Escalando modelos de linguagem com ajuste fino de instrução
O que há de novo?
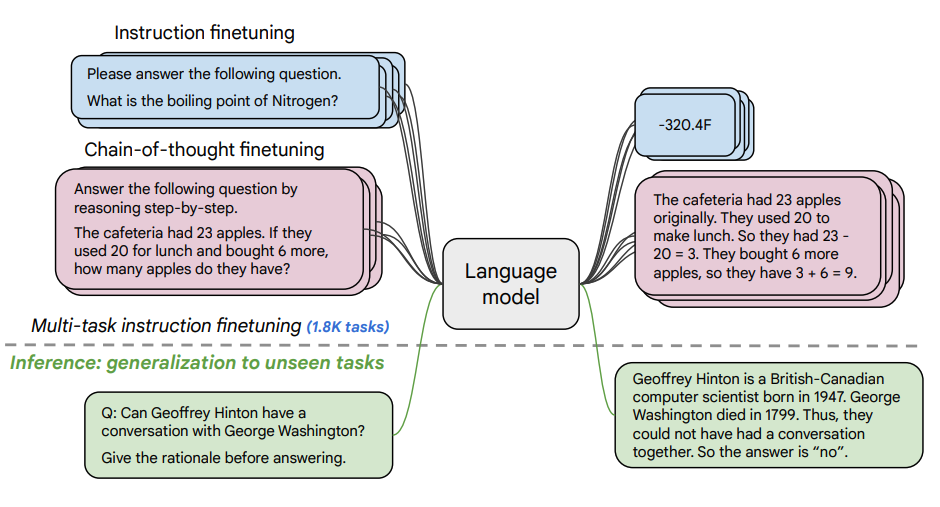
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Este artigo explora os benefícios do dimensionamento ajuste fino de instrução (opens in a new tab) e como ele melhora o desempenho em uma variedade de modelos (PaLM, T5), solicitando configurações (zero-shot, poucos- shot, CoT) e benchmarks (MMLU, TyDiQA). Isso é explorado com os seguintes aspectos: dimensionar o número de tarefas (1,8 mil tarefas), dimensionar o tamanho do modelo e ajustar os dados da cadeia de pensamento (9 conjuntos de dados usados).
Procedimento de ajuste fino:
- Tarefas de 1,8K foram formuladas como instruções e usadas para ajustar o modelo
- Usa com e sem exemplares, e com e sem CoT
Tarefas de ajuste fino e tarefas estendidas mostradas abaixo:
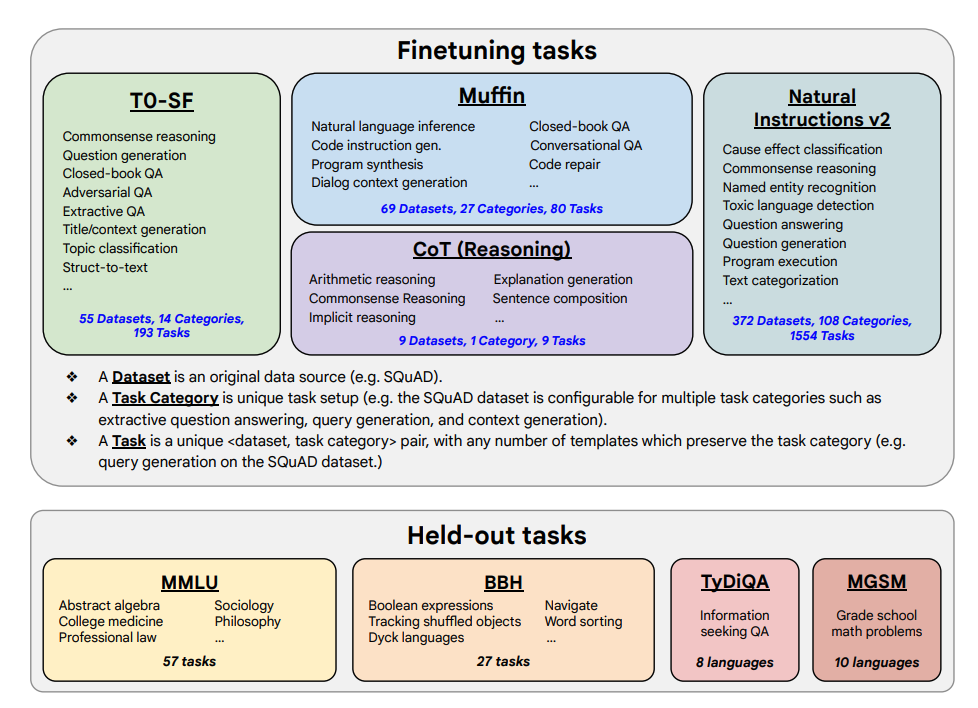
Capacidades e Principais Resultados
- Escalas de ajuste fino de instrução com o número de tarefas e o tamanho do modelo; isso sugere a necessidade de dimensionar ainda mais o número de tarefas e o tamanho do modelo
- Adicionar conjuntos de dados CoT ao ajuste fino permite um bom desempenho em tarefas de raciocínio
- Flan-PaLM melhorou as habilidades multilíngues; Melhoria de 14,9% em TyDiQA one-shot; Melhoria de 8,1% no raciocínio aritmético em idiomas sub-representados
- O Plan-PaLM também tem um bom desempenho em perguntas de geração aberta, o que é um bom indicador para melhorar a usabilidade
- Melhora o desempenho em benchmarks de IA responsável (RAI)
- Os modelos ajustados por instrução Flan-T5 demonstram fortes recursos de poucos disparos e superam o ponto de verificação público, como o T5
Os resultados ao dimensionar o número de tarefas de ajuste fino e o tamanho do modelo: dimensionar o tamanho do modelo e o número de tarefas de ajuste fino deve continuar melhorando o desempenho, embora o dimensionamento do número de tarefas tenha diminuído os retornos.
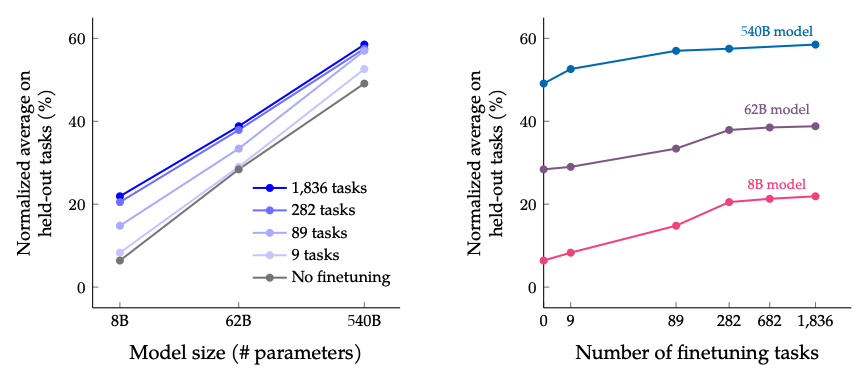
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Os resultados do ajuste fino com dados não-CoT e CoT: O ajuste fino conjunto em dados não-CoT e CoT melhora o desempenho em ambas as avaliações, em comparação com o ajuste fino em apenas um ou outro.
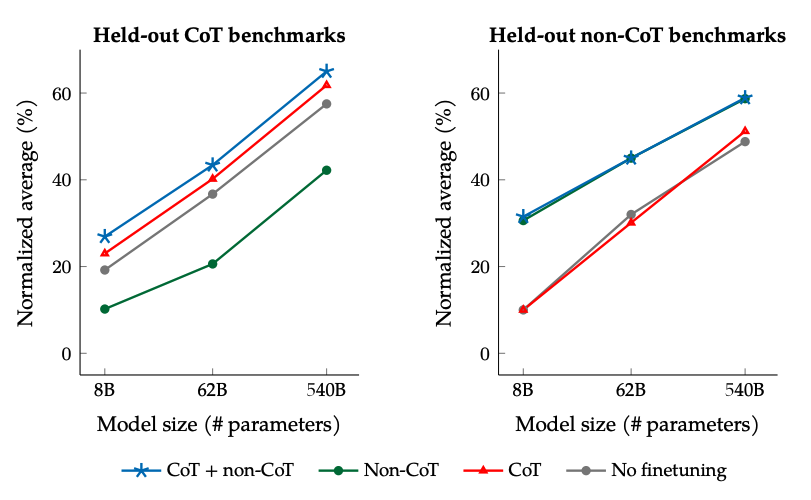
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Além disso, a autoconsistência combinada com o CoT alcança resultados SoTA em vários benchmarks. CoT + autoconsistência também melhora significativamente os resultados em benchmarks envolvendo problemas matemáticos (por exemplo, MGSM, GSM8K).
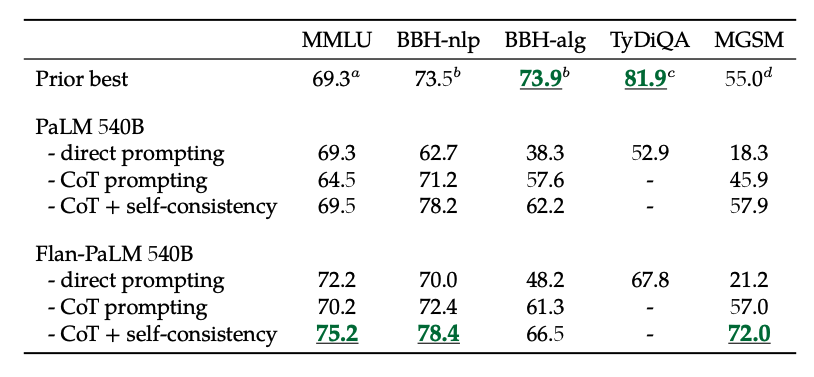
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
O ajuste fino do CoT desbloqueia o raciocínio zero-shot, ativado pela frase "vamos pensar passo a passo", em tarefas do BIG-Bench. Em geral, o CoT Flan-PaLM zero-shot supera o CoT PaLM zero-shot sem ajuste fino.
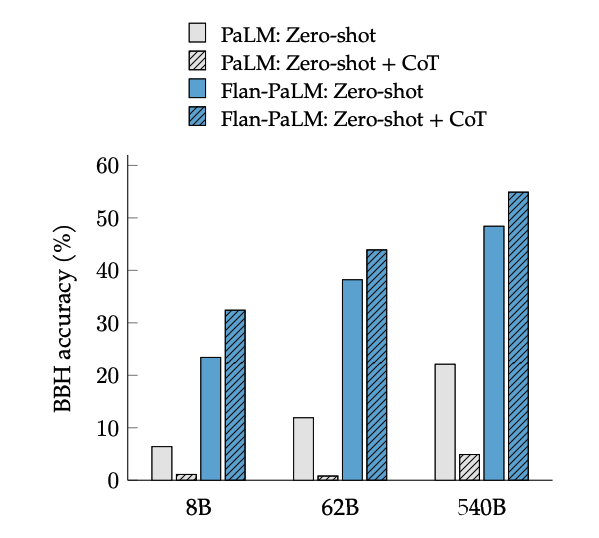
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Abaixo estão algumas demonstrações de CoT zero-shot para PaLM e Flan-PaLM em tarefas não vistas.
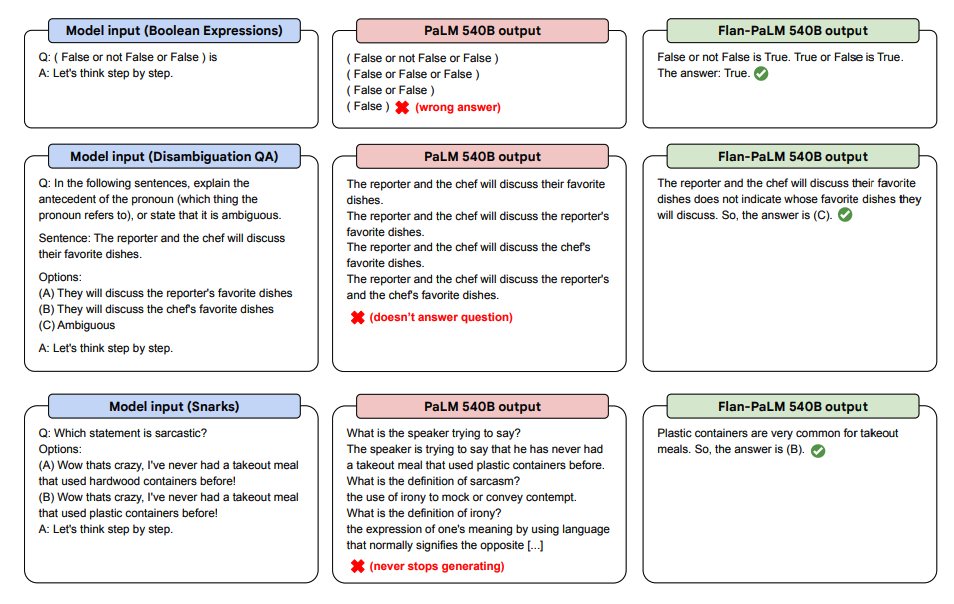
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Abaixo estão mais exemplos de prompts zero-shot. Ele mostra como o modelo PaLM luta com repetições e não responde a instruções na configuração de tiro zero, onde o Flan-PaLM é capaz de ter um bom desempenho. Exemplares de poucos tiros podem mitigar esses erros.
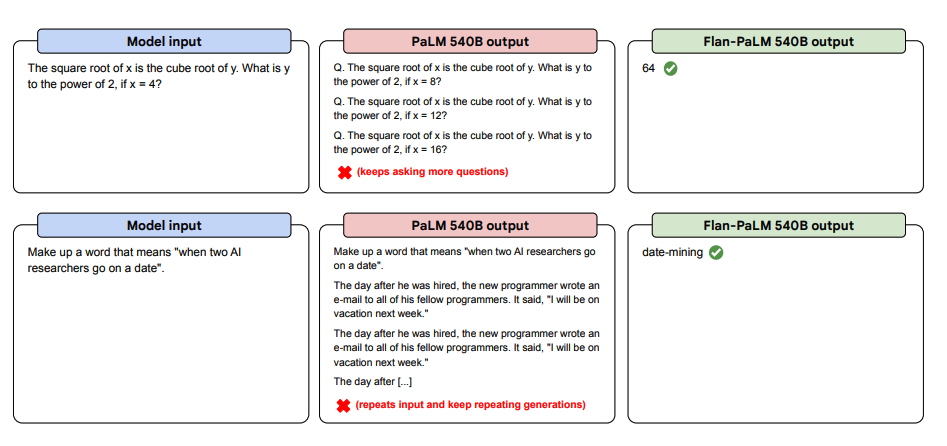
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Abaixo estão alguns exemplos que demonstram mais capacidades de tiro zero do modelo Flan-PALM em vários tipos diferentes de perguntas abertas desafiadoras:
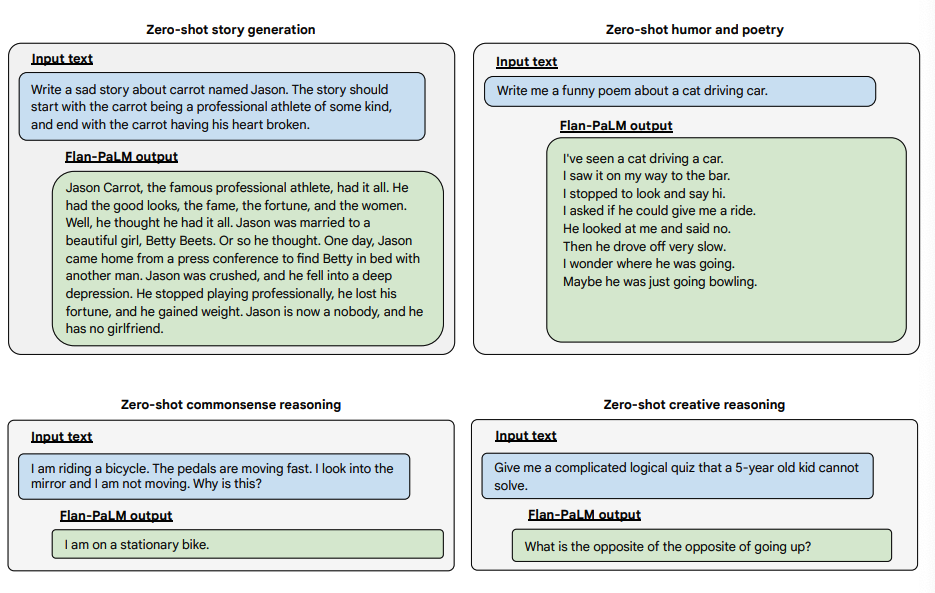
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
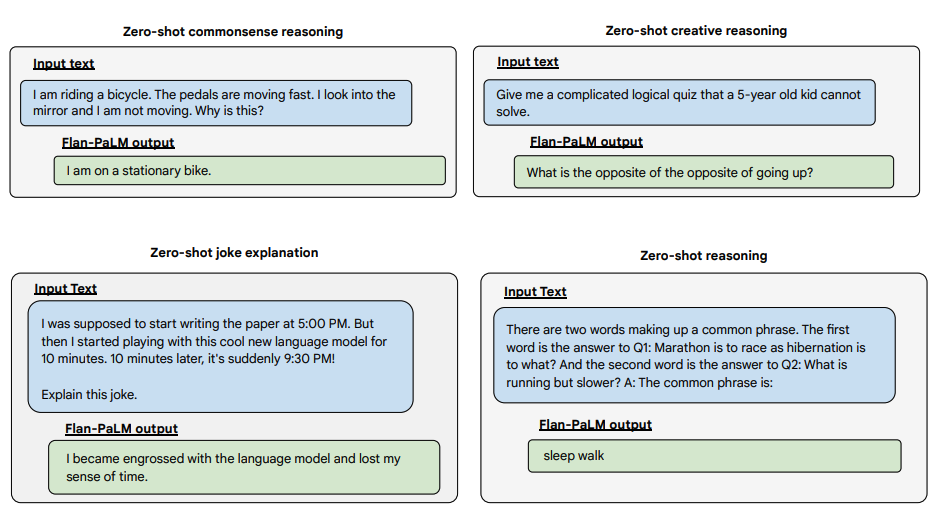
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
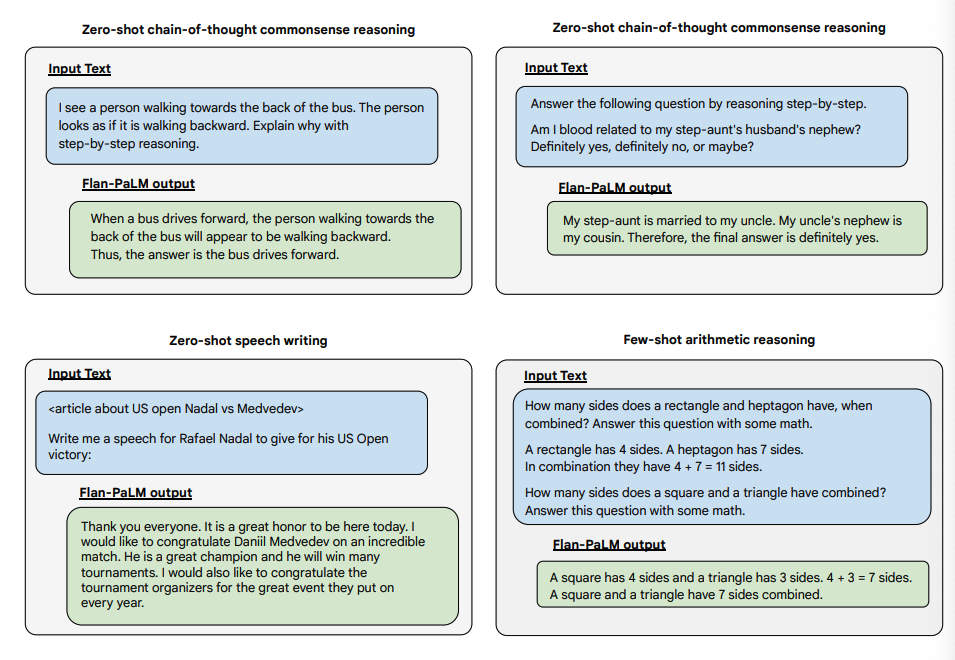
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Você pode experimentar modelos Flan-T5 no Hugging Face Hub (opens in a new tab).