Retrieval Augmented Generation (RAG)
General-purpose 언어 모델은 일반적인 작업을 달성하도록 감정 분석 및 명명된 엔티티 인식을 미세 조정 할 수 있습니다. 이러한 작업에는 일반적으로 추가적인 배경지식이 필요하지 않습니다.
더 복잡한 지식을 모아 요약하는 작업의 경우 외부 지식 소스에 액세스하여 완료하는 언어 모델 기반 시스템을 구축할 수 있습니다. 이를 통해 사실적 일관성을 높이고, 생성된 응답의 신뢰성을 향상시키며, "환각" 문제를 완화하는 데 도움이 됩니다.
Meta AI 연구원들은 이러한 지식을 모아 요약하는 작업을 해결하기 위해 Retrieval Augmented Generation (RAG) (opens in a new tab) 라는 방법을 도입했습니다. RAG는 정보 구성 요소를 글자 생성기 모델과 결합합니다. RAG는 미세 조정이 가능하며 전체 모델을 재교육할 필요 없이 내부 지식을 효율적으로 수정할 수 있습니다.
RAG는 입력을 받아 주어진 소스(예: 위키피디아)에서 관련된/지원하는 문서들을 찾습니다. 문서는 원래 입력 프롬프트와 컨텍스트로 연결되어 최종 출력을 생성하는 텍스트 생성기에 공급됩니다. 따라서 시간이 지남에 따라 RAG는 어떤 상황이던 사실적으로 적응할 수 있습니다. 이는 LLM의 매개 변수 지식이 정적이기 때문에 매우 유용합니다. RAG는 언어 모델들의 재교육 우회를 허용하여, 검색 기반 생성을 통해 신뢰할 수 있는 출력물을 생성하여 최신 정보로 접속할 수 있습니다.
Lewis et al.,(2021)은 RAG에 대한 범용 미세 조정 레시피를 제안했습니다. 사전 훈련된 seq2seq 모델은 파라메트릭 메모리로 사용되고 위키피디아의 밀집한 벡터 인덱스는 논파라메트릭 메모리로 사용됩니다(사전 훈련된 신경 리트리버를 사용하여 허용됨). 다음은 접근 방식의 개요입니다:
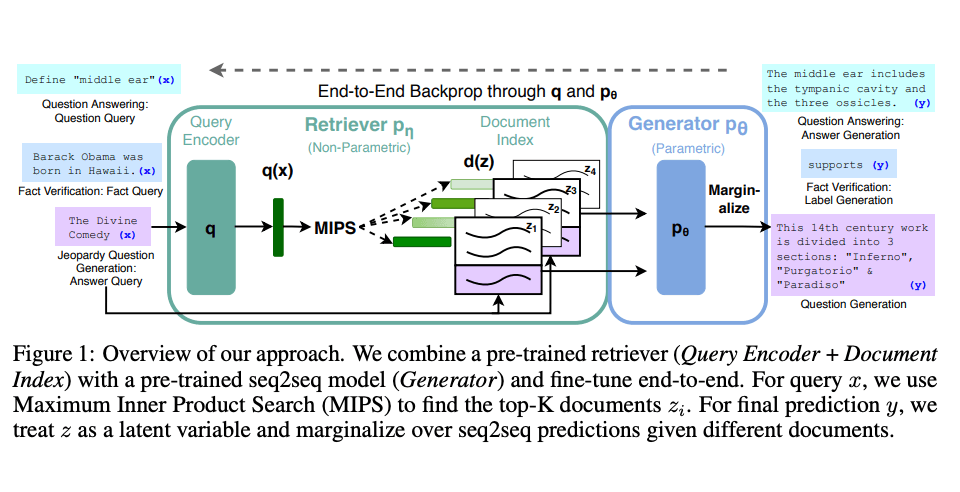
이미지 소스: Lewis et el. (2021) (opens in a new tab)
RAG는 자연스러운 질문 (opens in a new tab), 웹 질문 (opens in a new tab), 큐레이드 트랙과 같은 여러 벤치마크에서 강력한 성능을 발휘합니다. RAG는 MS-MARCO와 Jeopardy 질문들을 테스트할 때 보다 사실적이고 구체적이며 다양한 응답을 생성합니다. RAG는 또한 FEVER 사실 검증 결과를 개선합니다.
이것은 지식을 모아 요약하는 작업에서 언어 모델의 출력을 향상시키기 위한 실행 가능한 옵션으로서 RAG의 잠재력을 보여줍니다.
최근에는 이러한 리트리버 기반 접근 방식이 더욱 대중화되었으며 기능과 사실적 일관성을 향상시키기 위해 ChatGPT와 같은 인기 있는 LLM이 결합되었습니다.
LangChain 문서에서 소스를 사용한 질문 답변에 리트리버와 LLM을 사용하는 방법에 대한 간단한 예시 (opens in a new tab)를 찾을 수 있습니다.