検索により強化された生成 (RAG)
汎用の言語モデルは、感情分析や名前付きエンティティ認識など、いくつかの一般的なタスクを達成するためにファインチューニングすることができます。これらのタスクは一般的に、追加の背景知識を必要としません。
より複雑で知識集約的なタスクの場合、タスクを完遂するために外部の知識ソースにアクセスする言語モデルベースのシステムを構築することができます。これによって、より事実との整合性を向上させ、生成される回答の信頼性が向上し、「幻覚(hallucination)」の問題を軽減することができます。
Meta AI の研究者は、このような知識集約型のタスクに対処するために、RAG(Retrieval Augmented Generation) (opens in a new tab)と呼ばれる手法を考案しました。RAG は情報検索コンポーネントとテキスト生成モデルを組み合わせたものです RAG はファインチューニングが可能で、モデル全体の再トレーニングを必要とせず、効率的な方法で内部の知識を変更することができます。
RAG は入力を受け取り、ソース(例えばウィキペディア)が与えられた関連/証拠立てる文書の集合を検索します。文書は文脈として元の入力プロンプトと連結され、最終的な出力を生成するテキストジェネレータに供給されます。これにより RAG は、事実が時間とともに変化するような状況にも適応できます。LLM のパラメトリック知識は静的であるため、これは非常に有用です。RAG は言語モデルが再学習を回避することを可能にし、検索ベースの(文章)生成によって信頼性の高い出力を生成するための最新情報へのアクセスを可能にします。
Lewis ら(2021)は、RAG のための汎用的なファインチューニングのレシピを提案しました。事前に訓練された seq2seq モデルがパラメトリックメモリとして使用され、ウィキペディアの密なベクトルインデックスが(ニューラルで事前に訓練された retriever を使用してアクセスされた)ノンパラメトリックメモリとして使用されます。以下は、このアプローチがどのように機能するかの概要です:
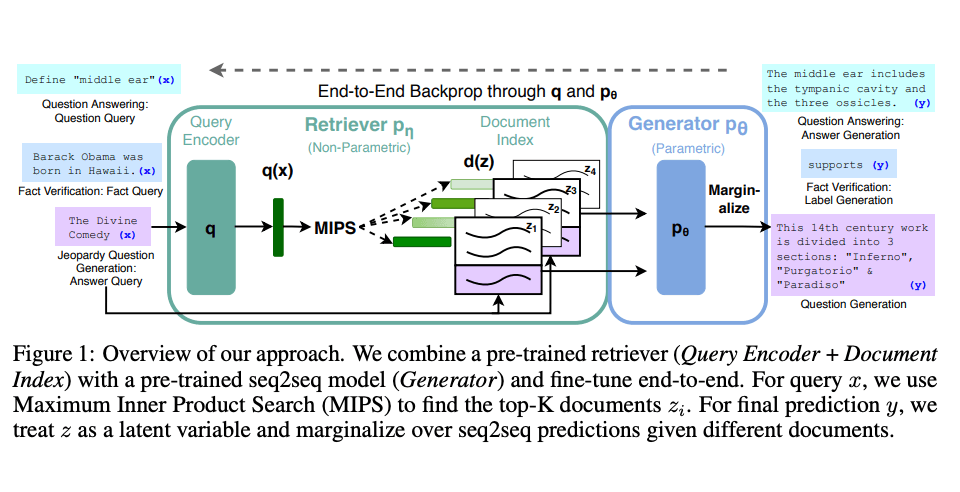
Image Source: Lewis ら (2021) (opens in a new tab)
RAG は、Natural Questions (opens in a new tab)、WebQuestions (opens in a new tab)、CuratedTrec などのいくつかのベンチマークで強力なパフォーマンスを発揮します。RAG は、MS-MARCO や Jeopardy の問題でテストされた場合、より事実に基づいた、具体的で多様な回答を生成します。RAG はまた、FEVER の事実検証の結果を向上させます。
これは、知識集約的なタスクにおける言語モデルの出力を強化するための実行可能なオプションとしての RAG の可能性を示しています。
最近では、このような retriever のアプローチがより一般的になり、ChatGPT のような一般的な LLM と組み合わせることで、能力と事実との整合性を向上させています。
LangChain のドキュメントには、ソースを使って質問に答えるための retriever と LLM の簡単な使用例 (opens in a new tab)が掲載されています。