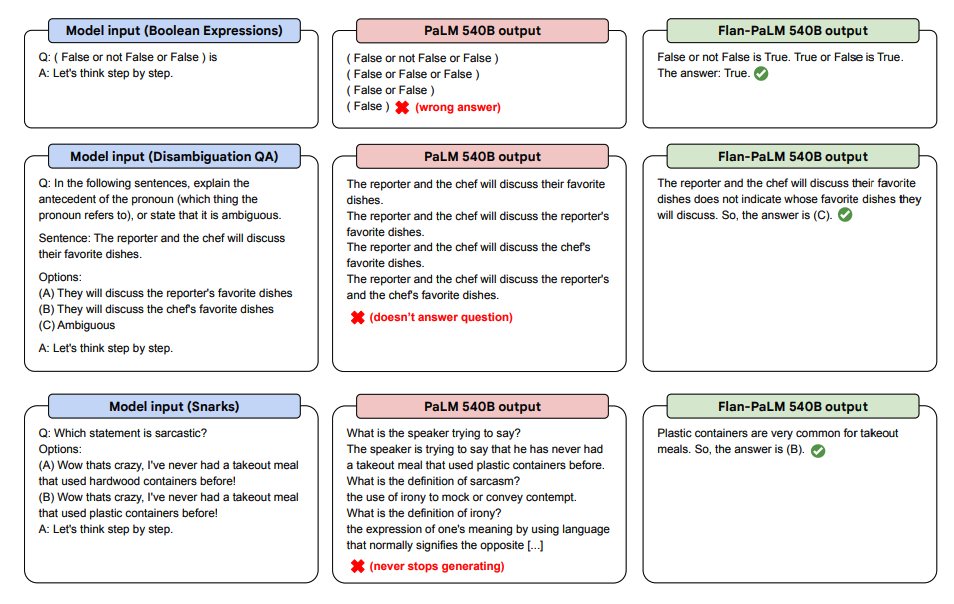
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Weiter unten finden Sie mehr Beispiele für Zero-Shot Prompting. Es zeigt, wie das PaLM-Modell Schwierigkeiten mit Wiederholungen hat und in der Zero-Shot-Einstellung nicht auf Anleitungen antwortet, während das Flan-PaLM gut abschneidet. Few-Shot-Exemplare können diese Fehler abschwächen.
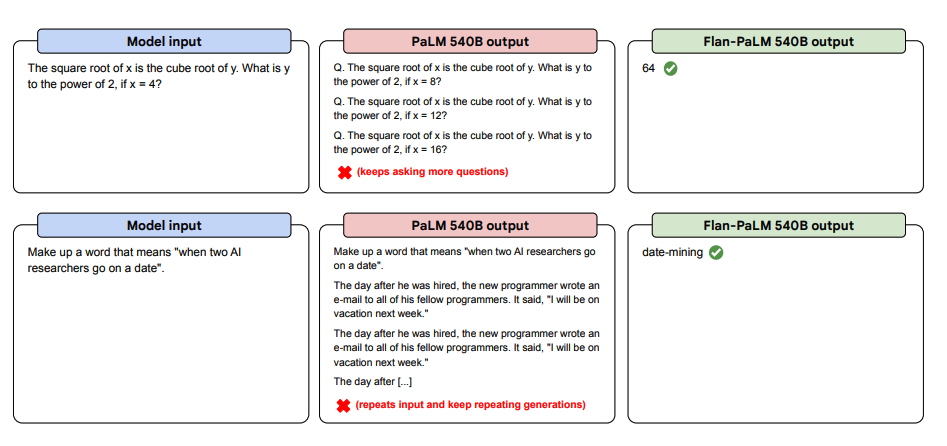
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Hier sind einige Beispiele, die weitere Zero-Shot-Fähigkeiten des Flan-PALM-Modells bei verschiedenen Arten von herausfordernden offenen Fragen demonstrieren:
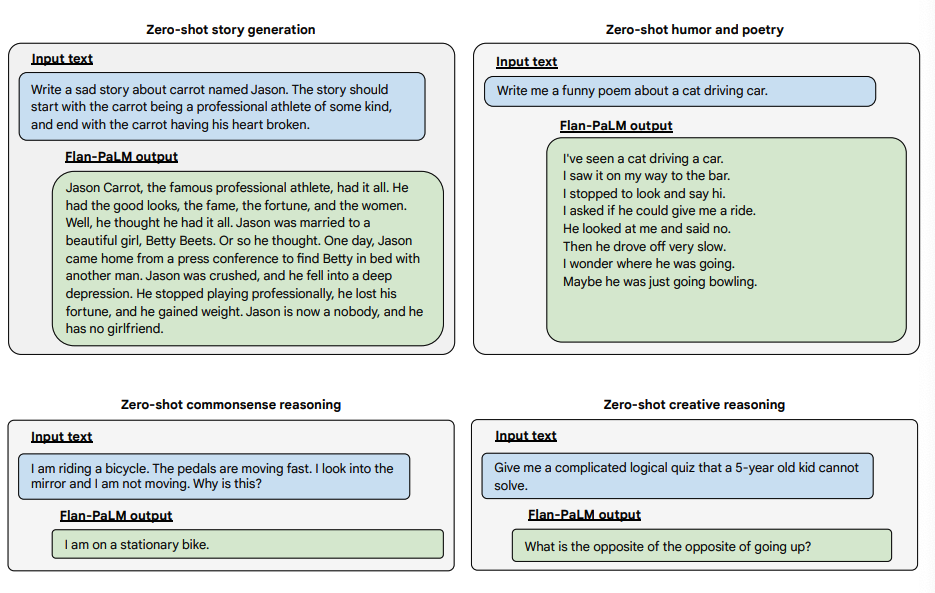
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
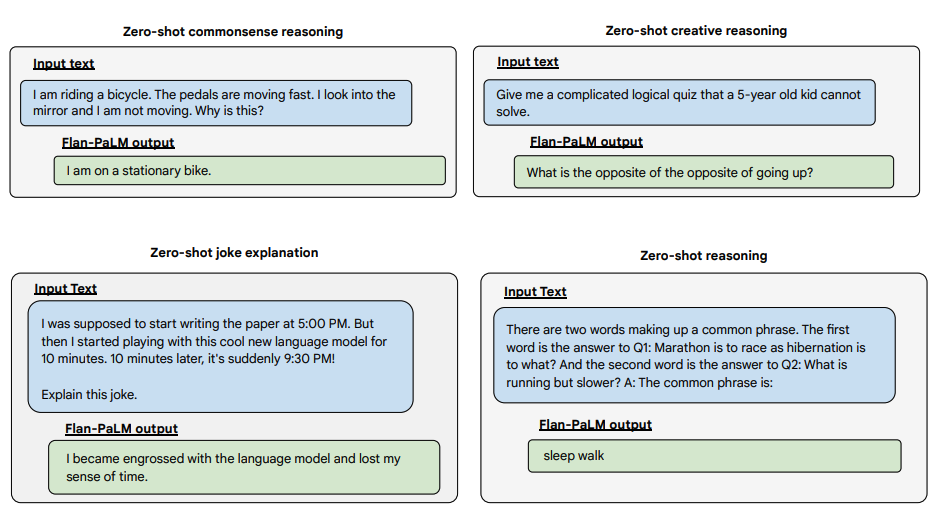
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
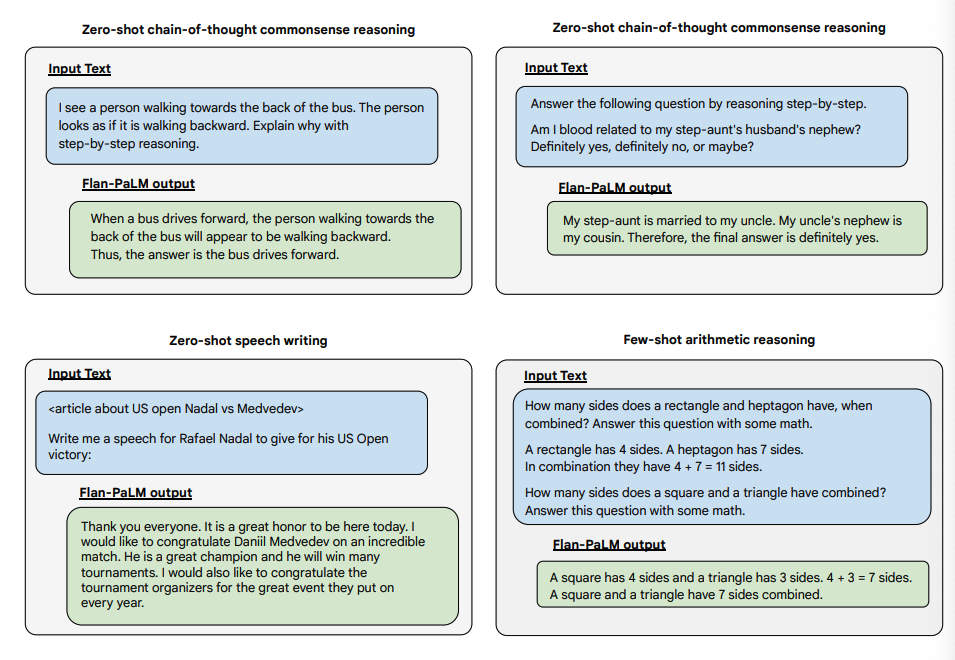
Bildquelle: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Sie können Flan-T5-Modelle auf dem Hugging Face Hub (opens in a new tab) ausprobieren.