Retrieval Augmented Generation (RAG)
I modelli di linguaggio di uso generale possono essere messi a punto per svolgere diversi compiti comuni come l'analisi del sentimento e il riconoscimento delle entità denominate. Questi compiti generalmente non richiedono conoscenze di base aggiuntive.
Per compiti più complessi e che richiedono molte conoscenze, è possibile costruire un sistema basato su un modello di linguaggio che acceda a fonti di conoscenza esterne per completare i compiti. Questo consente una maggiore coerenza dei fatti, migliora l'affidabilità delle risposte generate e aiuta a mitigare il problema dell'"allucinazione".
I ricercatori di Meta AI hanno introdotto un metodo chiamato Generazione potenziata dal recupero (RAG) (opens in a new tab) per affrontare tali compiti che richiedono molte conoscenze. RAG combina una componente di recupero delle informazioni con un modello generatore di testo. RAG può essere perfezionato e la sua conoscenza interna può essere modificata in modo efficiente e senza la necessità di riaddestrare l'intero modello.
RAG prende un input e recupera un insieme di documenti rilevanti/supportanti dati da una fonte (ad esempio, Wikipedia). I documenti vengono concatenati come contesto con il prompt di input originale e inviati al generatore di testo che produce l'output finale. Questo rende RAG adattivo per situazioni in cui i fatti potrebbero evolvere nel tempo. Questo è molto utile poiché la conoscenza parametrica degli LLM è statica. RAG consente ai modelli di linguaggio di bypassare il riaddestramento, consentendo l'accesso alle informazioni più recenti per generare output affidabili attraverso la generazione basata sul recupero (delle informazioni).
Lewis et al., (2021) hanno proposto una ricetta generale per il perfezionamento di RAG. Un modello seq2seq pre-addestrato viene utilizzato come memoria parametrica e un indice vettoriale denso di Wikipedia viene utilizzato come memoria non parametrica (accessibile tramite un modulo di recupero neurale pre-addestrato). Di seguito è riportata una panoramica di come funziona l'approccio:
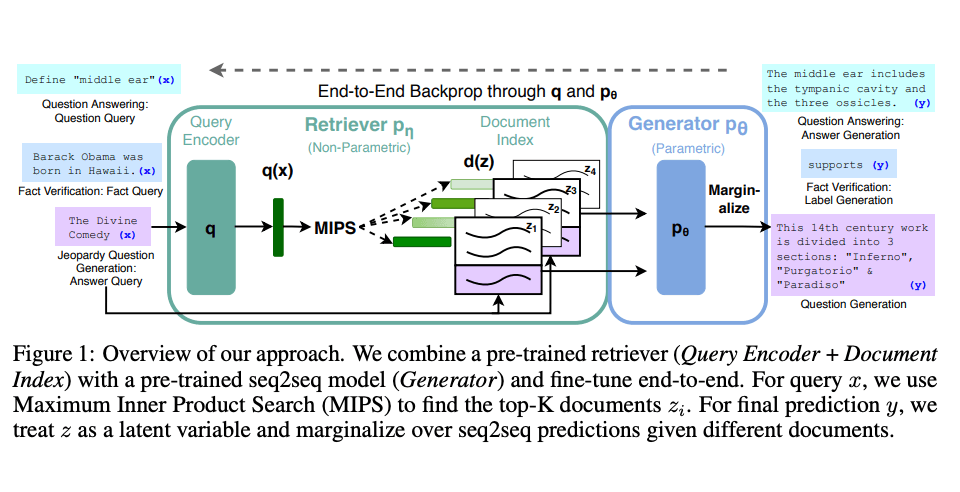
Fonte immagine: Lewis et al. (2021) (opens in a new tab)
RAG ha ottenuto ottimi risultati su diversi benchmark come Natural Questions (opens in a new tab), WebQuestions (opens in a new tab), e CuratedTrec. RAG genera risposte che sono più fattuali, specifiche e diversificate quando testate su domande MS-MARCO e Jeopardy. RAG migliora anche i risultati nella verifica dei fatti di FEVER.
Questo mostra il potenziale di RAG come opzione valida per migliorare gli output dei modelli di linguaggio nei compiti che richiedono molte conoscenze.
Più recentemente, questi approcci basati su recupero sono diventati più popolari e sono combinati con LLM popolari come ChatGPT per migliorare le capacità e la coerenza fattuale.
Casi d'uso di RAG: generare titoli amichevoli per articoli ML
Di seguito, abbiamo preparato un tutorial che illustra l'uso di LLM open-source per costruire un sistema RAG per generare titoli brevi e concisi di articoli sull'apprendimento automatico: