ReAct Prompting
Yao и др., 2022 (opens in a new tab) представили фреймворк под названием ReAct, в котором использовались LLM для генерации следов рассуждений и задачно-специфичных действий в интерактивной манере.
Генерация следов рассуждений позволяет модели создавать, отслеживать и обновлять планы действий, а также обрабатывать исключительные ситуации. Действия позволяют взаимодействовать с внешними источниками информации, такими как базы знаний или окружения.
Фреймворк ReAct позволяет LLM взаимодействовать с внешними инструментами для получения дополнительной информации, что приводит к более надежным и фактическим ответам.
Результаты показывают, что ReAct может превзойти несколько современных базовых решений в языковых задачах и задачах на принятия решений. ReAct также приводит к улучшенной человеко-интерпретируемости и надежности LLM. В целом авторы обнаружили, что наилучшим подходом является использование ReAct в сочетании с цепочкой мыслей (CoT), что позволяет использовать как внутренние знания, так и внешнюю информацию, полученную в процессе рассуждения.
Как это работает?
ReAct вдохновлен взаимодействием между "действием" и "рассуждением", которое позволяет людям изучать новые задачи и принимать решения или рассуждать.
Промптинг цепочкой мыслей (CoT) продемонстрировал возможности LLM для проведения следов рассуждений и генерации ответов на вопросы, включающих арифметическое и общезначимое рассуждение, среди других задач (Wei и др., 2022) (opens in a new tab). Однако его ограниченный доступ к внешнему миру или невозможность обновления знаний могут приводить к проблемам, таким как выдумывание фактов и распространение ошибок.
ReAct - это общая парадигма, объединяющая рассуждение и действие с помощью LLM. ReAct побуждает LLM генерировать вербальные следы рассуждений и действий для задачи. Это позволяет системе выполнять динамическое рассуждение для создания, поддержки и корректировки планов действий, а также обеспечивает взаимодействие с внешними средами (например, Википедия), чтобы включить дополнительную информацию в рассуждение. На приведенной ниже схеме показан пример ReAct и различные шаги, необходимые для выполнения вопросно-ответной задачи.

Источник изображения: Yao и др., 2022 (opens in a new tab)
В приведенном выше примере мы передаем подобный вопрос, взятый из HotpotQA (opens in a new tab):
Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?Обратите внимание, что для простоты мы не включаем примеры контекста. Мы видим, что модель генерирует траектории решения задач (Мысли, Действия). Обозначение Obs соответствует наблюдениям из взаимодействующей среды (например, поисковой системы). По сути, ReAct может извлекать информацию для поддержки рассуждений, а рассуждение помогает определить, что следует извлекать далее.
ReAct Prompting
Чтобы продемонстрировать, как работает промптинг ReAct, давайте рассмотрим пример из статьи.
Первый шаг - выбрать случаи из обучающего набора (например, HotPotQA) и составить траектории в формате ReAct. Они используются как экземпляры с малым количеством примеров в промптах. Траектории состоят из нескольких шагов мысли-действия-наблюдения, как показано на схеме выше. Свободные формы мыслей используются для выполнения различных задач, таких как разложение вопросов, извлечение информации, выполнение общезначимого/арифметического рассуждения, формулировка поискового запроса и синтез окончательного ответа.
Вот пример траекторий ReAct-промпта (полученный из статьи и сокращенный до одного примера для простоты):
Question What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up eastern
sector.
Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called
the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So I
need to search High Plains and find its elevation range.
Action 3 Search[High Plains]
Observation 3 High Plains refers to one of two distinct land regions
Thought 4 I need to instead search High Plains (United States).
Action 4 Search[High Plains (United States)]
Observation 4 The High Plains are a subregion of the Great Plains. From east to west, the
High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130
m).[3]
Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer
is 1,800 to 7,000 ft.
Action 5 Finish[1,800 to 7,000 ft]
...Обратите внимание, что для разных типов задач используются разные промпт-установки. Для задач, в которых рассуждение является основной задачей (например, HotpotQA), для траектории решения задачи используются несколько шагов мысли-действия-наблюдения. Для задач принятия решений, включающих множество шагов действия, мысли используются редко.
Результаты на задачах, требующих знаний
В статье сначала оцениваются результаты ReAct на задачах рассуждения, требующих знаний, таких как вопросно-ответная система (HotPotQA) и проверка фактов (Fever (opens in a new tab)). В качестве базовой модели для промптинга используется PaLM-540B.
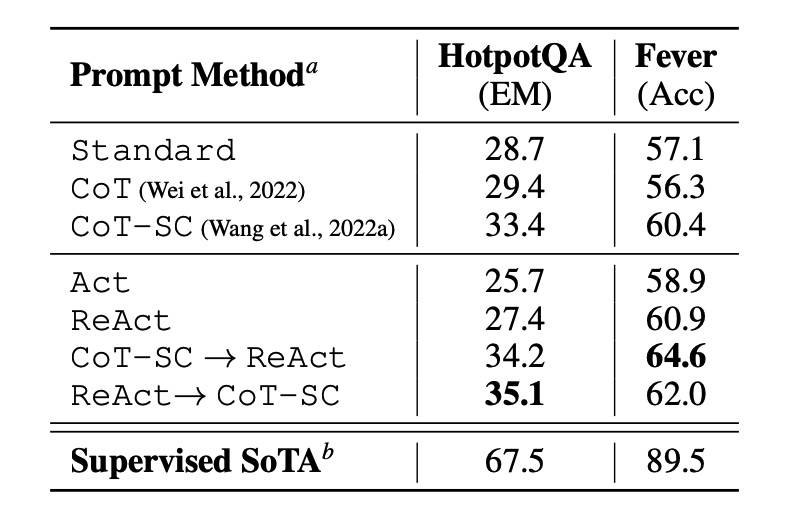
Источник изображения: Yao и др., 2022 (opens in a new tab)
Результаты промптинга на HotPotQA и Fever с использованием разных методов промптинга показывают, что ReAct в целом работает лучше, чем только действие (Act) в обеих задачах.
Можно также заметить, что ReAct превосходит CoT на задаче Fever, но уступает CoT на HotpotQA. Подробный анализ ошибок представлен в статье. В кратком виде:
- CoT страдает от выдумывания фактов
- Структурное ограничение ReAct уменьшает его гибкость в формулировке рассуждений
- ReAct сильно зависит от получаемой информации; неинформативные результаты поиска сбивают модель с рассуждения и затрудняют восстановление и переформулировку мыслей
Методы промптинга, которые комбинируют и поддерживают переключение между ReAct и CoT+Self-Consistency, в целом показывают лучшие результаты по сравнению с другими методами промптинга.
Результаты на задачах принятия решений
Статья также представляет результаты, демонстрирующие производительность ReAct на задачах принятия решений. ReAct оценивается на двух бенчмарках, называемых ALFWorld (opens in a new tab) (текстовая игра) и WebShop (opens in a new tab) (среда онлайн-шопинга). Оба они включают сложные среды, требующие рассуждения для эффективного действия и исследования.
Обратите внимание, что промпты ReAct разработаны по-разному для этих задач, сохраняя ту же основную идею объединения рассуждения и действия. Вот пример проблемы ALFWorld, включающей промпт ReAct.
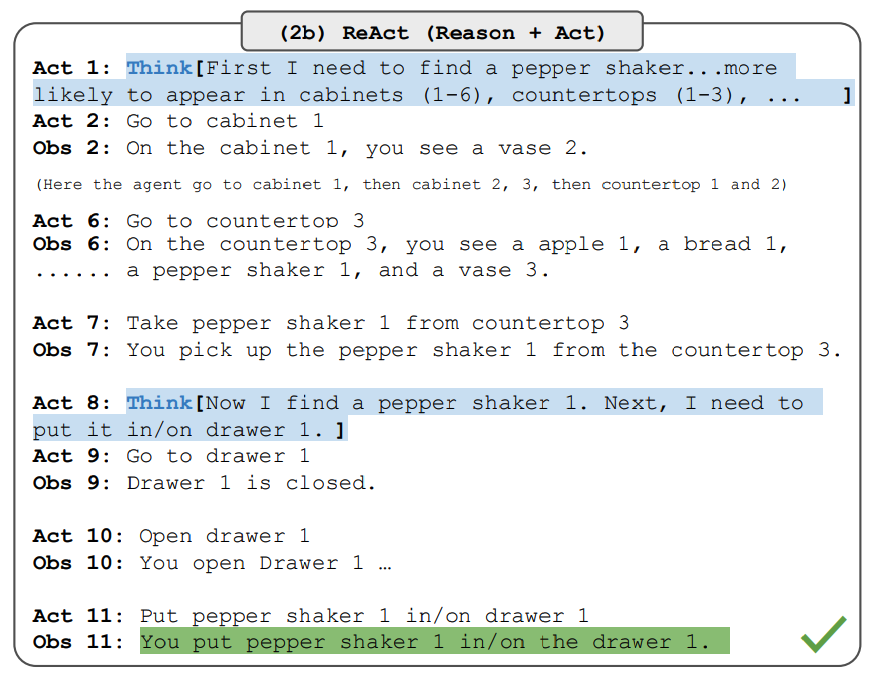
Источник изображения: Yao и др., 2022 (opens in a new tab)
ReAct превосходит Act как на ALFWorld, так и на Webshop. Act, без мыслей, не может правильно разложить цели на подцели. Рассуждение оказывается выгодным для этих типов задач, но текущие методы промптинга все еще значительно отстают от профессиональных людей в выполнении этих задач.
Для получения более подробных результатов рекомендуется обратиться к статье.
Использование ReAct в LangChain
Ниже приведен пример того, как подход промптинга ReAct работает на практике. Мы будем использовать OpenAI для LLM и LangChain (opens in a new tab), так как в нем уже есть встроенные функции, которые используют фреймворк ReAct для создания агентов, выполняющих задачи, объединяя мощность LLM и различных инструментов.
Сначала установим и импортируем необходимые библиотеки:
%%capture
# update or install the necessary libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# import libraries
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# load API keys; you will need to obtain these if you haven't yet
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Теперь мы можем настроить LLM, инструменты, которые мы будем использовать, и агента, который позволяет нам использовать фреймворк ReAct вместе с LLM и инструментами. Обратите внимание, что мы используем API поиска для поиска внешней информации и LLM в качестве математического инструмента.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)После настройки мы можем запустить агента с желаемым запросом/промптом. Обратите внимание, что здесь не требуется предоставлять экземпляры с малым количеством примеров, как объясняется в статье.
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")Цепочка выполнения выглядит следующим образом:
> Entering new AgentExecutor chain...
I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis — see their relationship timeline.
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
Thought: I need to calculate 29 raised to the 0.23 power.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: I now know the final answer.
Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.
> Finished chain.Полученный вывод выглядит следующим образом:
"Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557."Мы адаптировали пример из документации LangChain (opens in a new tab), поэтому заслуги принадлежат им. Мы рекомендуем исследовать различные комбинации инструментов и задач.
Вы можете найти ноутбук для этого кода здесь: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb (opens in a new tab)