Tree of Thoughts (ToT)
탐구나 전략적인 예측이 필요한 복잡한 작업들을 해결하기 위해서는 기존의 단순한 프롬프팅 기법으로는 부족합니다. Yao et el. (2023) (opens in a new tab)와 Long (2023) (opens in a new tab)는 최근 Tree of Thoughts(ToT)의 개념을 제안했는데, 이 프레임워크는 '생각의 사슬(chain-of-thought)' 프롬프팅 기법을 일반화하며, 언어모델을 사용하여 일반적인 문제 해결을 위한 중간 단계 역할을 하는 생각에 대한 탐색을 촉진합니다.
ToT는 문제를 해결하기 위한 중간 단계로서 일관된 언어 시퀀스를 나타내는 Tree of Thoughts를 유지합니다. 이 접근법을 통해 언어모델은 신중한 추론 과정을 거쳐 문제를 해결하기 위한 중간 생각들이 문제를 해결해나가는 과정을 자체적으로 평가할 수 있게 됩니다. 그리고 이 언어모델이 생각을 생성하고 평가하는 능력은 탐색 알고리즘(예: 너비 우선 탐색과 깊이 우선 탐색(DFS))과 결합되어, 선제적 탐색과 백트래킹이 가능한 생각의 체계적인 탐색을 가능하게 합니다.
ToT 프레임워크는 다음과 같습니다.
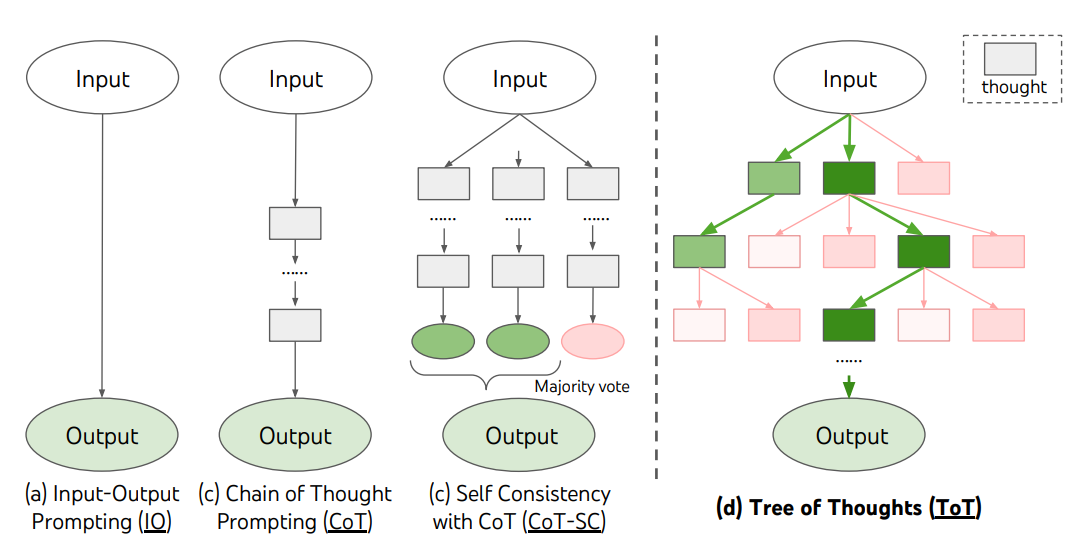
이미지 출처: Yao et el. (2023) (opens in a new tab)
ToT를 사용할 때, 다른 작업들은 후보의 수와 생각/단계의 수를 정의하는 것을 요구합니다. 예를 들어, 논문에서 보여진 바와 같이, 24의 게임은 사고를 3단계로 분해하는 수학적 추론 과제로 사용되었습니다. 각 단계는 중간 방정식을 포함합니다. 각 단계에서, 최선의 b=5 후보들이 유지됩니다.
24의 게임 작업에 대한 ToT의 너비 우선 탐색(BFS)를 수행하기 위해, 언어모델은 각 사고 후보를 24에 도달하는 것에 대해 "확실함/아마도/불가능함"으로 평가하도록 요청합니다. 저자들은 "목표는 몇 번의 선제적 시험 내에서 판결을 내릴 수 있는 올바른 부분적 해결책을 촉진하고, '너무 크거나 작은' 상식에 기반한 불가능한 부분 해결책을 제거하고, 나머지 '아마도'를 유지하는 것"입니다. 각 생각에 대한 값은 3번 샘플링됩니다. 아래에 이 과정이 그림으로 나타나 있습니다:
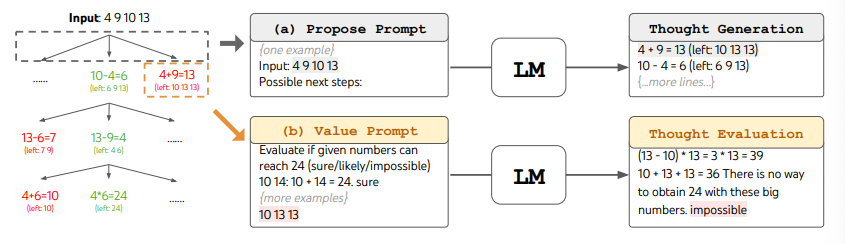
이미지 출처: Yao et el. (2023) (opens in a new tab)
아래 그림에서 보고된 결과에서 볼 수 있듯, ToT는 다른 프롬프팅 방법들에 비해 월등히 뛰어납니다.
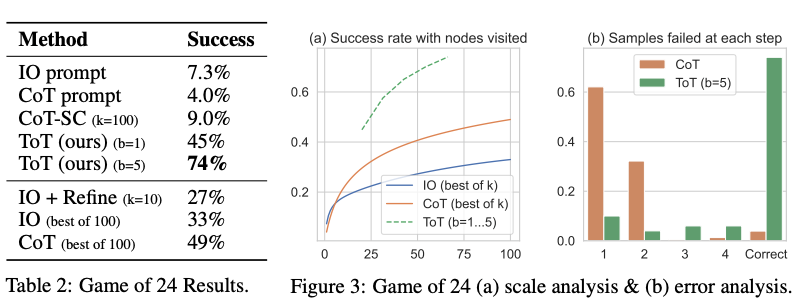
이미지 출처: Yao et el. (2023) (opens in a new tab)
이곳 (opens in a new tab)과 이곳 (opens in a new tab)의 코드를 사용할 수 있습니다.
높은 수준에서 보면, Yao et el. (2023) (opens in a new tab)와 Long (2023) (opens in a new tab)의 주요 아이디어는 유사합니다. 두 연구 모두 다중 라운드 대화를 통한 트리 검색을 통해 대규모언어모델의 복잡한 문제 해결 능력을 향상시킵니다. 주요 차이점 중 하나는 Yao et el. (2023) (opens in a new tab)이 깊이 우선 탐색/너비 우선 탐색/빔 탐색을 활용하는 반면, Long (2023) (opens in a new tab)에서 제안하는 트리 검색 전략(즉, 언제 백트래킹을 하고, 몇 단계로 백트래킹을 하는지 등)은 강화 학습을 통해 훈련된 "ToT 컨트롤러"에 의해 주도됩니다. 깊이 우선 탐색/너비 우선 탐색/빔 탐색은 특정 문제에 대한 적응 없이 일반적인 해결책 검색 전략입니다. 반면, RL을 통해 훈련된 ToT 컨트롤러는 새로운 데이터 세트나 자체 플레이를 통해 학습할 수 있을 수 있으며(AlphaGo vs 무차별 검색), 따라서 RL 기반의 ToT 시스템은 고정된 LLM으로도 계속해서 발전하고 새로운 지식을 배울 수 있습니다.
Hulbert (2023) (opens in a new tab)은 Tree-of-Thought 프롬프팅을 제안했는데, 이는 ToT 프레임워크의 주요 개념을 단순한 프롬프팅 기법으로 적용하여 LLM이 단일 프롬프트에서 중간 생각을 평가하게 합니다. 샘플 ToT 프롬프트는 다음과 같습니다.
세 명의 다른 전문가들이 이 질문에 답하고 있다고 상상해보도록 해.
모든 전문가들은 자신의 생각의 한 단계를 적어내고,
그것을 그룹과 공유할거야.
그런 다음 모든 전문가들은 다음 단계로 넘어가. 등등.
만약 어떤 전문가가 어떤 시점에서든 자신이 틀렸다는 것을 깨닫게 되면 그들은 떠나.
그렇다면 질문은...