ReAct 框架
从 Yao 等人,2022 (opens in a new tab) 引入了一个框架,其中 LLMs 以交错的方式生成 推理轨迹 和 任务特定操作 。
生成推理轨迹使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。操作步骤允许与外部源(如知识库或环境)进行交互并且收集信息。
ReAct 框架允许 LLMs 与外部工具交互来获取额外信息,从而给出更可靠和实际的回应。
结果表明,ReAct 可以在语言和决策任务上的表现要高于几个最先进水准要求的的基线。ReAct 还提高了 LLMs 的人类可解释性和可信度。总的来说,作者发现了将 ReAct 和链式思考 (CoT) 结合使用的最好方法是在推理过程同时使用内部知识和获取到的外部信息。
它是如何运作的?
ReAct 的灵感来自于 “行为” 和 “推理” 之间的协同作用,正是这种协同作用使得人类能够学习新任务并做出决策或推理。
链式思考 (CoT) 提示显示了 LLMs 执行推理轨迹以生成涉及算术和常识推理的问题的答案的能力,以及其他任务 (Wei 等人,2022) (opens in a new tab)。但它因缺乏和外部世界的接触或无法更新自己的知识,而导致事实幻觉和错误传播等问题。
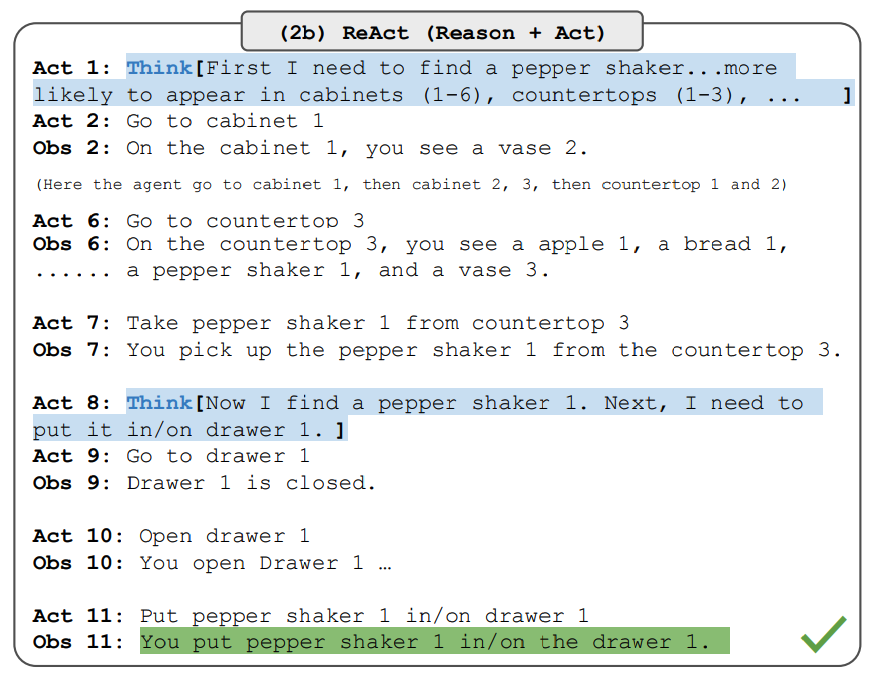
ReAct 是一个将推理和行为与 LLMs 相结合通用的范例。ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。下图展示了 ReAct 的一个示例以及执行问题回答所涉及的不同步骤。

图片来源:Yao等人,2022 (opens in a new tab)
在上面的例子中,我们将如下问题作为提示给出,该问题出自 HotpotQA (opens in a new tab):
除了苹果遥控器,还有哪些设备可以控制苹果遥控器最初设计用来交互的程序?请注意,上下文中的示例也被添加到提示符中,但为了简单起见,我们在这里排除了它。我们可以看到,该模型生成了 “任务解决轨迹” (思考,行动)。Obs 对应与之交互的环境的观察 (例如搜索引擎)。从本质上讲,ReAct 可以检索信息来支持推理,而推理则有助于确定下一步检索的目标。
ReAct 提示
为了更好的阐释 ReAct 提示是如何运作的,我们继续跟随论文的示例。
第一步是从训练集 (例如 HotPotQA) 中选择案例,并组成 ReAct 格式的轨迹。这些在提示中作为少样本示例。轨迹由多思考-操作-观察步骤组成,如图所示。自由形式的思考用来完成不同的任务,如分解问题、提取信息、执行常识或算术推理、引导搜索公式和合成最终答案。
下面是一个 ReAct 提示的示例(摘自论文,为简单起见缩短为一个示例):
问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少?
思考 1 我需要搜索科罗拉多造山带,找到科罗拉多造山带东段延伸的区域,然后找到该区域的海拔范围。
操作 1 搜索 [科罗拉多造山带]
观察 1 科罗拉多造山带是科罗拉多及其周边地区造山运动的一段。
思考 2 它没有提到东部地区。所以我需要查一下东部地区。
操作 2 查找 [东部地区]
观察 2 (结果 1 / 1) 东部区域延伸至高平原,称为中原造山带。
思考 3 科罗拉多造山运动的东部区域延伸到高平原。所以我需要搜索高平原,找到它的海拔范围。
操作 3 搜索 [高平原]
观察 3 高平原指的是两个截然不同的陆地区域之一。
思考 4 我需要搜索高平原(美国)
操作 4 搜索 [高平原(美国)]
观察 4 高平原是大平原的一个分区。从东到西,高平原的海拔从 1800 到 7000 英尺 (550 到 2130 米) 不等。[3]
思考 5 高平原海拔高度从 1800 到 7000 英尺,所以答案是 1800 到 7000 英尺。
操作 5 结束 [1800 到 7000 英尺]
...请注意,不同的提示设置用于不同类型的任务。对那些以推理为主要目标的任务 (例如 HotpotQA),多思考-操作-观察步骤用于任务-解决轨迹。对于涉及许多操作步骤的决策任务来说,则较少使用思考。
在知识密集型任务上的表现结果
论文首先对 ReAct 在知识密集型推理任务如问答 (HotPotQA) 和事实验证 (Fever (opens in a new tab)) 上进行了评估。PaLM-540B 作为提示的基本模型。
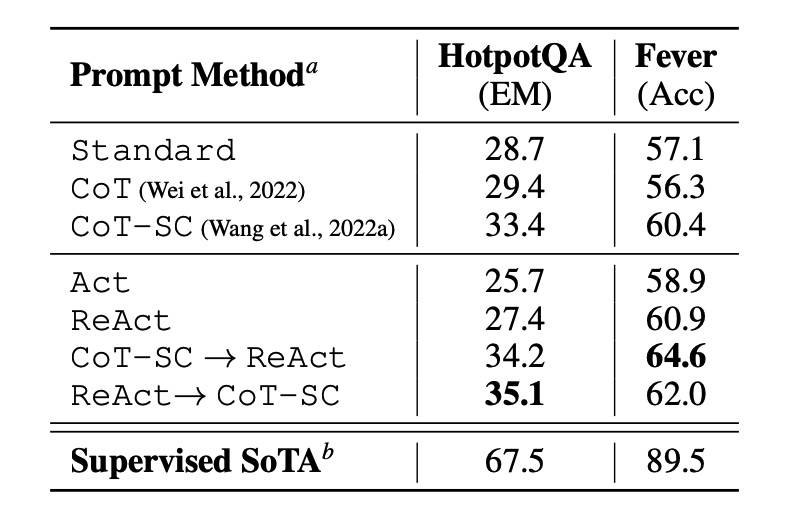
图片来源: Yao et al., 2022 (opens in a new tab)
通过在 HotPotQA 和 Fever 上使用不同提示方法得到的提示的表现结果说明了 ReAct 表现结果通常优于 Act (只涉及操作)。
我们还可以观察到 ReAct 在 Fever 上的表现优于 CoT,而在 HotpotQA 上落后于 CoT。文中对该方法进行了详细的误差分析。总而言之:
- CoT 存在事实幻觉的问题
- ReAct 的结构性约束降低了它在制定推理步骤方面的灵活性
- ReAct 在很大程度上依赖于它正在检索的信息;非信息性搜索结果阻碍了模型推理,并导致难以恢复和重新形成思想
结合并支持在 ReAct 和链式思考+自我一致性之间切换的提示方法通常优于所有其他提示方法。
在决策型任务上的表现结果
论文还给出了 ReAct 在决策型任务上的表现结果。ReAct 基于两个基准进行评估,分别是 ALFWorld (opens in a new tab) (基于文本的游戏) 和 WebShop (opens in a new tab) (在线购物网站环境)。两者都涉及复杂的环境,需要推理才能有效地行动和探索。
请注意,虽然对这些任务的 ReAct 提示的设计有很大不同,但仍然保持了相同的核心思想,即结合推理和行为。下面是一个涉及 ReAct 提示的 ALFWorld 问题示例。
图片来源: Yao et al., 2022 (opens in a new tab)
ReAct 在 ALFWorld 和 Webshop 上都优于 Act。没有思考的 Act 不能正确地把目标分解成子目标。尽管在这些类型的任务中,ReAct 的推理显露出优势,但目前基于提示的方法在这些任务上的表现与人类专家相差甚远。
查看这篇论文了解结果详情。
长链 ReAct 的使用
下面是 ReAct 提示方法在实践中如何工作的高阶示例。我们将在 LLM 和 长链 (opens in a new tab) 中使用OpenAI,因为它已经具有内置功能,可以利用 ReAct 框架构建代理,这些代理能够结合 LLM 和其他多种工具的功能来执行任务。
首先,让我们安装并导入必要的库:
%%capture
# 更新或安装必要的库
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# 引入库
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# 载入 API keys; 如果没有,你需要先获取。
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
现在我们可以配置 LLM,我们要用到的工具,以及允许我们将 ReAct 框架与 LLM 和其他工具结合使用的代理。请注意,我们使用搜索 API 来搜索外部信息,并使用 LLM 作为数学工具。
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)配置好之后,我们就可以用所需的查询或提示运行代理了。请注意,在这里,我们不会像论文中阐释的那样提供少样本的示例。
agent.run("奥利维亚·王尔德的男朋友是谁?他现在的年龄的0.23次方是多少?")链执行如下所示:
> 正在输入新代理执行器链......
我得查出奥利维亚·王尔德的男友是谁然后计算出他的年龄的 0.23 次方。
操作: 搜索
操作输入: “奥利维亚·王尔德的男友”
观察: 奥利维亚·王尔德与杰森·苏代基斯在多年前订婚,在他们分手后,她开始与哈里·斯泰尔斯约会 — 参照他们的关系时间线。
思考: 我需要找出哈里·斯泰尔斯的年龄。
操作: 搜索
操作输入: “哈里·斯泰尔斯的年龄”
观察: 29 岁
思考: 我需要计算 29 的 0.23 次方。
操作: 计算器
操作输入: 29^0.23
观察: 答案: 2.169459462491557
思考: 现在我知道最终答案了。
最终答案: 哈里·斯泰尔斯, 奥利维亚·王尔德的男朋友, 29 岁。他年龄的 0.23 次方是 2.169459462491557。
> 结束链。我们得到如下输出:
"哈里·斯泰尔斯, 奥利维亚·王尔德的男朋友, 29 岁。他年龄的 0.23 次方是 2.169459462491557。"这个例子我们摘自 LangChain 文档 (opens in a new tab) 并修改,所以这些都要归功于他们。我们鼓励学习者去探索工具和任务的不同组合。
您可以在这里找到这些代码: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb (opens in a new tab)