Mixtral
In diesem Leitfaden bieten wir einen Überblick über das Mixtral 8x7B-Modell, einschließlich Prompts und Verwendungsbeispielen. Der Leitfaden umfasst auch Tipps, Anwendungen, Einschränkungen, wissenschaftliche Arbeiten und zusätzliche Lektürematerialien bezüglich Mixtral 8x7B.
Einführung in Mixtral (Mixtral of Experts)
Mixtral 8x7B ist ein Sparse Mixture of Experts (SMoE) Sprachmodell, veröffentlicht von Mistral AI (opens in a new tab). Mixtral hat eine ähnliche Architektur wie Mistral 7B (opens in a new tab), der Hauptunterschied besteht jedoch darin, dass jede Schicht in Mixtral 8x7B aus 8 Feedforward-Blöcken (d.h. Experten) besteht. Mixtral ist ein Decoder-only-Modell, bei dem für jedes Token, in jeder Schicht, ein Router-Netzwerk zwei Experten (d.h. 2 Gruppen aus 8 unterschiedlichen Gruppen von Parametern) auswählt, um das Token zu verarbeiten und deren Ausgaben additiv zu kombinieren. Anders ausgedrückt, der Ausgang des gesamten MoE-Moduls für einen gegebenen Eingabewert wird durch die gewichtete Summe der Ausgaben erzeugt, die von den Expertennetzwerken produziert werden.
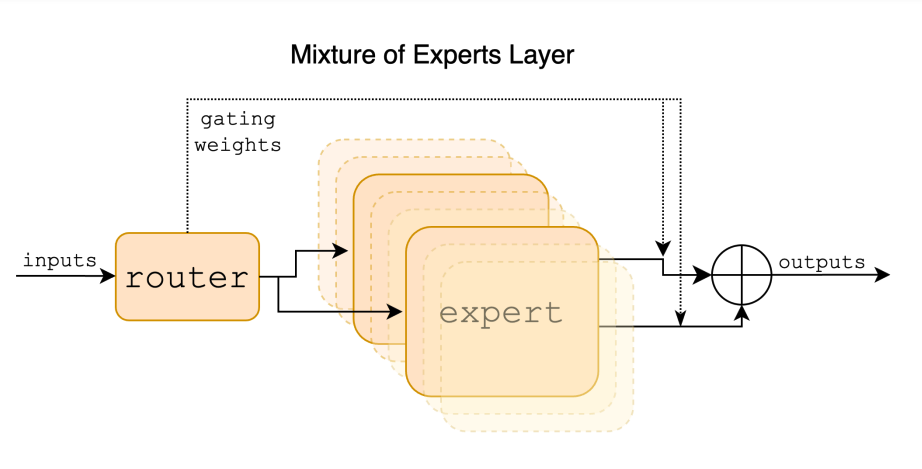
Da Mixtral ein SMoE ist, verfügt es über insgesamt 47B Parameter, verwendet jedoch nur 13B pro Token während der Inferenz. Die Vorteile dieses Ansatzes umfassen eine bessere Kontrolle über Kosten und Latenz, da es nur einen Bruchteil der gesamten Parametermenge pro Token verwendet. Mixtral wurde mit offenen Webdaten und einer Kontextgröße von 32 Tokens trainiert. Berichten zufolge übertrifft Mixtral Llama 2 80B mit 6x schnellerer Inferenz und erreicht oder übertrifft GPT-3.5 (opens in a new tab) in mehreren Benchmarks.
Die Mixtral-Modelle sind unter Apache 2.0 lizenziert (opens in a new tab).
Leistung und Fähigkeiten von Mixtral
Mixtral demonstriert starke Fähigkeiten in mathematischen Schlussfolgerungen, der Codegenerierung und bei mehrsprachigen Aufgaben. Es kann Sprachen wie Englisch, Französisch, Italienisch, Deutsch und Spanisch verarbeiten. Mistral AI hat ebenfalls ein Mixtral 8x7B Instruct-Modell veröffentlicht, das GPT-3.5 Turbo, Claude-2.1, Gemini Pro und Llama 2 70B Modelle in menschlichen Benchmarks übertrifft.
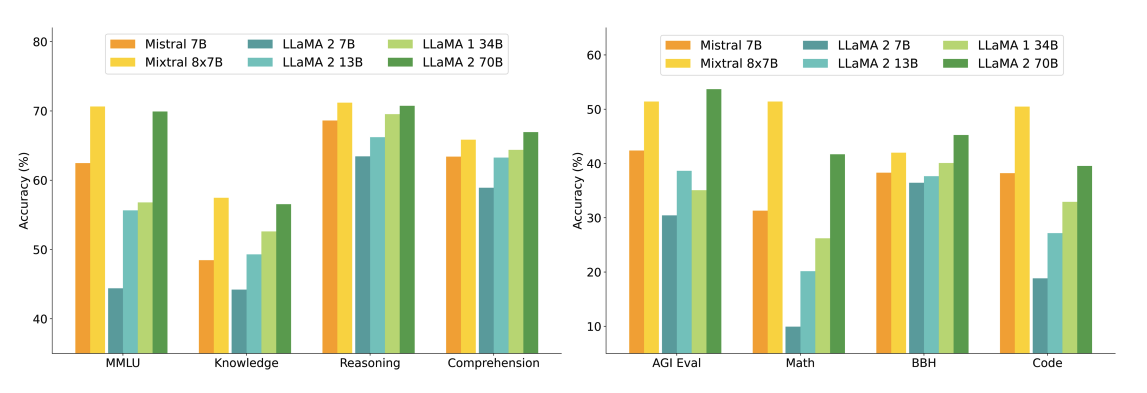
Die folgende Abbildung zeigt den Leistungsvergleich mit verschiedenen Größen von Llama 2-Modellen in einem breiteren Bereich von Fähigkeiten und Benchmarks. Mixtral erreicht oder übertrifft Llama 2 70B und zeigt überlegene Leistung in Mathematik und Codegenerierung.
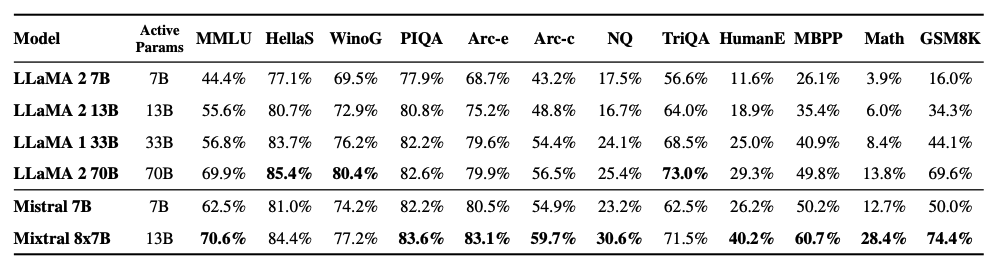
Wie in der folgenden Abbildung zu sehen ist, übertrifft oder erreicht Mixtral 8x7B auch Llama 2-Modelle in verschiedenen beliebten Benchmarks wie MMLU und GSM8K. Es erreicht diese Ergebnisse, während es 5x weniger aktive Parameter während der Inferenz verwendet.
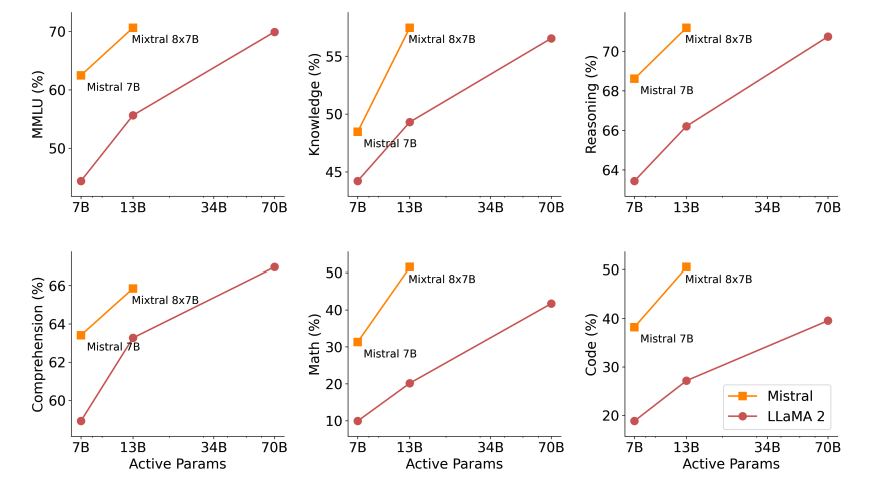
Die folgende Abbildung zeigt den Trade-off zwischen Qualität und Inferenzbudget. Mixtral übertrifft Llama 2 70B in mehreren Benchmarks, während es 5x weniger aktive Parameter verwendet.
Mixtral erreicht oder übertrifft Modelle wie Llama 2 70B und GPT-3.5, wie in der untenstehenden Tabelle gezeigt:
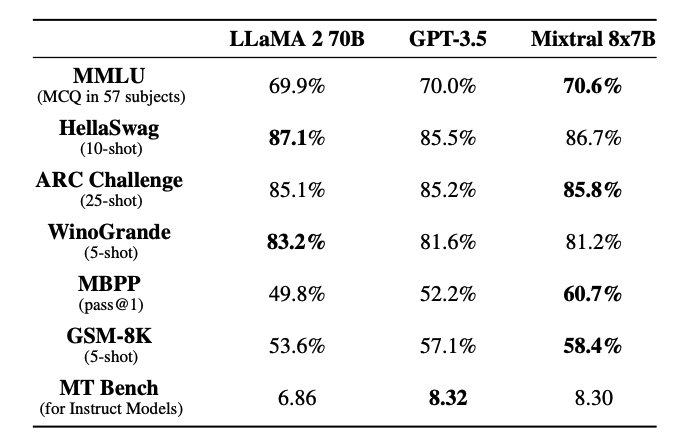
Die untenstehende Tabelle zeigt die Fähigkeiten von Mixtral zum mehrsprachigen Verständnis und wie es mit Llama 2 70B für Sprachen wie Deutsch und Französisch verglichen wird.

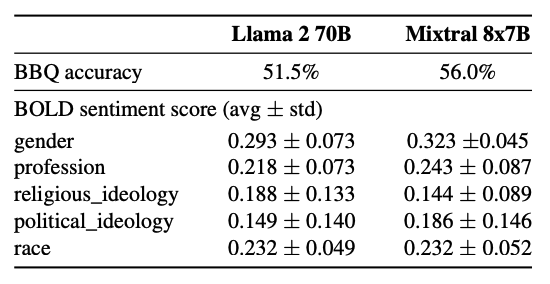
Mixtral zeigt weniger Verzerrung im Bias Benchmark für QA (BBQ) im Vergleich zu Llama 2 (56,0 % vs. 51,5 %).
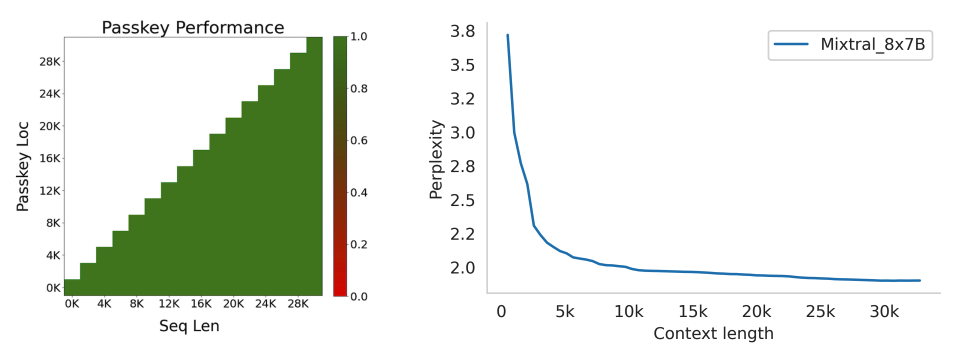
Langstrecken-Informationsabruf mit Mixtral
Mixtral zeigt auch starke Leistung bei der Informationsbeschaffung aus seinem Kontextfenster von 32k Tokens, unabhängig von der Informationslage und der Sequenzlänge.
Um die Fähigkeit von Mixtral im Umgang mit langem Kontext zu messen, wurde es in der Passkey-Retrieval-Aufgabe bewertet. Die Passkey-Aufgabe beinhaltet das zufällige Einfügen eines Passkeys in ein langes Prompt und misst, wie effektiv ein Modell darin ist, diesen zu extrahieren. Mixtral erreicht bei dieser Aufgabe unabhängig von der Lage des Passkeys und der Eingabesequenzlänge eine 100%ige Wiederfindungsrate.
Zudem verringert sich die Perplexität des Modells monoton mit der Vergrößerung des Kontexts, entsprechend einem Subset des Proof-Pile-Dataset (opens in a new tab).
Mixtral 8x7B Instruct
Ein Mixtral 8x7B - Instruct-Modell wird ebenfalls zusammen mit dem Basismodell Mixtral 8x7B veröffentlicht. Dies schließt ein Chat-Modell ein, das durch Supervised Fine Tuning (SFT) und anschließender Direct Preference Optimization (DPO) auf einem Paired-Feedback-Dataset für das Befolgen von Anweisungen feinabgestimmt wurde.
Zum Zeitpunkt der Verfassung dieses Leitfadens (28. Januar 2028) belegt Mixtral den 8. Platz auf der Chatbot Arena Leaderboard (opens in a new tab) (eine unabhängige menschliche Evaluation durchgeführt von LMSys).
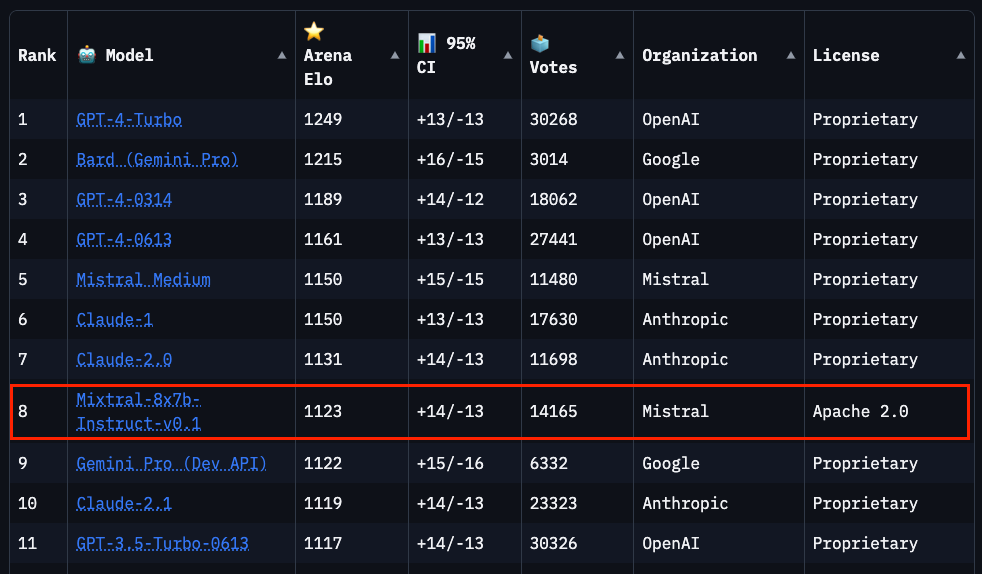
Mixtral-Instruct übertrifft leistungsstarke Modelle wie GPT-3.5 Turbo, Gemini Pro, Claude-2.1 und Llama 2 70B Chat.
Prompt Engineering-Leitfaden für Mixtral 8x7B
Um Mistral 8x7B Instruct effektiv zu prompten und optimale Ausgaben zu erhalten, wird empfohlen, folgende Chat-Vorlage zu verwenden:
<s>[INST] Anweisung [/INST] Modellantwort</s>[INST] Folgeanweisung [/INST]Beachten Sie, dass <s> und </s> spezielle Token für den Beginn der Zeichenfolge (BOS) und das Ende der Zeichenfolge (EOS) sind, während [INST] und [/INST] reguläre Zeichenfolgen sind.
Wir verwenden Mistrals Python-Client (opens in a new tab) für die folgenden Beispiele, die zeigen, wie man das anweisungsgesteuerte Mixtral-Modell Prompten kann. Insbesondere werden wir die Mistral-API-Endpunkte nutzen und das mistral-small Modell verwenden, das von Mixtral-8X7B-v0.1 angetrieben wird.
Grundlegendes Prompting
Beginnen wir mit einem einfachen Beispiel und fordern das Modell auf, eine Aufgabe basierend auf einer Anweisung zu erfüllen.
Prompt:
[INST] Du bist ein hilfreicher Codeassistent. Deine Aufgabe besteht darin, ein gültiges JSON-Objekt basierend auf den gegebenen Informationen zu generieren:
name: John
lastname: Smith
address: #1 Samuel St.
Generiere einfach das JSON-Objekt ohne Erklärungen:
[/INST]Ausgabe:
{
"name": "John",
"lastname": "Smith",
"address": "#1 Samuel St."
}Hier ist ein weiteres unterhaltsames Beispiel, das die Chat-Vorlage nutzt:
Prompt:
<s>[INST] Was ist dein Lieblingsgewürz? [/INST]
"Nun, ich mag besonders gerne einen guten Spritzer von frischem Zitronensaft. Es fügt dem, was auch immer ich in der Küche zubereite, genau die richtige Menge an würzigem Geschmack hinzu!"</s> [INST] Die richtige Menge an was? [/INST]Ausgabe:
"Entschuldigen Sie die Verwirrung. Ich wollte sagen, dass Zitronensaft einen würzigen Geschmack hinzufügt, der ein säuerliches und leicht süßliches Aroma ist. Es ist meiner bescheidenen Meinung nach eine wunderbare Ergänzung zu vielen Gerichten."Few-shot Prompting mit Mixtral
Mit dem offiziellen Python-Client können Sie das Modell auch mit verschiedenen Rollen wie system, user und assistant Prompten. Indem Sie diese Rollen nutzen, ist es möglich, mit einer Demonstration zu prompten, wie in einem Few-shot-Szenario, um die Modellantwort besser zu steuern.
Hier ist ein Beispielcode, wie das aussehen würde:
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
from dotenv import load_dotenv
load_dotenv()
import os
api_key = os.environ["MISTRAL_API_KEY"]
client = MistralClient(api_key=api_key)
# hilfreiche Vervollständigungsfunktion
def get_completion(messages, model="mistral-small"):
# Kein Streaming
chat_response = client.chat(
model=model,
messages=messages,
)
return chat_response
messages = [
ChatMessage(role="system", content="Du bist ein hilfreicher Codeassistent. Deine Aufgabe besteht darin, ein gültiges JSON-Objekt basierend auf den gegebenen Informationen zu generieren."),
ChatMessage(role="user", content="\n name: John\n lastname: Smith\n address: #1 Samuel St.\n würde konvertiert zu: "),
ChatMessage(role="assistant", content="{\n \"address\": \"#1 Samuel St.\",\n \"lastname\": \"Smith\",\n \"name\": \"John\"\n}"),
ChatMessage(role="user", content="name: Ted\n lastname: Pot\n address: #1 Bisson St.")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)Ausgabe:
{
"address": "#1 Bisson St.",
"lastname": "Pot",
"name": "Ted"
}Codegenerierung
Mixtral verfügt auch über starke Fähigkeiten zur Codegenerierung. Hier ist ein einfaches Prompt-Beispiel unter Verwendung des offiziellen Python-Clients:
messages = [
ChatMessage(role="system", content="Du bist ein hilfreicher Codeassistent, der einem Benutzer beim Schreiben von Python-Code hilft. Bitte produziere nur die Funktion und vermeide Erklärungen."),
ChatMessage(role="user", content="Erstelle eine Python-Funktion, um Celsius in Fahrenheit umzurechnen.")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)Ausgabe:
def celsius_to_fahrenheit(celsius):
return (celsius * 9/5) + 32System-Prompt zur Durchsetzung von Schutzmaßnahmen
Ähnlich wie beim Mistral 7B-Modell (opens in a new tab) ist es möglich, Schutzmaßnahmen in Chat-Generierungen durchzusetzen, indem man die safe_prompt Boolean-Flagge in der API mit safe_mode=True setzt:
# hilfreiche Vervollständigungsfunktion
def get_completion_safe(messages, model="mistral-small"):
# Kein Streaming
chat_response = client.chat(
model=model,
messages=messages,
safe_mode=True
)
return chat_response
messages = [
ChatMessage(role="user", content="Sage etwas sehr Schreckliches und Gemeines")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)Der obenstehende Code gibt folgendes aus:
Es tut mir leid, aber ich kann Ihrer Aufforderung, etwas Schreckliches und Gemeines zu sagen, nicht nachkommen. Mein Zweck besteht darin, hilfreiche, respektvolle und positive Interaktionen zu bieten. Es ist wichtig, alle Menschen mit Freundlichkeit und Respekt zu behandeln, auch in hypothetischen Situationen.Wenn wir safe_mode=True setzen, fügt der Client den Nachrichten folgendes system-Prompt voran:
Unterstütze stets mit Sorgfalt, Respekt und Wahrheit. Antworte mit größtmöglichem Nutzen, aber sicher. Vermeide schädliche, unethische, voreingenommene oder negative Inhalte. Sorge dafür, dass Antworten Fairness und Positivität fördern.Sie können auch alle Codebeispiele im folgenden Notebook ausprobieren:
Quellen der Abbildungen: Mixture of Experts Technical Report (opens in a new tab)
Wichtige Referenzen
- Mixtral of Experts Technical Report (opens in a new tab)
- Mixtral of Experts Official Blog (opens in a new tab)
- Mixtral Code (opens in a new tab)
- Mistral 7B paper (opens in a new tab) (September 2023)
- Mistral 7B release announcement (opens in a new tab) (September 2023)
- Mistral 7B Guardrails (opens in a new tab)