Düşünce Ağacı (ToT)
Keşif veya stratejik öngörü gerektiren karmaşık görevlerde, geleneksel veya basit istem teknikleri yetersiz kalır. Yao ve diğerleri (2023) (opens in a new tab) ve Long (2023) (opens in a new tab) son zamanlarda Düşünce Ağacı (ToT) adlı bir çerçeve önermiştir. Bu çerçeve, dil modelleri ile genel problem çözme adımlarına hizmet eden düşünceler üzerinde keşif yapmayı teşvik eden düşünce zinciri istemine genel bir bakış sağlar.
ToT, düşüncelerin bir problemi çözmeye yönelik ara tutamak adımlar olarak hizmet eden tutarlı dil dizilerini temsil ettiği bir düşünce ağacını sürdürür. Bu yaklaşım, bir LM'in bir problemi çözmeye yönelik ara düşüncelerdeki ilerlemeyi dikkatli bir akıl yürütme süreci ile değerlendirmesine olanak sağlar. LM'in düşünceleri oluşturma ve değerlendirme yeteneği, öngörü ve geriye gitme ile düşüncelerin sistematik keşfine olanak sağlamak için arama algoritmaları (ör. genişlik-öncelikli arama ve derinlik-öncelikli arama) ile birleştirilir.
ToT çerçevesi aşağıda gösterilmiştir:
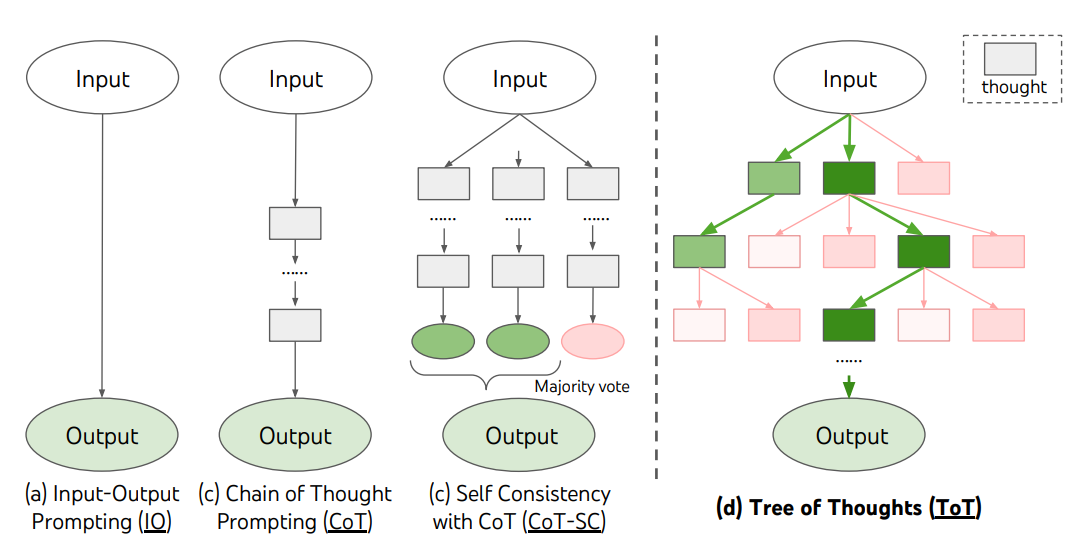
Görüntü Kaynağı: Yao ve diğerleri (2023) (opens in a new tab)
ToT'yi kullanırken, farklı görevler aday sayısını ve düşünce/adım sayısını tanımlamayı gerektirir. Örneğin, makalede gösterildiği üzere, 24 Oyunu, düşünceleri her biri ara bir denklem içeren 3 adıma ayırmayı gerektiren bir matematiksel akıl yürütme görevi olarak kullanılmıştır. Her adımda en iyi b=5 aday korunmuştur.
24 Oyunu görevi için ToT'de BFS performansını gerçekleştirmek için, LM istendiğinde her düşünce adayını 24'e ulaşma konusunda "emin/muhtemelen/imkansız" olarak değerlendirir. Yazarlara göre, "amac, az sayıda öngörü denemesi içinde yargıya varılabilen doğru kısmi çözümleri teşvik etmek, "çok büyük/küçük" sağduyu temelinde imkansız kısmi çözümleri elemek ve geri kalan "muhtemelen"leri korumaktır". Her düşünce için değerler 3 kez örneklendirilir. Süreç aşağıda gösterilmiştir:
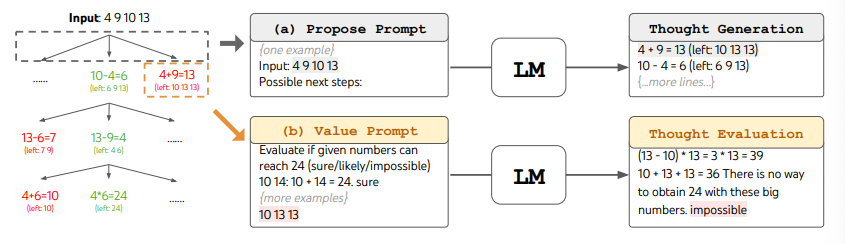
Görüntü Kaynağı: Yao ve diğerleri (2023) (opens in a new tab)
Aşağıdaki figürde rapor edilen sonuçlardan, ToT diğer istem yöntemlerini önemli ölçüde aşmaktadır:
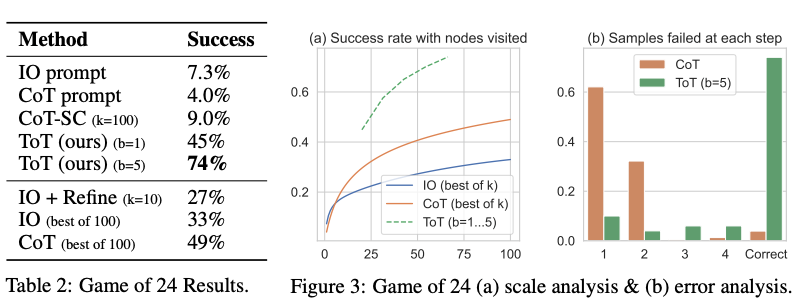
Görüntü Kaynağı: Yao ve diğerleri (2023) (opens in a new tab)
Koda buradan (opens in a new tab) ve buradan (opens in a new tab) ulaşılabilir.
Genel olarak, Yao ve diğerleri (2023) (opens in a new tab) ve Long (2023) (opens in a new tab) 'ın başlıca fikirleri benzerdir. Her ikisi de ağaç araması aracılığıyla bir çok tur konuşma yoluyla LLM'nin karmaşık problem çözme yeteneğini artırır. Ana fark, Yao ve diğerleri (2023) (opens in a new tab) 'in DFS/BFS/ışın aramasını kullanırken, Long (2023) (opens in a new tab) 'da önerilen ağaç arama stratejisi (yani ne zaman geriye dönülüp ve kaç seviye geriye gidileceği vb.) bir "ToT Controller" üzerinden pekiştirmeli öğrenme ile kontrol edilir. DFS/BFS/Beam arama, spesifik problemlere uyum sağlamayan genel çözüm arama stratejileridir. Buna karşın, RL aracılığıyla eğitilmiş bir ToT Denetleyicisi, yeni bir veri setinden veya kendiliğinden oynanan oyunlar (AlphaGo vs kaba kuvvet arama) üzerinden öğrenebilir ve bu nedenle RL tabanlı ToT sistemi, sabit bir LLM ile bile gelişmeye devam edebilir ve yeni bilgi öğrenebilir.
Hulbert (2023) (opens in a new tab) Düşünce-Ağacı İstemi önerdi, bu yöntem ToT çerçevelerinden ana fikri basit bir istem tekniği olarak uygular ve LLM'lerin tek bir istemde ara düşünceleri değerlendirmesini sağlar. Bir örnek ToT istemi şöyledir:
Bu soruyu cevaplandıran üç farklı uzmanı hayal edin.
Tüm uzmanlar düşünmelerinin 1 adımını yazar,
sonra bunu grupla paylaşır.
Sonra tüm uzmanlar bir sonraki adıma geçer, vb.
Eğer herhangi bir uzman herhangi bir noktada hatalı olduğunu fark ederse, o kişi ayrılır.
Soru şu...