LLaMA: Open and Efficient Foundation Language Models
Данный раздел находится в активной разработке.
Что нового?
В статье представлена коллекция основных языковых моделей (LLaMA) с количеством параметров от 7 млрд до 65 млрд.
Модели обучаются на триллионах токенов с использованием публично доступных наборов данных.
Работа (Hoffman et al., 2022) (opens in a new tab) показывает, что при ограниченном вычислительном бюджете более маленькие модели, обученные на гораздо большем объеме данных, могут достичь лучшей производительности по сравнению с более крупными моделями. В этой работе рекомендуется обучать модели размером 10 млрд на 200 млрд токенов. Однако статья LLaMA обнаружила, что производительность модели размером 7 млрд продолжает улучшаться даже после 1 трлн токенов.
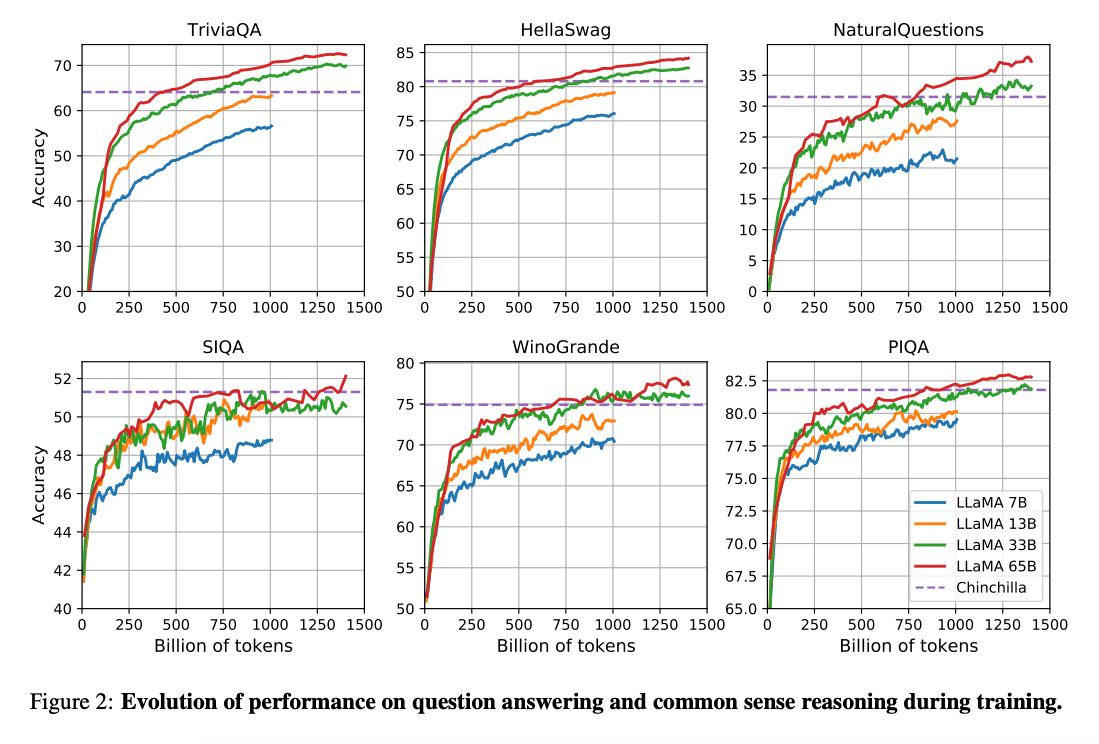
В этой работе акцент сделан на обучении моделей (LLaMA), достигающих наилучшей производительности при различных бюджетах вывода, путем обучения на большем количестве токенов.
Возможности и ключевые моменты
В целом, модель LLaMA-13B показывает лучшие результаты по сравнению с GPT-3(175B) на многих бенчмарках, несмотря на то, что она в 10 раз меньше и может работать на одной графической карте. Модель LLaMA-65B конкурентоспособна с моделями, такими как Chinchilla-70B и PaLM-540B.
Статья: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Код: https://github.com/facebookresearch/llama (opens in a new tab)
Ссылки
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)