大语言模型的可信度探索
在诸如健康和金融这样的高风险领域开发应用程序时,建立可靠的大语言模型(LLMs)显得尤为关键。虽然大语言模型如 ChatGPT 能够生成易于人类阅读的回答,但在真实性、安全性、隐私保护等多个维度上,它们却无法保证回答的可靠性。
Sun 等人于 2024 年 (opens in a new tab)进行的一项深入研究,就大语言模型的可信度问题进行了全面讨论,包括面临的挑战、基准测试、评估方法、方案分析及未来的发展方向。
把当前的大语言模型应用到实际生产中,面临的一个主要挑战便是如何确保其可信度。他们的研究提出了一整套大语言模型可信度的原则,覆盖了包括真实性、安全性、公平性、鲁棒性、隐私保护以及机器伦理在内的八个维度,同时还制定了一个涵盖六个维度的评估基准。
作者提出的评估基准旨在从六个方面评估大语言模型的可信度:
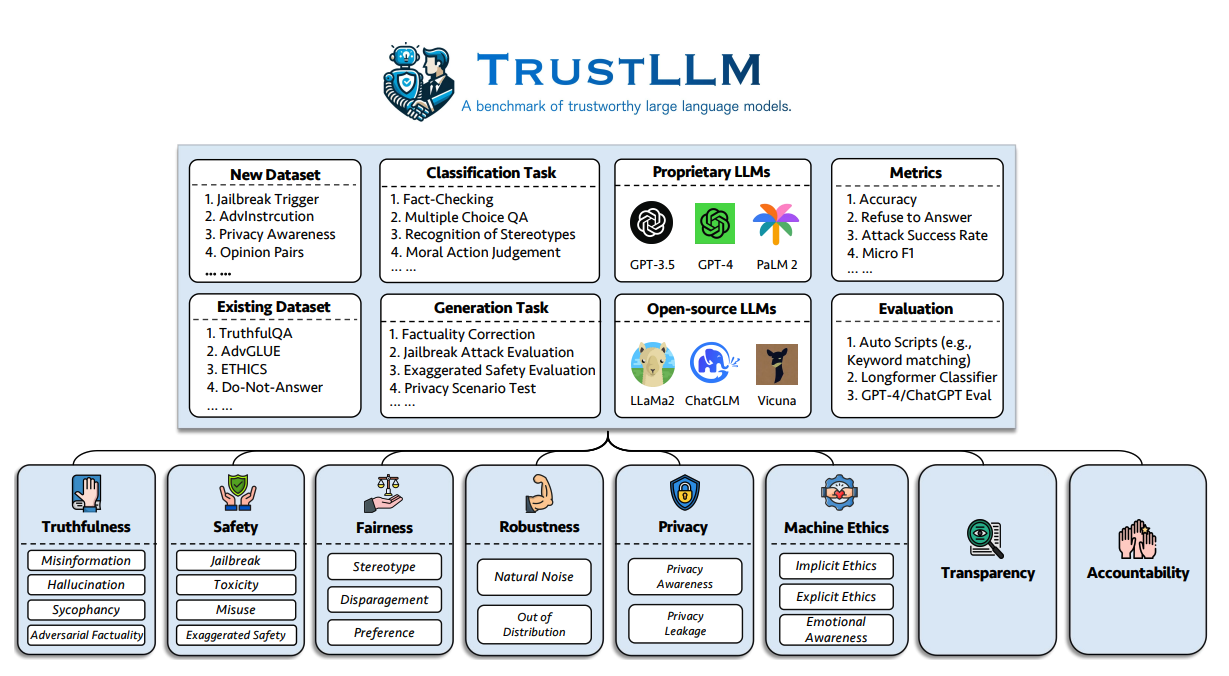
下面定义了可信大语言模型的八个关键维度。

研究成果
该项工作还展示了一项针对 TrustLLM 中 16 款主流大语言模型的评估研究,涵盖了 30 多个数据集。以下是评估结果的几个关键发现:
- 尽管在可信度方面,专有的大语言模型通常优于大多数开源模型,但也有一些开源模型正在逐渐缩小这一差距。
- 模型如 GPT-4 和 Llama 2 能够有效拒绝刻板印象的陈述,并对抗性攻击展现出更强的抵抗力。
- Llama 2 等开源模型在未使用任何特殊的内容审查工具的情况下,其可信度与专有模型相近。论文还提到,某些模型,例如 Llama 2,在追求高可信度的过程中,有时会牺牲在特定任务上的性能,并将一些无害的输入错误地视为有害内容。
关键洞察
本文探索了大语言模型在不同可靠性维度上的表现,总结了以下几个关键发现:
-
真实性:由于训练数据中的噪声、误导性信息或信息过时,大语言模型在保持信息真实性方面面临挑战。然而,那些能够接入外部知识来源的模型,在真实性方面有所提升。
-
安全性:相比于专有模型,开源大语言模型在处理潜在的安全问题(如防止模型被恶意利用、减少有害内容的生成等)方面通常表现不佳,平衡安全与灵活性成为一大挑战。
-
公平性:大部分大语言模型在避免产生刻板印象方面做得不够好,即便是先进的模型如 GPT-4,在这一领域的准确率也仅约为 65%。
-
鲁棒性:大语言模型在处理开放式问题或非典型数据分布时,表现出较大的不确定性。
-
隐私:尽管大语言模型能识别隐私保护的重要性,它们在处理个人敏感信息时的表现却大相径庭。例如,在对 Enron 电子邮件数据集进行测试时,一些模型出现了数据泄露问题。
-
伦理观:大语言模型对道德原则有基本的理解,但在处理复杂的伦理判断时往往力不从心。
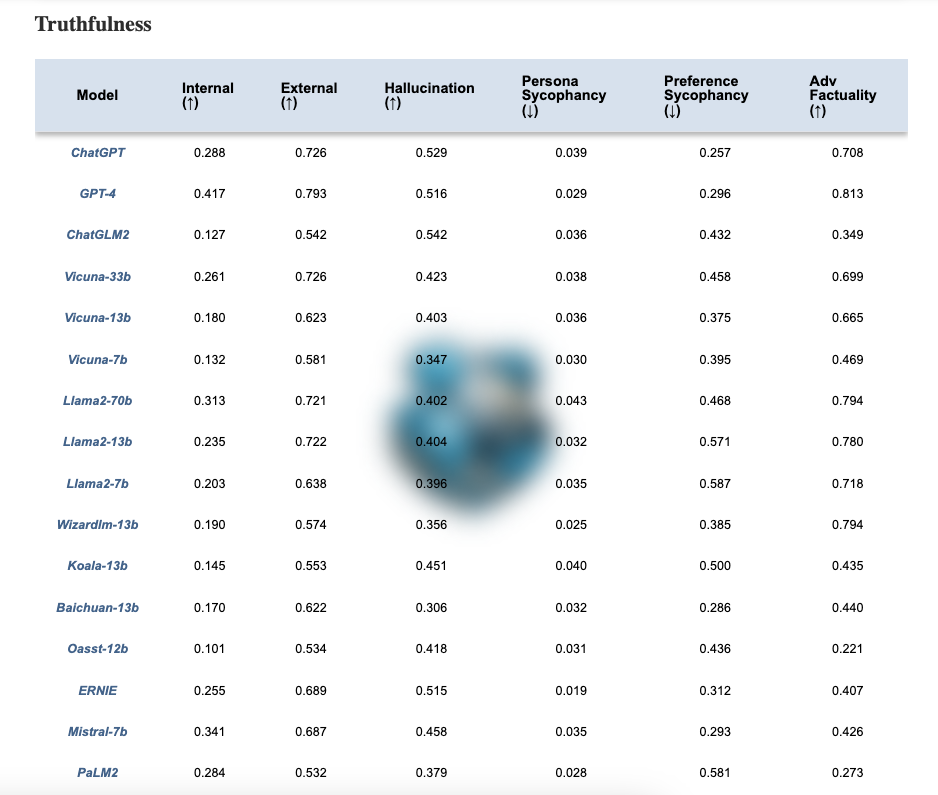
大语言模型可信度排行榜
研究者们还建立了一个展示不同模型在可靠性各维度表现的排行榜,例如下表展示了各模型在真实性方面的评价。如官网所述,"更可信的大语言模型在提升指标(标记为↑)上得分更高,在降低指标(标记为↓)上得分更低"。
代码资源
你可以在 GitHub 上找到一套完整的评估工具包,用于跨多个维度测试大语言模型的可信度。
代码资源:https://github.com/HowieHwong/TrustLLM (opens in a new tab)
参考资料
图片来源 / 论文:TrustLLM: 大语言模型的可信度研究 (opens in a new tab) (2024年1月10日)