지시에 따라 파인튜닝된(Instruction-Finetuned) 언어 모델 스케일링
새로운 소식은 무엇인가요?
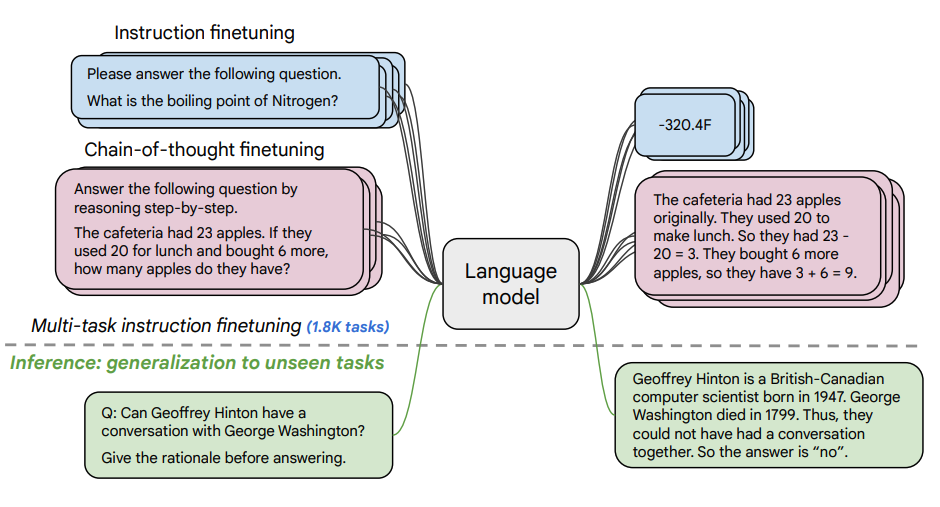
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
이 논문은 지시에 따른 파인튜닝 (opens in a new tab)의 스케일링에서의 장점을 알아보며 다양한 모델(PaLM, T5)과 프롬프팅 설정(zero-shot, few-shot, CoT), 벤치마크(MMLU, TyDiQA)에서 어떻게 성능을 개선하는지를 다룹니다. 이는 다음과 같은 측면에서 탐구되었습니다: 작업 수의 스케일링 (1,800개의 작업), 모델 크기의 스케일링 및 생각의 사슬(Chain of Tought) 데이터의 파인튜닝 (9개의 데이터셋 사용).
파인튜닝 절차:
- 1,800개의 작업을 지시사항으로 모델을 파인튜닝 하는 데 활용했습니다.
- 예시가 있는 경우와 없는 경우, CoT(Chain of Tought)가 있는 경우와 그렇지 않은 경우 모두 적용했습니다.
Finetuning 및 Held-out 작업은 다음과 같습니다:
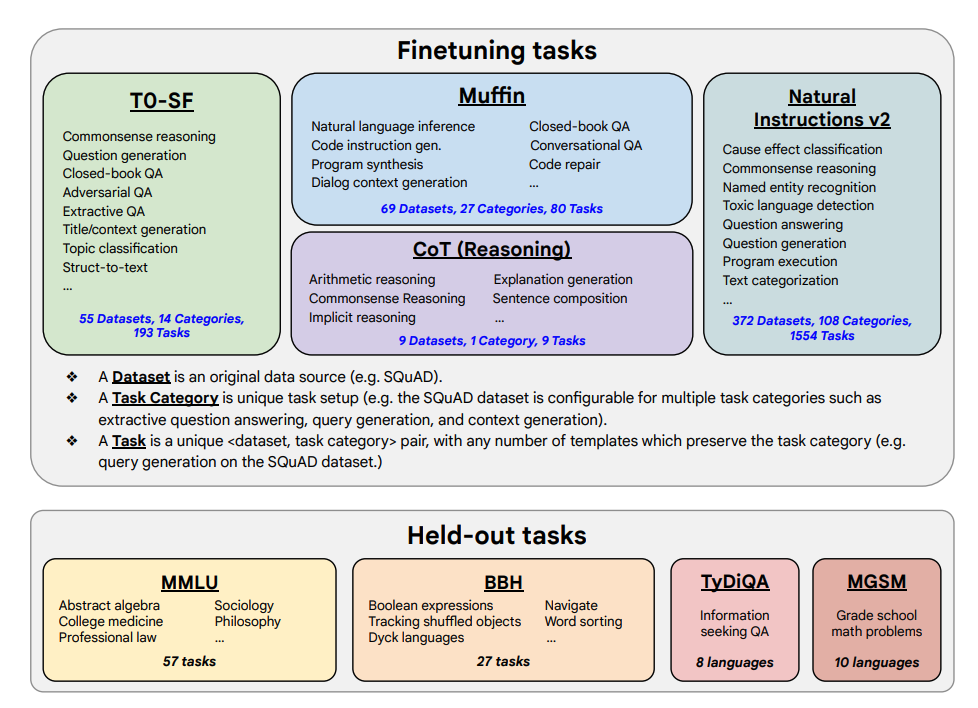
기능 및 주요 결과(Capabilities & Key Results)
- 지시에 따른 파인튜닝은 작업의 수와 모델의 크기와 함께 향상될 수 있습니다; 이는 작업의 수와 모델의 크기를 더욱 확장해야 함을 시사합니다.
- CoT 데이터셋을 파인튜닝에 추가하면 추론 작업에서 우수한 성능을 보여줍니다.
- Flan-PaLM은 다국어 능력을 향상했습니다.; one-shot TyDiQA에서 14.9%; under-represented languages 산술적 추론에서 8.1% 개선을 보였습니다.
- Plan-PaLM은 또한 확장할 수 있는(open-ended) 생성 질문에서도 우수한 성능을 보여주며, 이는 사용성이 향상된 것을 알 수 있는 좋은 지표입니다.
- Responsible AI (RAI) 벤치마크에서도 성능을 향상했습니다.
- Flan-T5 instruction tuned 모델은 강력한 퓨샷(few-shot) 성능을 보여주며, T5(Text-to-Text Transfer Transformer)와 같은 사전 훈련된 모델(public checkpoint)보다 뛰어난 성능을 보여줍니다.
파인튜닝 하는 작업의 수와 모델의 크기를 확장하는 경우 결과는 다음과 같습니다: 모델의 크기와 작업의 수 모두 확장 시 성능이 지속해서 향상할 것으로 예상되지만, 작업 수를 증가시킬 시 성능 향상의 이득이 감소했습니다.
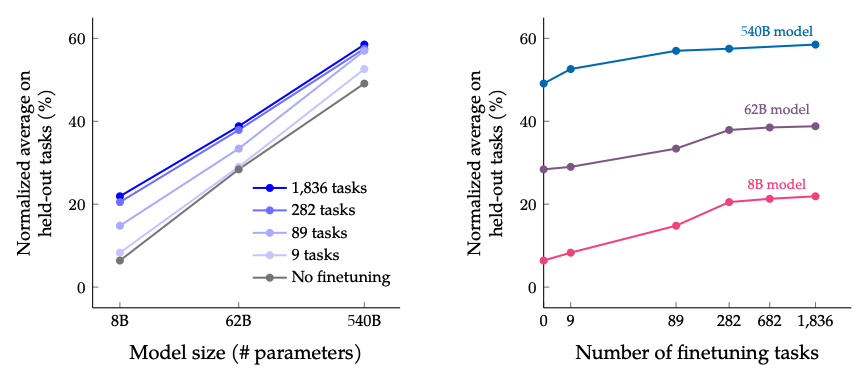
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoT 데이터와 비-CoT 데이터로 파인튜닝을 한 결과: 비-CoT 및 CoT 데이터를 공동으로 파인튜닝 하면, 하나만 파인튜닝 하는 것보다 평가 성능이 향상합니다.
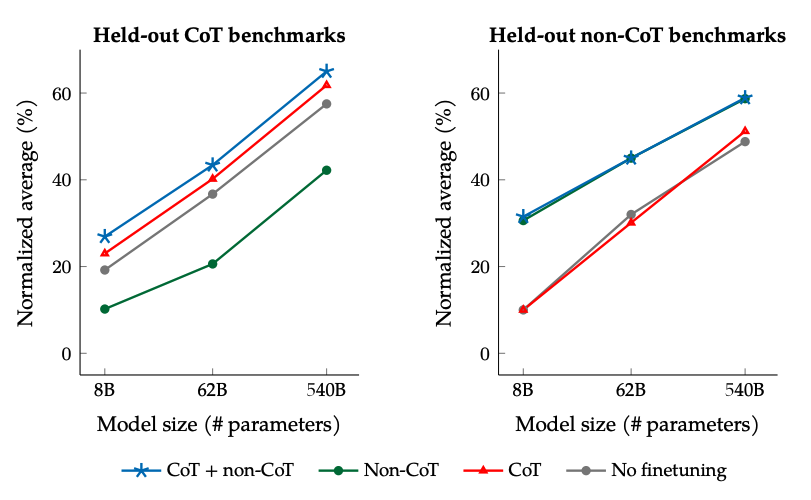
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
또한, 자기 일관성(self-consistency)과 CoT를 결합하면 몇몇 벤치마크에서 최고 성능(SoTA) 결과를 달성합니다. CoT + 자기 일관성은 수학 문제를 포함하는 벤치마크(MGSM, GSM8K 등)에서 결과를 상당히 향상합니다.
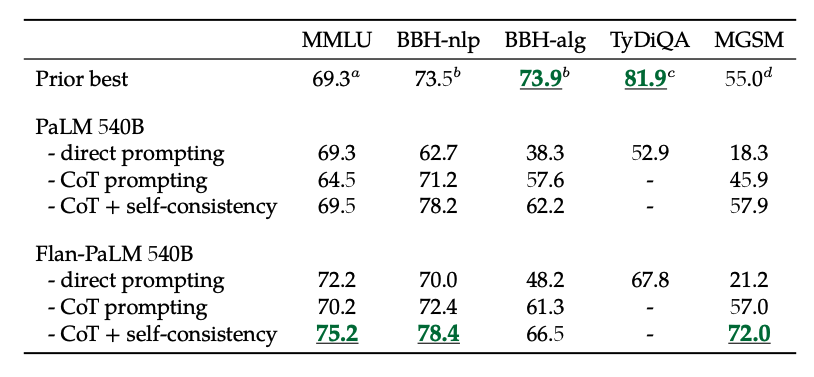
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoT 파인튜닝은 BIG-Bench(Beyond the limitation Game Benchmark) 작업에서 제로샷(zero-shot) 추론이 가능하게 합니다. 일반적으로, 제로샷 CoT Flan-PaLM은 파인튜닝 하지 않은 CoT PaLM 보다 성능이 우수합니다.
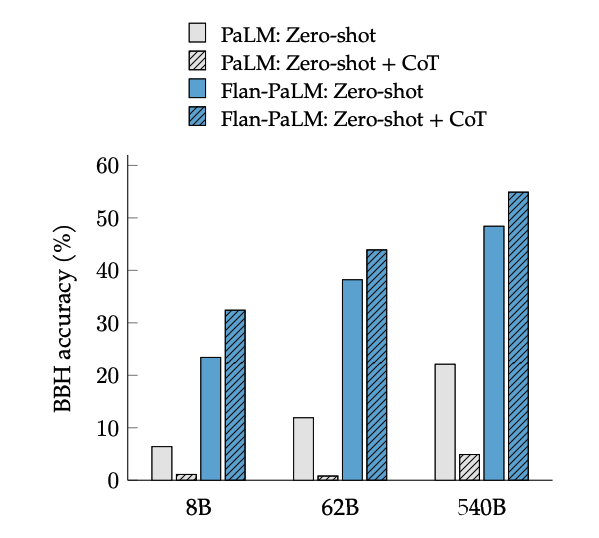
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
아래는 PaLM과 Flan-PaLM의 제로샷 CoT에 대한 일부 보이지 않는 작업의 설명입니다.
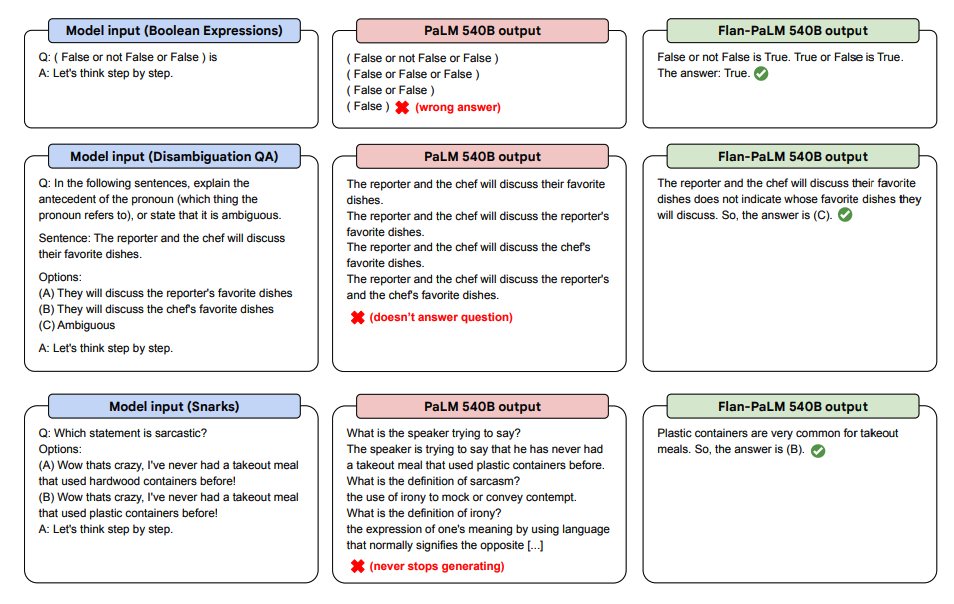
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
아래는 제로샷 프롬프팅에 대한 더 많은 예시입니다. 이는 제로샷 환경에서 PaLM이 반복 및 지시에 응답하지 못하는 문제가 있지만, Flan-PaLM은 잘 수행할 수 있음을 보여줍니다. 퓨샷 예시를 사용 시 이러한 오류를 줄일 수 있습니다.
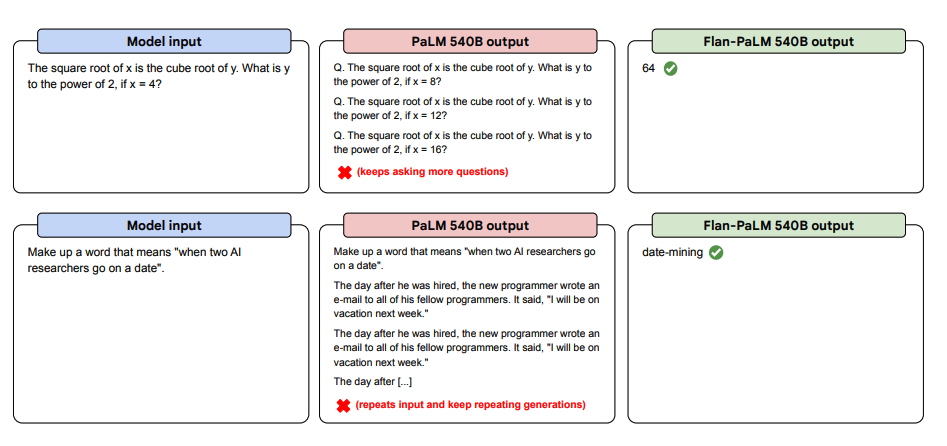
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
아래는 다양하며 도전적인 확장성 있는 질문에 Flan-PALM 모델이 더 많은 제로샷 성능을 보여 즐 수 있다는 몇 가지 예시입니다:
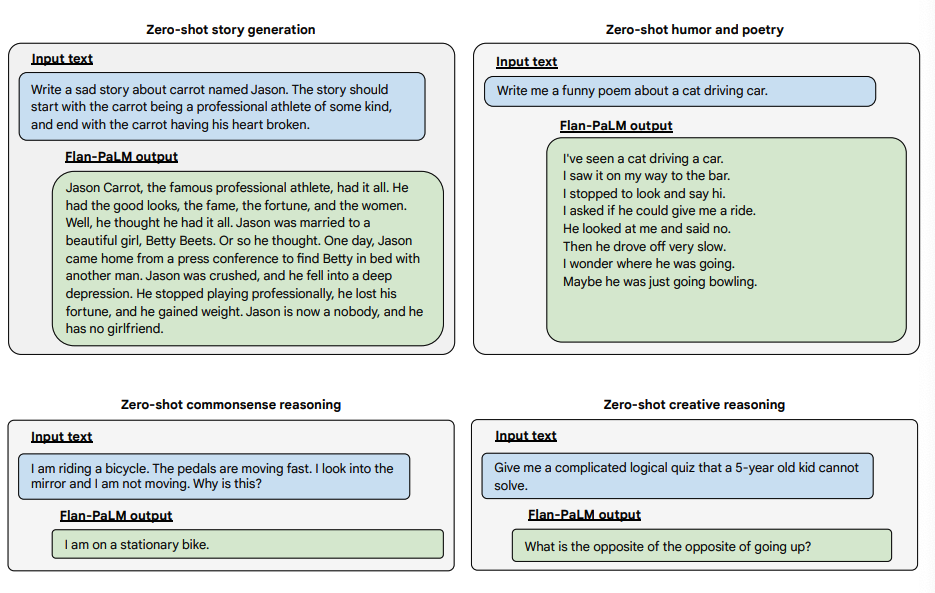
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
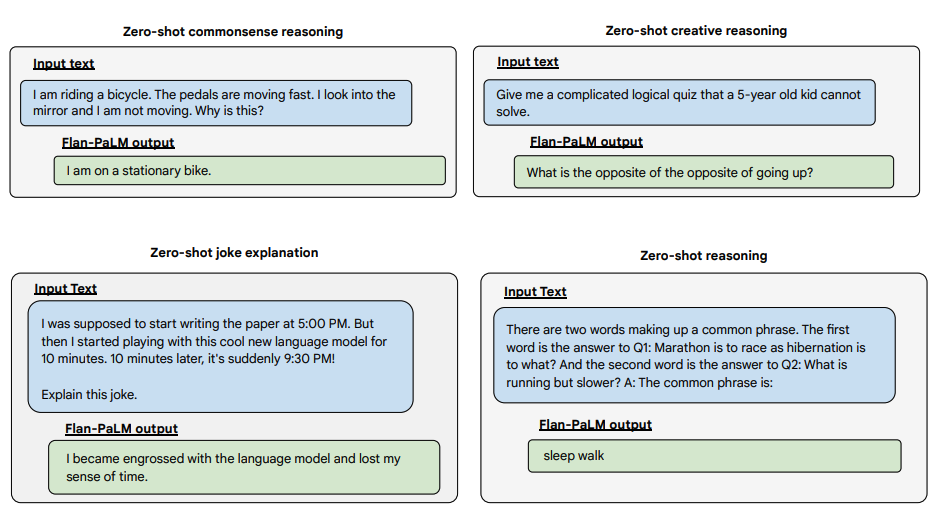
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
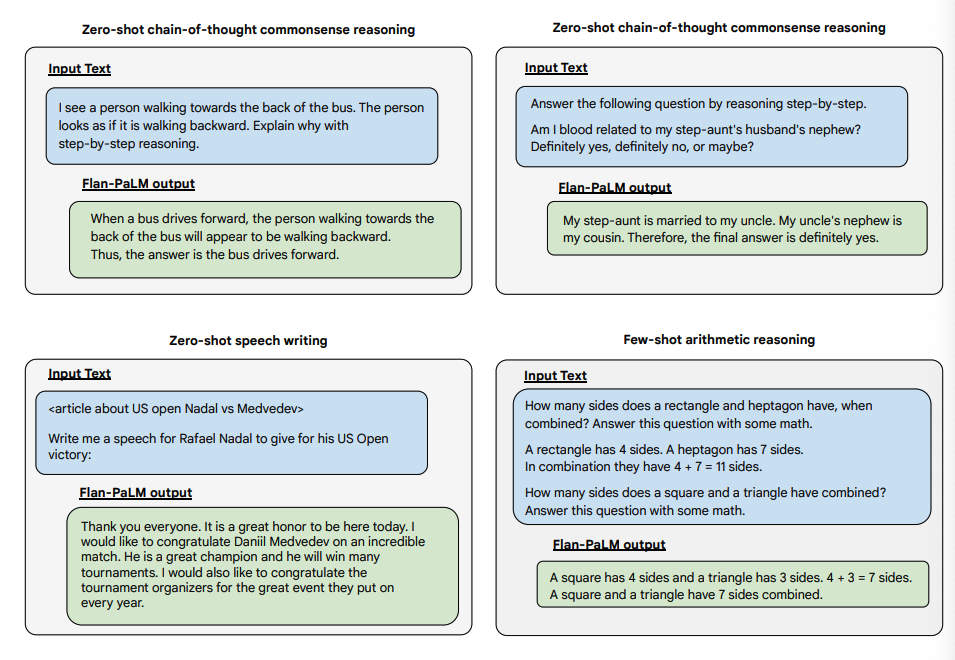
이미지 출처: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Flan-T5 모델 (opens in a new tab)을 Hugging Face Hub에서 사용해보실 수 있습니다.