Retrieval Augmented Generation (RAG)
Allgemeine Sprachmodelle können feinabgestimmt werden, um mehrere gängige Aufgaben wie Sentiment-Analyse und Erkennung von Entitäten zu realisieren. Diese Aufgaben erfordern in der Regel kein zusätzliches Hintergrundwissen.
Für komplexere und wissensintensive Aufgaben ist es möglich, ein auf Sprachmodellen basierendes System zu entwickeln, das Zugang zu externen Wissensquellen hat, um Aufgaben zu vervollständigen. Dies ermöglicht eine höhere faktische Konsistenz, verbessert die Zuverlässigkeit generierter Antworten und hilft, das Problem der "Halluzination" abzumildern.
Meta AI-Forscher haben eine Methode namens Retrieval Augmented Generation (RAG) (opens in a new tab) eingeführt, um solche wissensintensiven Aufgaben anzugehen. RAG kombiniert eine Informationsabrufkomponente mit einem Textgenerator-Modell. RAG kann feinabgestimmt und sein internes Wissen kann auf effiziente Weise und ohne Neutraining des gesamten Modells geändert werden.
RAG nimmt eine Eingabe und holt eine Menge relevanter/unterstützender Dokumente von einer Quelle (z.B. Wikipedia) ab. Die Dokumente werden als Kontext mit dem ursprünglichen Eingabe-Prompt zusammengefügt und an den Textgenerator übergeben, der den endgültigen Ausgangstext produziert. Dies macht RAG anpassungsfähig für Situationen, in denen sich Fakten im Laufe der Zeit entwickeln könnten. Dies ist sehr nützlich, da das parametrische Wissen der LLMs statisch ist. RAG ermöglicht es Sprachmodellen, ein Neutraining zu umgehen und über eine abrufbasierte Generation Zugang zu den neuesten Informationen zu erhalten, um verlässliche Ausgaben zu generieren.
Lewis et al., (2021) schlugen ein allgemeines Feinabstimmungsrezept für RAG vor. Ein vortrainiertes seq2seq-Modell wird als parametrisches Gedächtnis verwendet und ein dichter Vektorindex von Wikipedia dient als nicht-parametrisches Gedächtnis (zugänglich über einen neuronal vortrainierten Abfrager). Unten ist eine Übersicht, wie der Ansatz funktioniert:
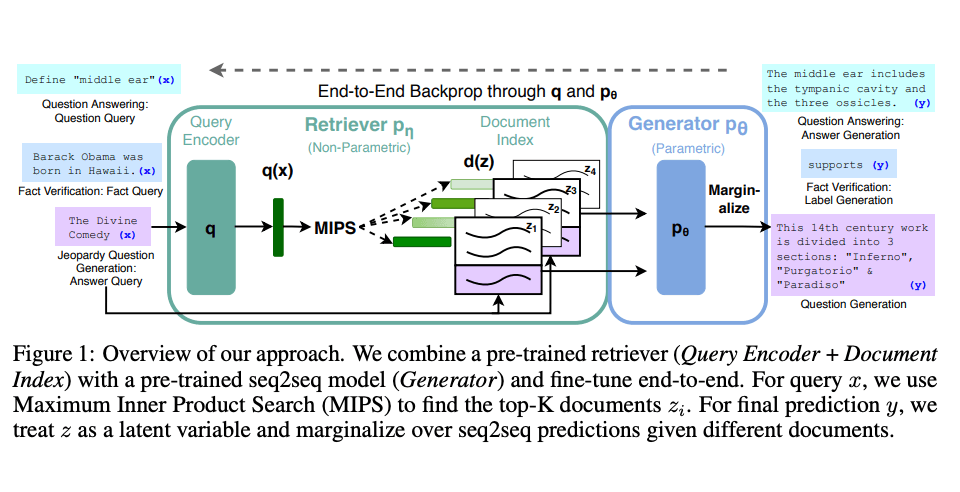
Bildquelle: Lewis et el. (2021) (opens in a new tab)
RAG zeigt starke Leistung auf mehreren Benchmarks wie Natural Questions (opens in a new tab), WebQuestions (opens in a new tab) und CuratedTrec. RAG generiert Antworten, die faktischer, spezifischer und vielfältiger sind, wenn sie auf MS-MARCO- und Jeopardy-Fragen getestet werden. RAG verbessert auch die Ergebnisse bei der Faktenüberprüfung von FEVER.
Dies zeigt das Potenzial von RAG als eine praktikable Option, um die Ausgaben von Sprachmodellen bei wissensintensiven Aufgaben zu verbessern.
In jüngerer Zeit haben sich diese abrufbasierten Ansätze vergrößert und werden mit populären LLMs wie ChatGPT kombiniert, um die Fähigkeiten und die faktische Konsistenz zu verbessern.
Ein einfaches Beispiel für die Verwendung von Abrufsystemen und LLMs zur Beantwortung von Fragen mit Quellen (opens in a new tab) finden Sie in der LangChain-Dokumentation.