Tree of Thoughts (ToT)
Para tarefas complexas que exigem exploração ou planejamento estratégico, técnicas tradicionais ou simples de estímulo são insuficientes. Yao et el. (2023) (opens in a new tab) e Long (2023) (opens in a new tab) propuseram recentemente a "Tree of Thoughts" (ToT), uma estrutura que generaliza o estímulo de cadeia de pensamento e incentiva a exploração de pensamentos que servem como etapas intermediárias para a resolução de problemas gerais com modelos de linguagem.
A ToT mantém uma árvore de pensamentos, onde os pensamentos representam sequências coerentes de linguagem que servem como etapas intermediárias para a resolução de um problema. Essa abordagem permite que um modelo de linguagem (LM) avalie o progresso dos pensamentos intermediários em direção à resolução de um problema por meio de um processo de raciocínio deliberado. A capacidade do LM de gerar e avaliar pensamentos é combinada com algoritmos de busca (por exemplo, busca em largura e busca em profundidade) para permitir a exploração sistemática de pensamentos com planejamento de lookahead e retrocesso.
A estrutura ToT é ilustrada abaixo:
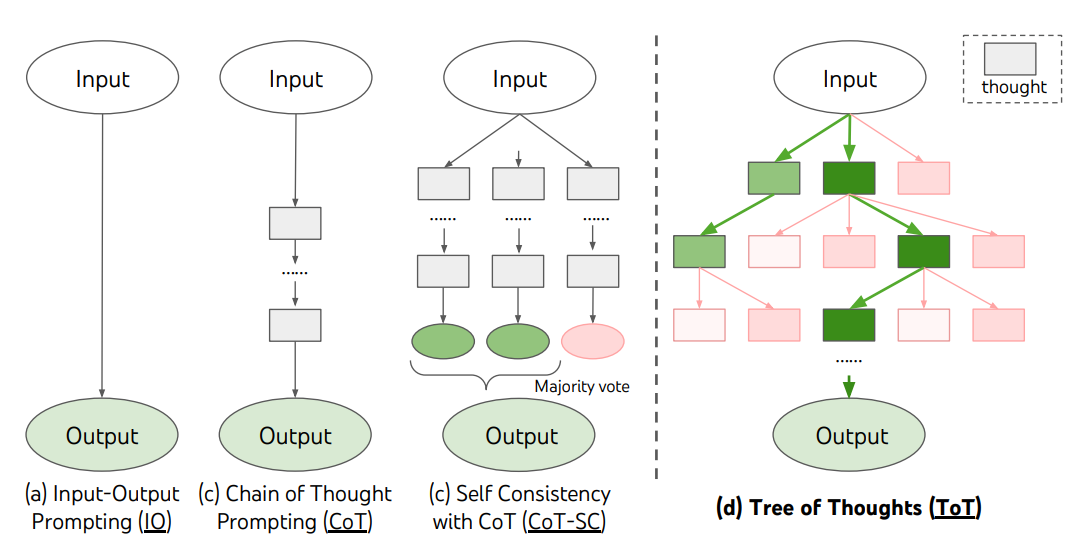
Fonte da imagem: Yao et el. (2023) (opens in a new tab)
Ao usar a ToT, tarefas diferentes requerem a definição do número de candidatos e o número de pensamentos/etapas. Por exemplo, como demonstrado no artigo, o jogo "Game of 24" é usado como uma tarefa de raciocínio matemático que exige a decomposição dos pensamentos em 3 etapas, cada uma envolvendo uma equação intermediária. Em cada etapa, os 5 melhores candidatos são mantidos (b=5).
Para realizar a busca em largura (BFS) na ToT para a tarefa "Game of 24", o LM é solicitado a avaliar cada candidato de pensamento como "certo/talvez/impossível" em relação à obtenção do valor 24. Conforme afirmado pelos autores, "o objetivo é promover soluções parciais corretas que podem ser julgadas com poucas tentativas de planejamento futuro e eliminar soluções parciais impossíveis com base em senso comum de 'muito grande/pequeno', mantendo o restante como 'talvez'". Os valores são amostrados 3 vezes para cada pensamento. O processo é ilustrado abaixo:
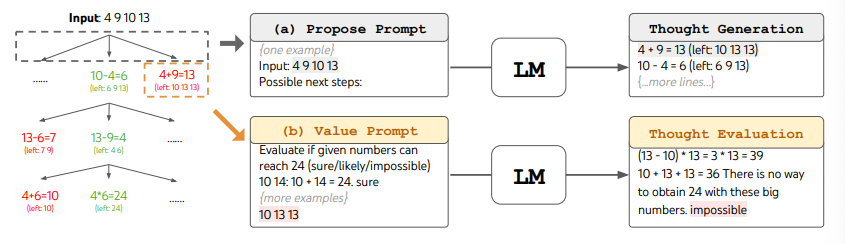
Fonte da imagem: Yao et el. (2023) (opens in a new tab)
Pelos resultados relatados na figura abaixo, a ToT supera substancialmente os outros métodos de estímulo:
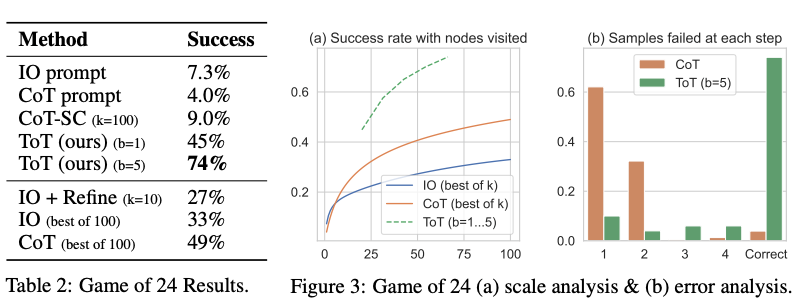
Fonte da imagem: Yao et el. (2023) (opens in a new tab)
Código disponível aqui (opens in a new tab) e aqui (opens in a new tab)
Em um nível mais amplo, as principais ideias de Yao et el. (2023) (opens in a new tab) e Long (2023) (opens in a new tab) são semelhantes. Ambos melhoram a capacidade do LLM para a resolução de problemas complexos por meio da busca em árvore via uma conversa em várias rodadas. Uma das principais diferenças é que Yao et el. (2023) (opens in a new tab) utiliza busca em profundidade (DFS), busca em largura (BFS) e busca em feixe (beam search), enquanto a estratégia de busca em árvore (ou seja, quando retroceder e retroceder em quantos níveis, etc.) proposta por Long (2023) (opens in a new tab) é conduzida por um "Controlador ToT" treinado por meio de aprendizado por reforço. DFS/BFS/Beam search são estratégias genéricas de busca por soluções sem adaptação a problemas específicos. Em comparação, um Controlador ToT treinado por RL pode ser capaz de aprender a partir de novos conjuntos de dados ou por meio de autoaprendizagem (AlphaGo vs. busca por força bruta), permitindo que o sistema ToT baseado em RL continue a evoluir e aprender novos conhecimentos, mesmo com um LLM fixo.
Hulbert (2023) (opens in a new tab) propôs o "Tree-of-Thought Prompting", que aplica o conceito principal das estruturas ToT como uma técnica simples de estímulo, fazendo com que o LLM avalie pensamentos intermediários em uma única prompt. Uma amostra de prompt ToT é:
Imagine que três especialistas diferentes estão respondendo a esta pergunta.
Todos os especialistas escreverão 1 etapa do seu pensamento e compartilharão com o grupo.
Então, todos os especialistas passarão para a próxima etapa, etc.
Se algum especialista perceber que está errado em algum ponto, ele sairá.
A pergunta é...