Tree of Thoughts (ToT)
複雑な課題に対して、探索や戦略的な先読みが必要な場合、従来の単純なプロンプト技術では不十分です。Yao et el. (2023) (opens in a new tab)とLong (2023) (opens in a new tab)は最近、思考の木(Tree of Thoughts、ToT)というフレームワークを提案しました。これは、言語モデルを用いた一般的な問題解決のための中間ステップとして機能する思考の探求を促進するものです。
ToTは、思考が問題解決への中間ステップとなる一貫した言語の連続を表す思考の木を保持します。このアプローチにより、LMは熟考プロセスを通じて中間の思考の達成度を自己評価することが可能です。思考の生成と評価能力は、探索アルゴリズム(例:幅優先探索や深さ優先探索)と組み合わされ、先読みとバックトラッキングを伴う思考の系統的な探求を可能にします。
ToTフレームワークを以下に示します:
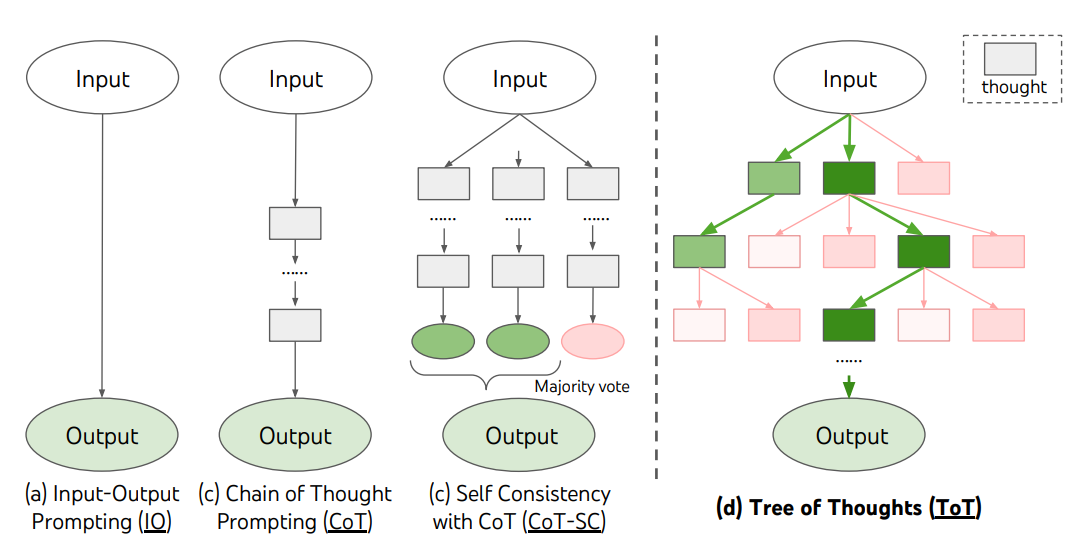
Image Source: Yao et el. (2023) (opens in a new tab)
ToTを使用する際には、異なるタスクにおいて候補の数と思考/ステップの数を定義する必要があります。例えば、論文で示されているように、24ゲームは数学的な推論タスクとして使用され、思考を3つのステップに分解し、それぞれが中間の式を含みます。各ステップでは、最も優れたb=5個の候補が保持されます。
24ゲームのタスクでToTでBFSを実行する場合、LMは各思考候補を24に到達するための「確実/おそらく/不可能」として評価するようにプロンプトされます。著者によれば、「目的は、先読みの試行回数が少ない内に判定可能な正しい部分解を促進し、「大きすぎる/小さすぎる」という常識に基づいた不可能な部分解を排除し、残りの部分解を「おそらく」に保つことです。各思考について値は3回サンプリングされます。このプロセスを以下に示します:
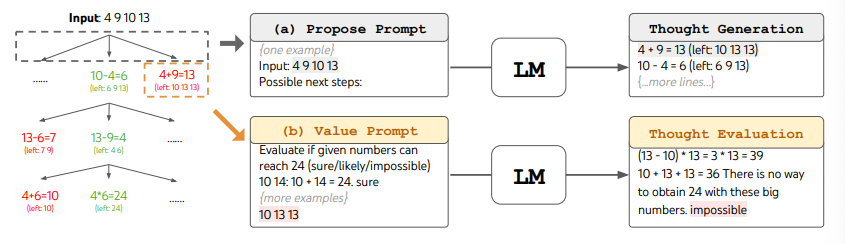
Image Source: Yao et el. (2023) (opens in a new tab)
以下の図に報告されている結果からもわかるように、ToTは他のプロンプト手法に比べて大幅に優れています。
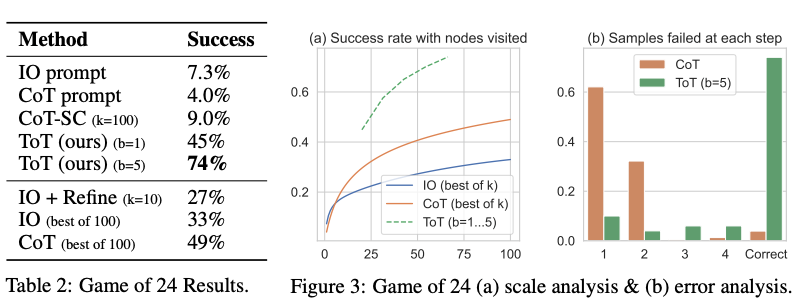
Image Source: Yao et el. (2023) (opens in a new tab)
Code available here (opens in a new tab) and here (opens in a new tab)
Yao et al. (2023) (opens in a new tab)とLong (2023) (opens in a new tab)の主なアイデアは、高いレベルでは似ています。両者とも、マルチラウンドの対話を通じた木探索よって、複雑な問題解決能力を向上させます。主な違いの一つは、Yao et al. (2023) (opens in a new tab)がDFS/BFS/ビームサーチを活用しているのに対し、Long (2023) (opens in a new tab)で提案されている木探索戦略(いつバックトラックするか、バックトラックするレベルなど)は、「ToTコントローラー」と呼ばれる強化学習によって訓練されたモデルによって制御されます。DFS/BFS/ビームサーチは、特定の問題に適応されるわけではない一般的な解探索戦略です。一方、強化学習を用いて訓練されたToTコントローラーは、新しいデータセットやセルフプレイ(AlphaGo対ブルートフォース探索)から学習することができ、したがって、固定されたLLMでもRLベースのToTシステムは進化し、新しい知識を学び続けることができる可能性があります。
Hulbert (2023) (opens in a new tab)は、ToTフレームワークの主要なコンセプトを単純なプロンプト技術として適用する「Tree-of-Thought Prompting」を提案しました。これにより、LLMは単一のプロンプトで中間思考を評価することができます。サンプルのToTプロンプトは以下の通りです:
この質問について、3人の異なる専門家が回答していると想像してください。
すべての専門家は、自分の思考の1つのステップを書き留め、
それをグループと共有します。
その後、すべての専門家は次のステップに進みます。以後同様です。
もし専門家の中に、いかなる時点で誤りに気づいた場合は、退場します。
質問は...