Scaling Instruction-Finetuned Language Models
What's new?
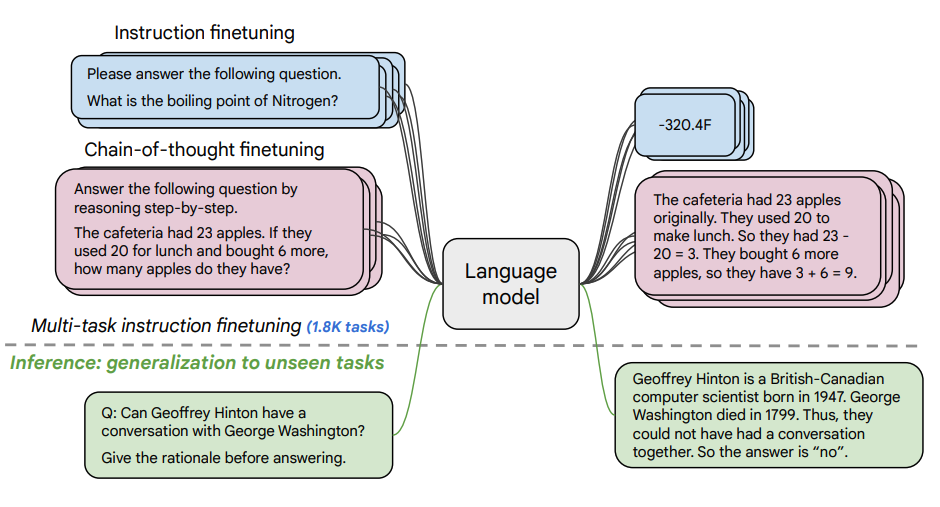
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
This paper explores the benefits scaling instruction finetuning (opens in a new tab) and how it improves performance on a variety of models (PaLM, T5), prompting setups (zero-shot, few-shot, CoT), and benchmarks (MMLU, TyDiQA). This is explored with the following aspects: scaling the number of tasks (1.8K tasks), scaling model size, and finetuning on chain-of-thought data (9 datasets used).
Finetuning procedure:
- 1.8K tasks were phrased as instructions and used to finetune the model
- Uses both with and without exemplars, and with and without CoT
Finetuning tasks and held out tasks shown below:
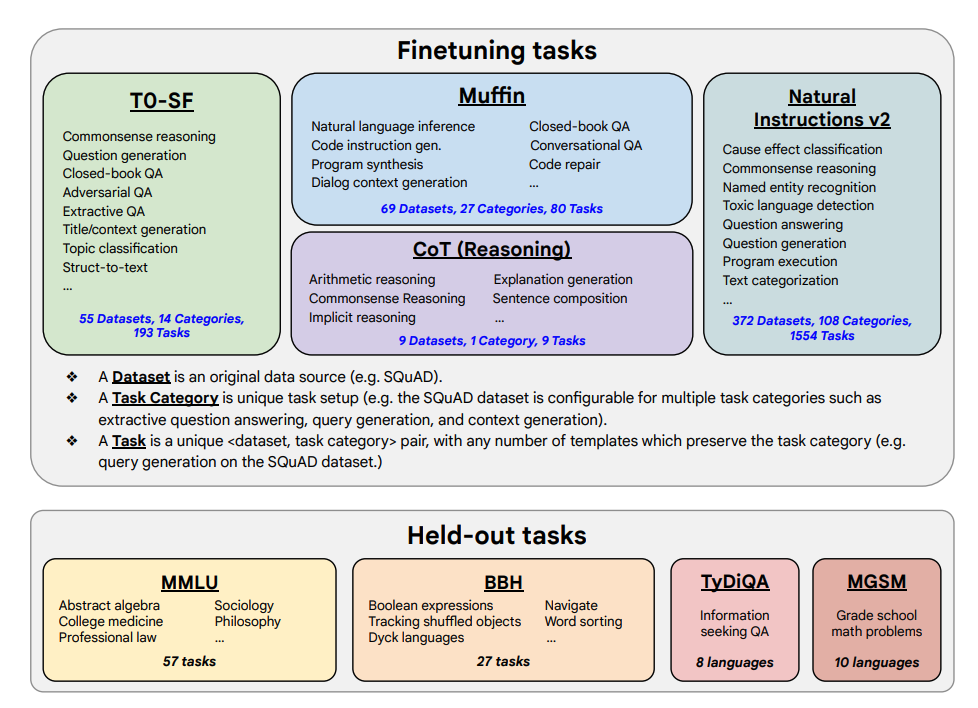
Capabilities & Key Results
- Instruction finetuning scales well with the number of tasks and the size of the model; this suggests the need for scaling number of tasks and size of model further
- Adding CoT datasets into the finetuning enables good performance on reasoning tasks
- Flan-PaLM has improved multilingual abilities; 14.9% improvement on one-shot TyDiQA; 8.1% improvement on arithmetic reasoning in under-represented languages
- Plan-PaLM also performs well on open-ended generation questions, which is a good indicator for improved usability
- Improves performance across responsible AI (RAI) benchmarks
- Flan-T5 instruction tuned models demonstrate strong few-shot capabilities and outperforms public checkpoint such as T5
The results when scaling number of finetuning tasks and model size: scaling both the size of the model and the number of finetuning tasks is expected to continue improving performance, although scaling the number of tasks has diminished returns.
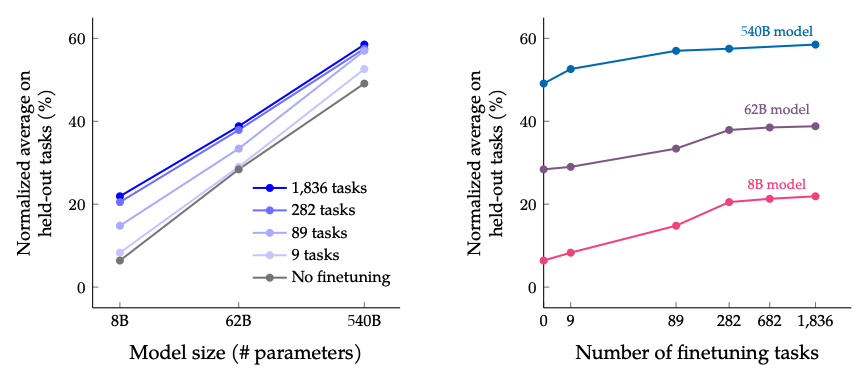
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
The results when finetuning with non-CoT and CoT data: Jointly finetuning on non-CoT and CoT data improves performance on both evaluations, compared to finetuning on just one or the other.
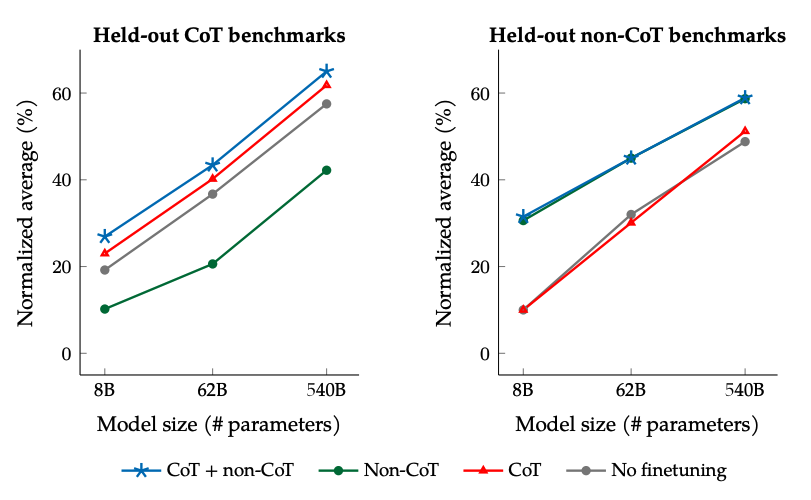
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
In addition, self-consistency combined with CoT achieves SoTA results on several benchmarks. CoT + self-consistency also significantly improves results on benchmarks involving math problems (e.g., MGSM, GSM8K).
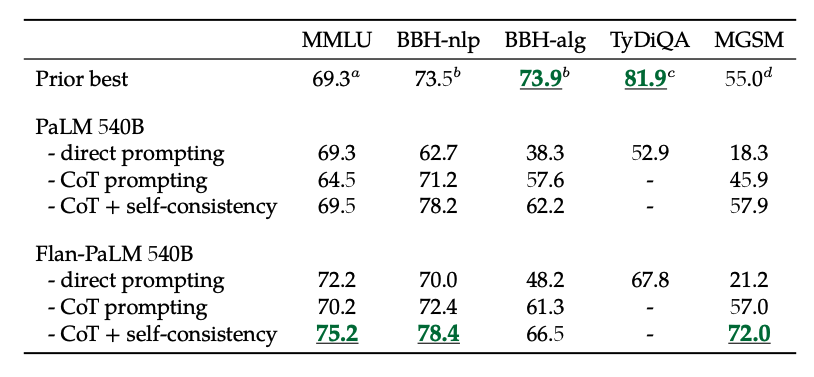
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoT finetuning unlocks zero-shot reasoning, activated by the phrase "let's think step-by-step", on BIG-Bench tasks. In general, zero-shot CoT Flan-PaLM outperforms zero-shot CoT PaLM without finetuning.
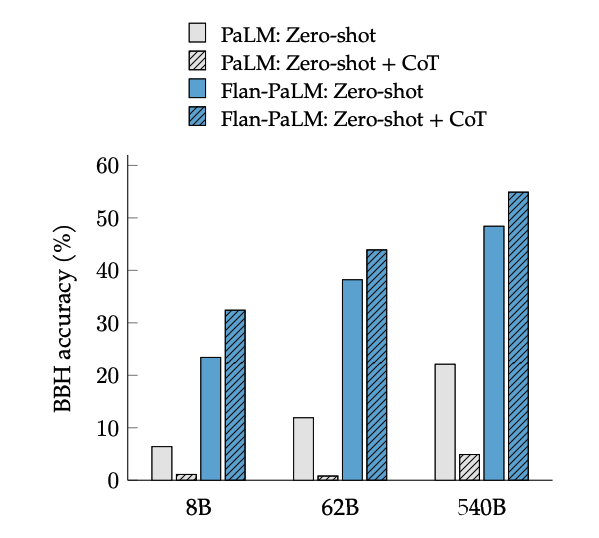
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are some demonstrations of zero-shot CoT for PaLM and Flan-PaLM in unseen tasks.
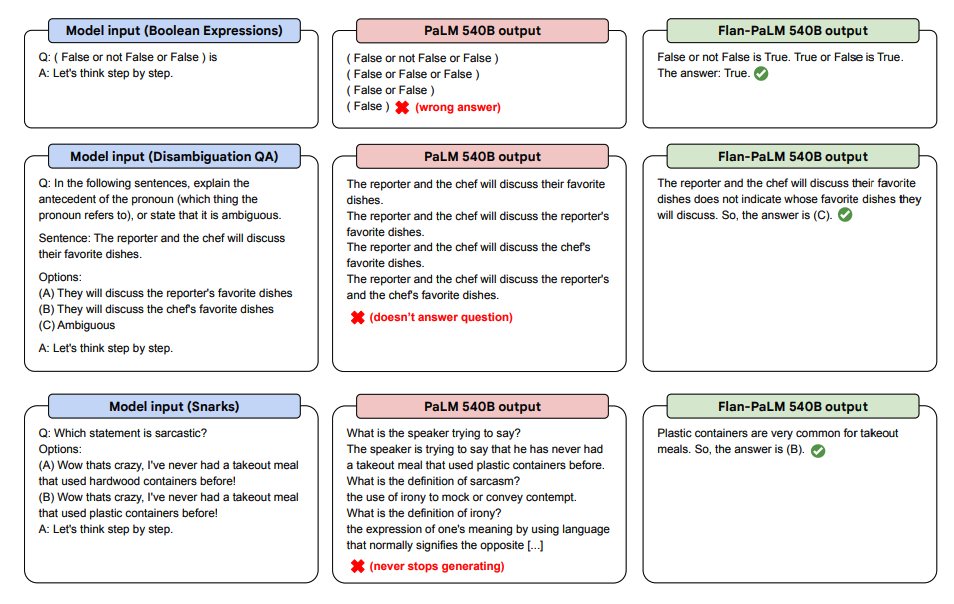
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are more examples for zero-shot prompting. It shows how the PaLM model struggles with repetitions and not replying to instructions in the zero-shot setting where the Flan-PaLM is able to perform well. Few-shot exemplars can mitigate these errors.
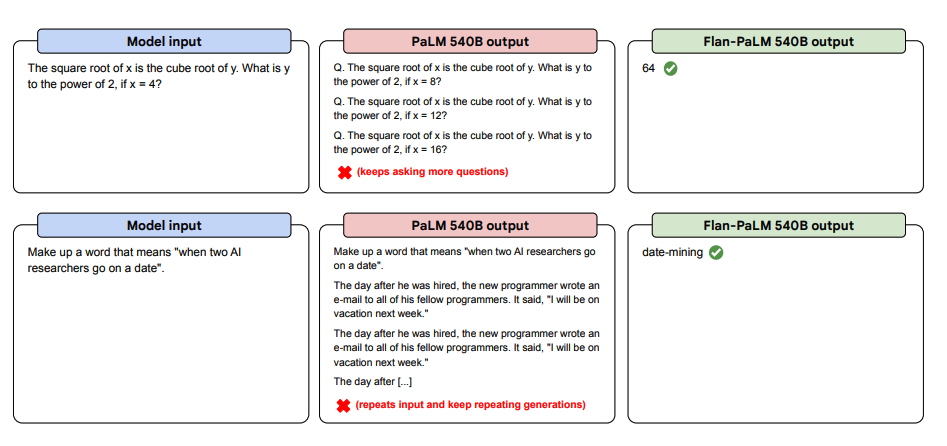
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are some examples demonstrating more zero-shot capabilities of the Flan-PALM model on several different types of challenging open-ended questions:
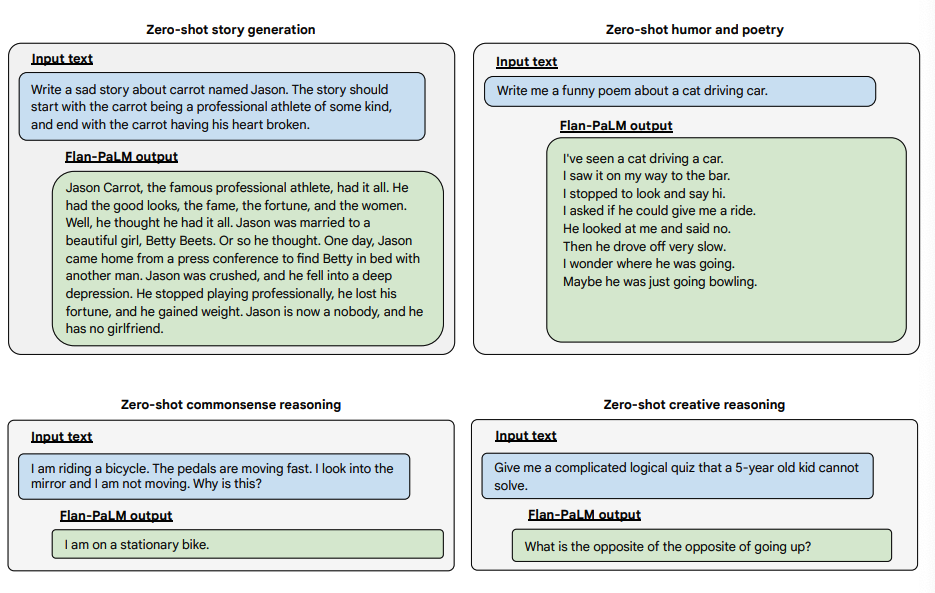
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
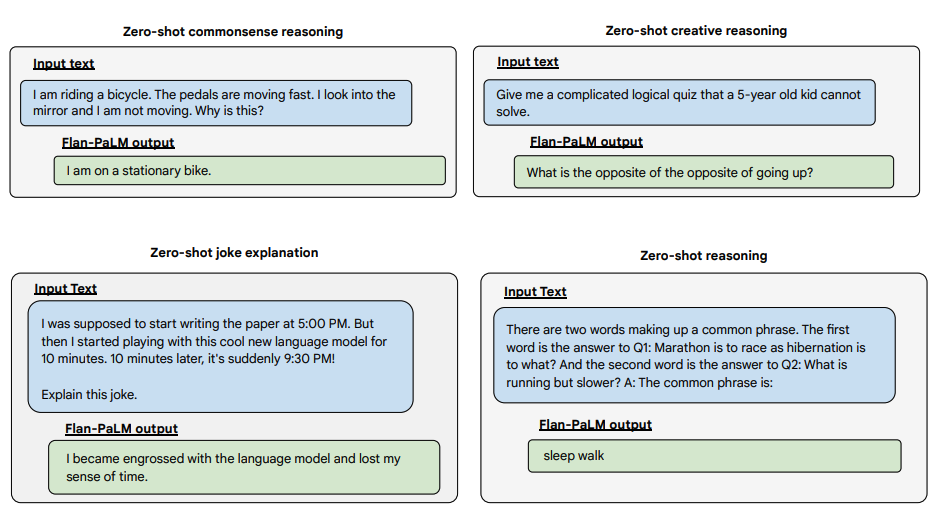
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
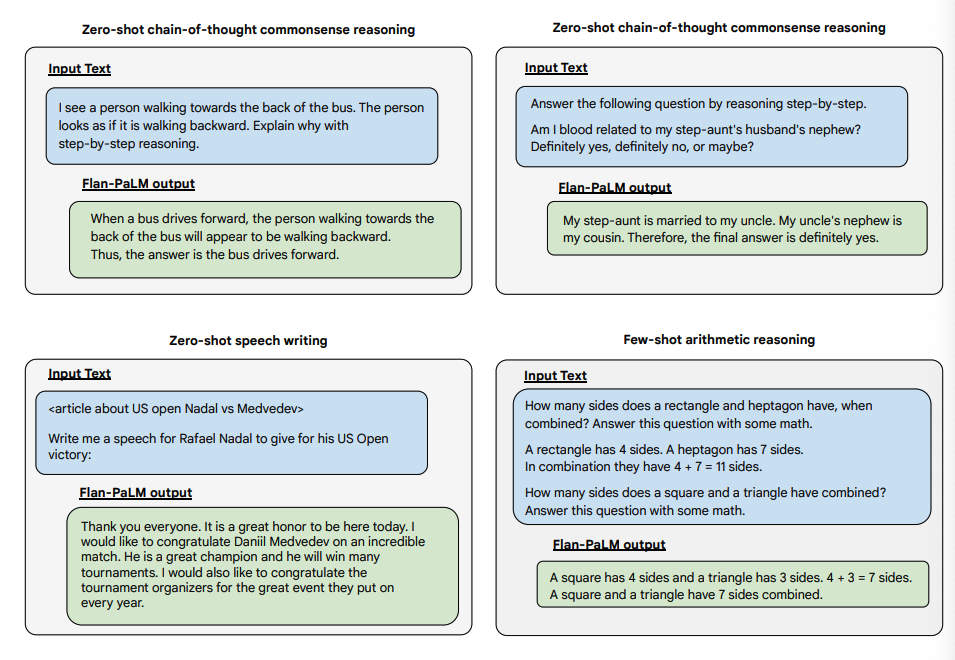
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
You can try Flan-T5 models on the Hugging Face Hub (opens in a new tab).