ReAct Prompting
Yao et al., 2022 (opens in a new tab) stellten ein Framework namens ReAct vor, bei dem LLMs zur Erzeugung von Reasoning Traces (Denkpfaden) und task-spezifischen Aktionen in einer verzahnten Weise verwendet werden.
Das Erzeugen von Reasoning Traces ermöglicht es dem Modell, Handlungspläne zu induzieren, zu verfolgen, zu aktualisieren und sogar Ausnahmen zu behandeln. Der Aktionsschritt ermöglicht es, Schnittstellen mit externen Quellen, wie Wissensdatenbanken oder Umgebungen, zu nutzen und Informationen von dort zu sammeln.
Das ReAct Framework kann es LLMs ermöglichen, mit externen Werkzeugen zu interagieren, um zusätzliche Informationen abzurufen, die zu verlässlicheren und faktischeren Antworten führen.
Die Ergebnisse zeigen, dass ReAct mehrere State-of-the-Art-Benchmarks bei Sprach- und Entscheidungsfindungsaufgaben übertreffen kann. ReAct führt auch zu verbesserter menschlicher Interpretierbarkeit und Vertrauenswürdigkeit von LLMs. Insgesamt stellten die Autoren fest, dass der beste Ansatz ReAct in Verbindung mit Chain-of-Thought (CoT) verwendet, was die Nutzung von sowohl internem Wissen als auch während des Reasonings erhaltenen externen Informationen ermöglicht.
Wie funktioniert es?
ReAct ist inspiriert von den Synergien zwischen "Handeln" und "Denken", welche es Menschen ermöglichen, neue Aufgaben zu lernen und Entscheidungen oder Schlussfolgerungen zu treffen.
Chain-of-Thought (CoT) Prompting hat die Fähigkeiten von LLMs gezeigt, Reasoning Traces für die Beantwortung von Fragen bezüglich Arithmetik und Common-Sense-Reasoning zu erzeugen, unter anderem bei verschiedenen Aufgaben (Wei et al., 2022) (opens in a new tab). Aber das Fehlen des Zugriffs auf die externe Welt oder die Unfähigkeit, sein Wissen zu aktualisieren, kann zu Problemen wie Faktenhalluzination und Fehlerfortpflanzung führen.
ReAct ist ein allgemeines Paradigma, das Reasoning und Handeln mit LLMs kombiniert. ReAct fordert LLMs dazu auf, verbale Reasoning Traces und Aktionen für eine Aufgabe zu generieren. Dies ermöglicht es dem System, dynamisches Reasoning durchzuführen, um Pläne für Handlungen zu gestalten, zu pflegen und anzupassen, und ermöglicht es gleichzeitig, mit externen Umgebungen (z.B. Wikipedia) zu interagieren, um zusätzliche Informationen in das Reasoning zu integrieren. Die untenstehende Abbildung zeigt ein Beispiel von ReAct und den verschiedenen Schritten, die zur Beantwortung einer Frage notwendig sind.

Bildquelle: Yao et al., 2022 (opens in a new tab)
Im obigen Beispiel geben wir ein Prompt wie die folgende Frage von HotpotQA (opens in a new tab) ein:
Abgesehen von der Apple Remote, welche anderen Geräte können das Programm steuern, für das die Apple Remote ursprünglich entwickelt wurde?Beachten Sie, dass im Kontext stehende Beispiele ebenfalls zum Prompt hinzugefügt werden, aber wir lassen diese hier zur Vereinfachung weg. Wir können sehen, dass das Modell task-solving trajectories (Denk-, Handlungsschritte) generiert (Thought, Act). In der Abbildung entspricht Obs der Beobachtung aus der Umgebung, mit der interagiert wird (z.B. Suchmaschine). Im Wesentlichen kann ReAct Informationen abrufen, um das Reasoning zu unterstützen, während das Reasoning dabei hilft, zu zielgerichtet zu bestimmen, was als Nächstes abgerufen werden soll.
ReAct Prompting
Um zu demonstrieren, wie ReAct Prompting funktioniert, folgen wir einem Beispiel aus dem Artikel.
Der erste Schritt besteht darin, Fälle aus einem Trainingsset (z.B. HotpotQA) auszuwählen und ReAct-Format-Trajektorien zu komponieren. Diese werden als Few-Shot-Beispiele in den Prompts verwendet. Die Trajektorien bestehen aus mehreren Denk-, Handlungs-, Beobachtungsschritten, wie in der obigen Abbildung dargestellt. Die freien Gedanken dienen dazu, verschiedene Aufgaben zu erfüllen, wie beispielsweise Fragen zu zerlegen, Informationen zu extrahieren, Commonsense- / Arithmetik-Reasoning durchzuführen, die Formulierung von Suchanfragen zu leiten und die endgültige Antwort zu synthetisieren.
Hier ist ein Beispiel, wie die ReAct Prompt-Beispiele aussehen (aus dem Papier entnommen und zur Vereinfachung auf ein Beispiel verkürzt):
Frage Welcher Höhenbereich gilt für das Gebiet, in das der östliche Sektor der
Colorado-Orogenese übergeht?
Gedanke 1 Ich muss nach Colorado-Orogenese suchen, den Bereich finden, in den der östliche Sektor
der Colorado-Orogenese übergeht, und dann den Höhenbereich des
Gebiets finden.
Aktion 1 Suche [Colorado-Orogenese]
Beobachtung 1 Die Colorado-Orogenese war eine Episode der Gebirgsbildung (eine Orogenese) in
Colorado und umliegenden Gebieten.
Gedanke 2 Es wird nicht der östliche Sektor erwähnt. Also muss ich nach östlichem
Sektor suchen.
Aktion 2 Nachschlagen [östlicher Sektor]
Beobachtung 2 (Ergebnis 1 / 1) Der östliche Sektor erstreckt sich in die High Plains und wird
Zentralen Ebenen-Orogenese genannt.
Gedanke 3 Der östliche Sektor der Colorado-Orogenese erstreckt sich in die High Plains. Also muss
ich nach High Plains suchen und deren Höhenbereich finden.
Aktion 3 Suche [High Plains]
Beobachtung 3 High Plains bezieht sich auf eine von zwei unterschiedlichen Landregionen
Gedanke 4 Ich muss stattdessen nach High Plains (Vereinigte Staaten) suchen.
Aktion 4 Suche [High Plains (Vereinigte Staaten)]
Beobachtung 4 Die High Plains sind eine Unterregion der Great Plains. Von Ost nach West steigen die
High Plains in der Höhe von etwa 1.800 bis 7.000 ft (550 bis 2.130
m).[3]
Gedanke 5 High Plains steigen in der Höhe von etwa 1.800 bis 7.000 ft, also ist die Antwort
1.800 bis 7.000 ft.
Aktion 5 Beenden [1.800 bis 7.000 ft]
...Beachten Sie, dass unterschiedliche Prompteinstellungen für verschiedene Aufgabentypen verwendet werden. Für Aufgaben, bei denen Reasoning von primärer Bedeutung ist (z.B. HotpotQA), werden mehrere Denk-, Handlungs-, Beobachtungsschritte für die task-solving trajectory verwendet. Für Entscheidungsaufgaben, die viele Handlungsschritte erfordern, werden Gedanken sparsam eingesetzt.
Ergebnisse bei wissensintensiven Aufgaben
Zunächst evaluiert das Papier ReAct bei wissensintensiven Reasoning-Aufgaben wie Fragen beantworten (HotpotQA) und Faktenüberprüfung (Fever (opens in a new tab)). PaLM-540B wird als Basismodell für das Prompting verwendet.
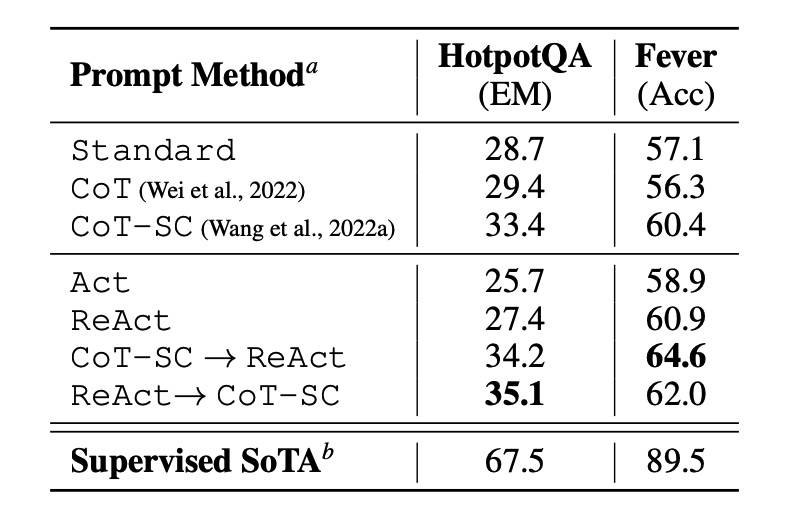
Bildquelle: Yao et al., 2022 (opens in a new tab)
Die Prompting-Ergebnisse bei HotPotQA und Fever unter Verwendung verschiedener Prompting-Methoden zeigen, dass ReAct im Allgemeinen besser abschneidet als Act (beinhaltet nur Handeln) bei beiden Aufgaben.
Wir können auch beobachten, dass ReAct CoT bei Fever übertrifft und hinter CoT bei HotpotQA zurückbleibt. Eine detaillierte Fehleranalyse wird im Artikel bereitgestellt. Zusammengefasst:
- CoT leidet unter Faktenhalluzination
- Die strukturelle Beschränkung von ReAct reduziert seine Flexibilität bei der Formulierung von Reasoning-Schritten
- ReAct hängt stark von den Informationen ab, die es abruft; nicht informative Suchergebnisse entgleisen das Reasoning des Modells und führen zu Schwierigkeiten bei der Erholung und Neufassung von Gedanken
Prompting-Methoden, die ReAct und CoT+Self-Consistency kombinieren und unterstützen, schneiden im Allgemeinen besser ab als alle anderen Prompting-Methoden.
Ergebnisse bei Entscheidungsaufgaben
Das Papier berichtet auch über Ergebnisse, die die Leistung von ReAct bei Entscheidungsaufgaben demonstrieren. ReAct wird auf zwei Benchmarks namens ALFWorld (opens in a new tab) (textbasiertes Spiel) und WebShop (opens in a new tab) (Online-Shopping-Website-Umgebung) evaluiert. Beide beinhalten komplexe Umgebungen, die effektives Reasoning zum Handeln und Erkunden erforderlich machen.
Beachten Sie, dass die ReAct-Prompts für diese Aufgaben anders gestaltet sind, aber immer noch die gleiche Kernidee des Kombinierens von Reasoning und Handeln beibehalten. Unten finden Sie ein Beispiel für ein ALFWorld-Problem, bei dem ReAct Prompting verwendet wird.
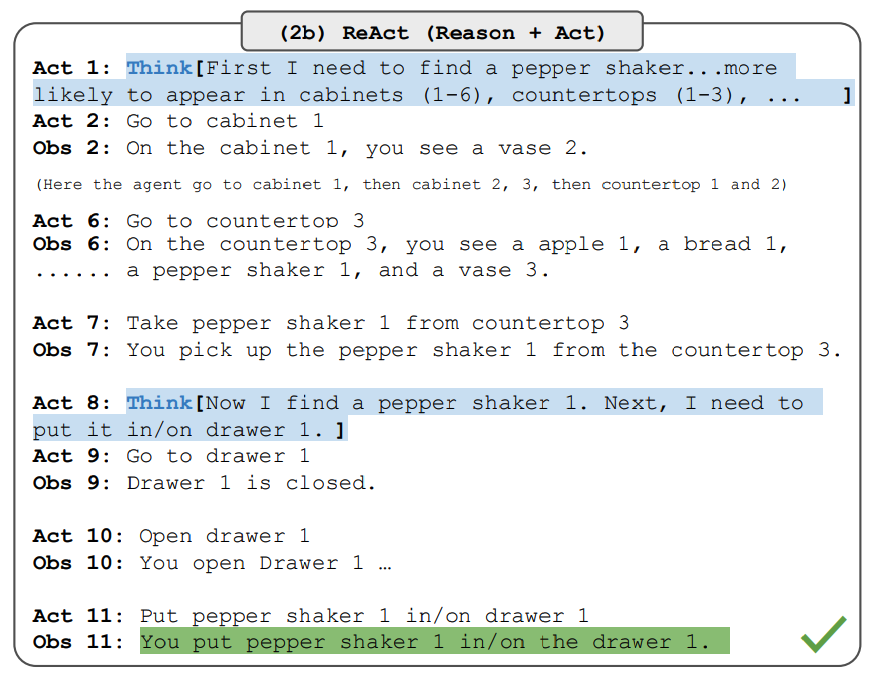
Bildquelle: Yao et al., 2022 (opens in a new tab)
ReAct übertrifft Act sowohl bei ALFWorld als auch bei Webshop. Act, ohne Gedanken, scheitert daran, Ziele korrekt in Teilziele zu zerlegen. Reasoning scheint bei diesen Aufgabenarten in ReAct von Vorteil zu sein, aber aktuelle Prompting-basierte Methoden sind immer noch weit von der Leistung von Expertenmenschen bei diesen Aufgaben entfernt.
Schauen Sie sich den Artikel für detailliertere Ergebnisse an.
LangChain ReAct Verwendung
Unten finden Sie ein hochstufiges Beispiel dafür, wie das ReAct Prompting in der Praxis funktioniert. Wir werden OpenAI für das LLM und LangChain (opens in a new tab) verwenden, da es bereits eingebaute Funktionen hat, die das ReAct-Framework nutzen, um Agenten zu bauen, die Aufgaben erledigen, indem sie die Kraft von LLMs und verschiedenen Tools kombinieren.
Zuerst installieren und importieren wir die notwendigen Bibliotheken:
%%capture
# aktualisieren oder installieren Sie die notwendigen Bibliotheken
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# importiere Bibliotheken
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# lade API-Schlüssel; Sie müssen diese erhalten, wenn Sie sie noch nicht haben
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Nun können wir das LLM, die Tools, die wir verwenden werden, und den Agenten konfigurieren, der es uns ermöglicht, das ReAct-Framework zusammen mit dem LLM und den Tools zu nutzen. Beachten Sie, dass wir eine Such-API für das Suchen externer Informationen und LLM als Mathematik-Tool verwenden.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)Ist das konfiguriert, können wir nun den Agenten mit der gewünschten Anfrage/Dem gewünschten Prompt ausführen. Beachten Sie, dass hier keine Few-Shot-Beispiele bereitgestellt werden müssen, wie im Artikel erklärt.
agent.run("Wer ist Olivia Wildes Freund? Wie ist die Potenz mit dem Wert 0,23 seines aktuellen Alters?")Die Chain-Ausführung sieht wie folgt aus:
> Betreten einer neuen AgentExecutor-Kette...
Ich muss herausfinden, wer Olivia Wildes Freund ist und dann sein Alter mit der Potenz des Werts 0,23 berechnen.
Aktion: Suchen
Aktionseingabe: "Olivia Wilde Freund"
Beobachtung: Olivia Wilde begann eine Beziehung mit Harry Styles, nachdem sie ihre langjährige Verlobung mit Jason Sudeikis beendet hatte — siehe ihre Beziehungsgeschichte.
Gedanke: Ich muss Harry Styles' Alter herausfinden.
Aktion: Suchen
Aktionseingabe: "Harry Styles Alter"
Beobachtung: 29 Jahre
Gedanke: Ich muss 29 hoch 0,23 berechnen.
Aktion: Rechner
Aktionseingabe: 29^0,23
Beobachtung: Antwort: 2,169459462491557
Gedanke: Ich kenne jetzt die endgültige Antwort.
Endantwort: Harry Styles, der Freund von Olivia Wilde, ist 29 Jahre alt und sein Alter hoch 0,23 ist 2,169459462491557.
> Kette beendet.Das Ausgabeergebnis ist wie folgt:
"Harry Styles, der Freund von Olivia Wilde, ist 29 Jahre alt und sein Alter hoch 0,23 ist 2,169459462491557."Wir haben das Beispiel aus der LangChain-Dokumentation (opens in a new tab) angepasst; also gebührt ihnen die Anerkennung. Wir ermutigen den Lernenden, verschiedene Kombinationen von Tools und Aufgaben zu erkunden.
Das Notebook für diesen Code finden Sie hier: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb (opens in a new tab)