LLaMA: オープンで効率的な基礎言語モデル
⚠️
このセクションは現在開発中です。
What's new?
本稿では、7Bから65Bパラメータの基礎言語モデルのコレクションを紹介します。
このモデルは、公開されているデータセットを用いて何兆ものトークンでトレーニングしました。
(Hoffman et al. 2022) (opens in a new tab)は、計算予算があれば、より小さいモデルがより多くのデータで訓練された場合、より大きなモデルよりも優れたパフォーマンスを達成できる可能性が示されています。この研究では、10Bモデルを2000億トークンで訓練することを推奨しています。しかし、LLaMA論文では、7Bモデルのパフォーマンスが1兆トークンを超えても改善し続けることが示されています。
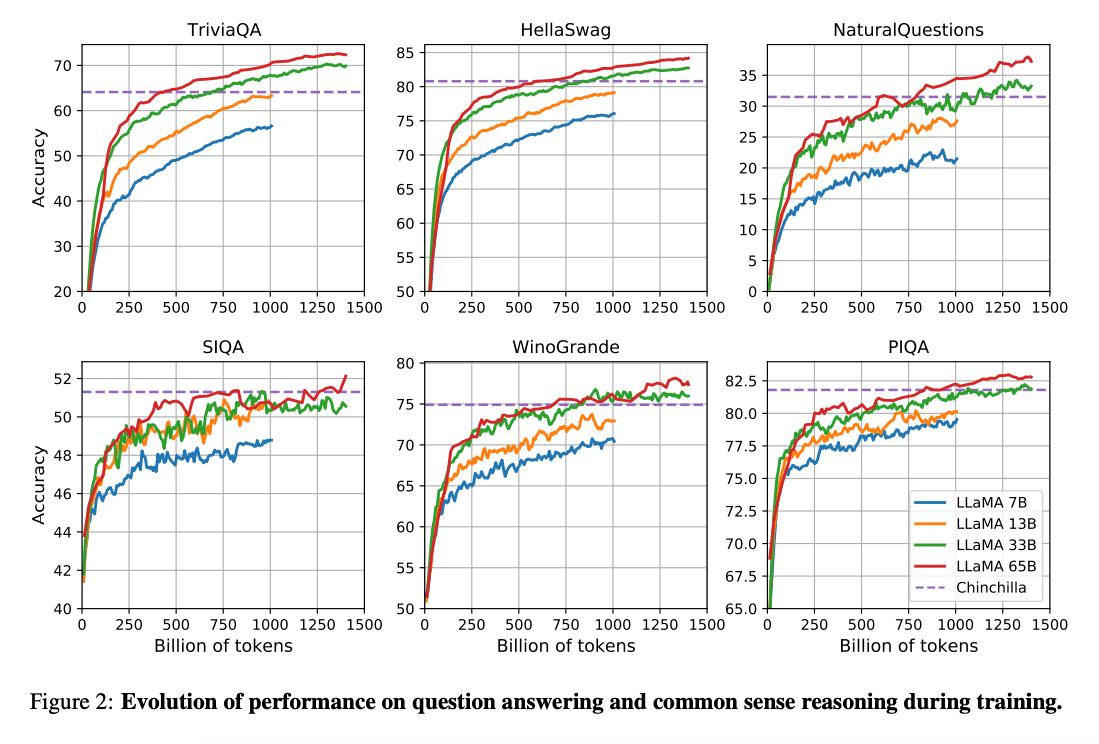
この研究では、より多くのトークンでトレーニングすることで、様々な推論予算で最高の性能を達成する言語モデル(LLaMa)をトレーニングすることに焦点を当てています。
性能と主な結果
全体として、LLaMA-13Bは10倍小さく、シングルGPUで動作可能でありながら、多くのベンチマークでGPT-3(175B)を上回りました。LLaMA 65BからChinchilla-70BやPaLM-540Bなどのモデルと競争力を持っています。
Paper: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Code: https://github.com/facebookresearch/llama (opens in a new tab)
参考文献
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (March 2023)
- GPT4All (opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (March 2023)
- Stanford Alpaca (opens in a new tab) (March 2023)