Multimodal CoT Prompting
Zhang et al. (2023) (opens in a new tab)은 최근 멀티모달 생각의 사슬 프롬프팅(multimodal chain-of-thought prompting) 접근 방식을 제안했습니다. 기존의 CoT는 언어 양식(language modality)에 중점을 둡니다. 반면, 멀티모달 CoT는 텍스트와 이미지를 2단계 프레임워크에 통합합니다. 첫 번째 단계에서는 멀티모달 정보를 기반으로 근거 생성(rationale generation)을 포함합니다. 그 다음에는 두 번째 단계인 답변 추론이 이어지며, 이 단계에서는 생성된 정보적 근거들(informative generated rationales)을 활용하여 답변을 도출합니다.
멀티모달 CoT 모델(1B)은 ScienceQA 벤치마크에서 GPT-3.5보다 성능이 뛰어났습니다.
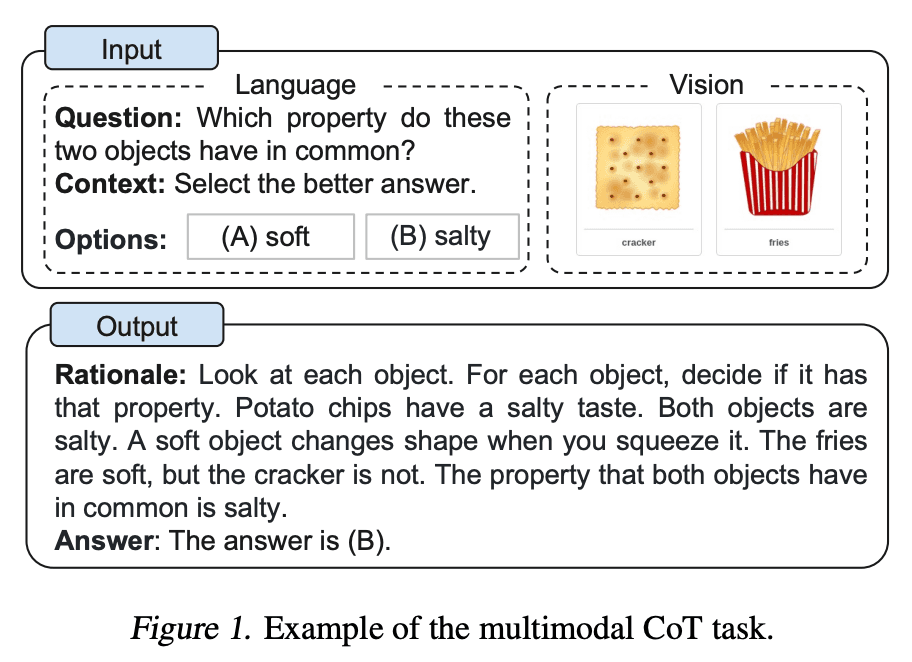
Image Source: Zhang et al. (2023) (opens in a new tab)
더 읽어볼 것: