Scaling Instruction-Finetuned Language Models
Cosa c'è di nuovo?
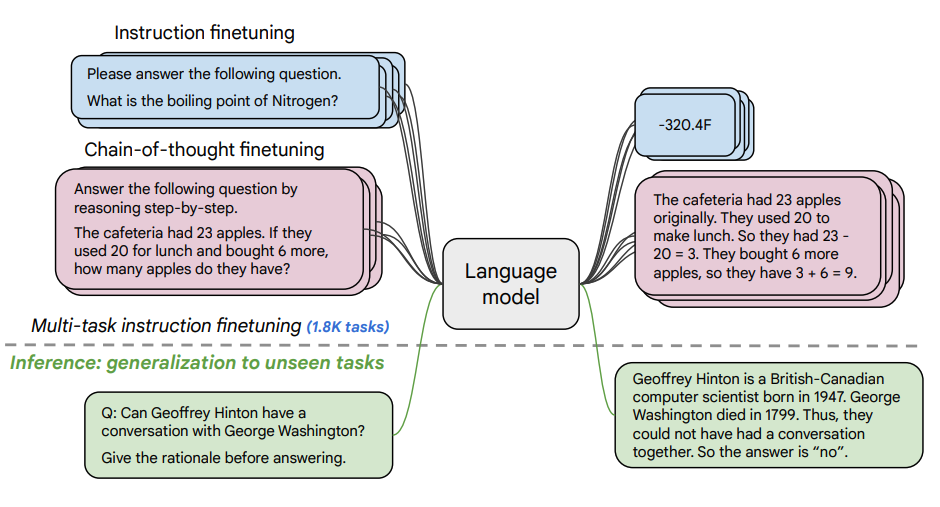
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Questo documento esplora i vantaggi del ridimensionamento instruction finetuning (opens in a new tab) e come migliora le prestazioni su una varietà di modelli (PaLM, T5), richiede configurazioni (zero-shot, few- shot, CoT) e benchmark (MMLU, TyDiQA). Questo viene esplorato con i seguenti aspetti: ridimensionamento del numero di attività (attività 1.8K), ridimensionamento delle dimensioni del modello e messa a punto dei dati della catena di pensiero (9 set di dati utilizzati).
Procedura di messa a punto:
- Le attività 1.8K sono state formulate come istruzioni e utilizzate per mettere a punto il modello
- Utilizza sia con che senza esemplari, sia con e senza CoT
Attività di messa a punto e attività trattenute mostrate di seguito:
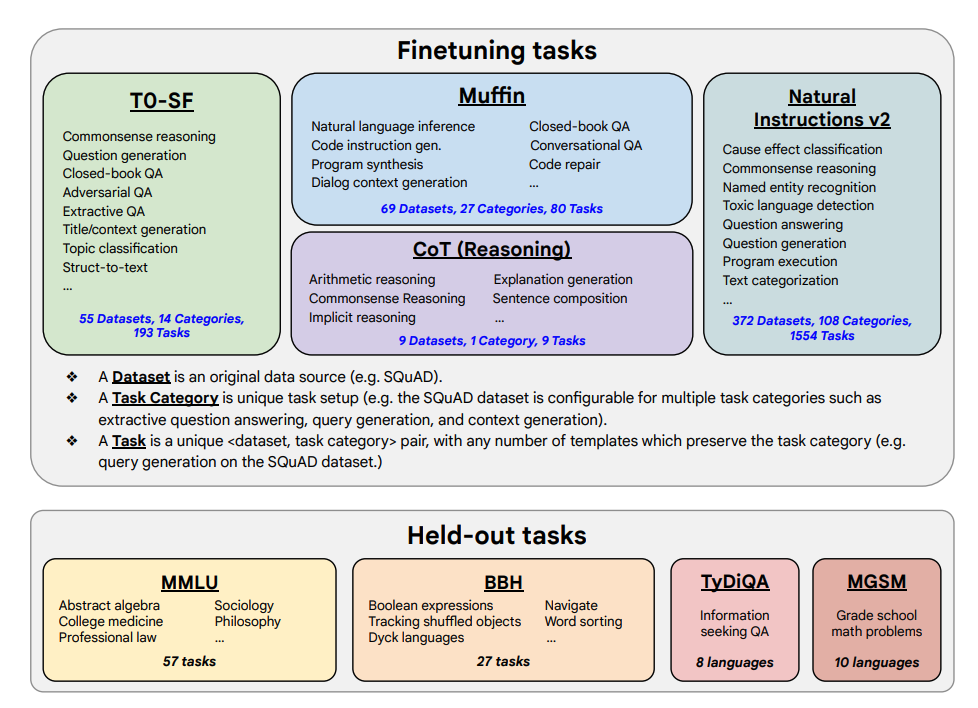
Capacità e risultati chiave
- La messa a punto delle istruzioni si adatta bene al numero di compiti e alle dimensioni del modello; ciò suggerisce la necessità di ridimensionare ulteriormente il numero di attività e le dimensioni del modello
- L'aggiunta di set di dati CoT nella messa a punto consente buone prestazioni nelle attività di ragionamento
- Flan-PaLM ha migliorato le capacità multilingue; Miglioramento del 14,9% su TyDiQA one-shot; Miglioramento dell'8,1% sul ragionamento aritmetico nelle lingue sottorappresentate
- Plan-PaLM funziona bene anche su domande di generazione a risposta aperta, che è un buon indicatore per una migliore usabilità
- Migliora le prestazioni nei benchmark RAI (Responsible AI).
- I modelli ottimizzati per le istruzioni Flan-T5 dimostrano forti capacità di pochi colpi e superano i checkpoint pubblici come T5
I risultati quando si ridimensiona il numero di attività di fine tuning e la dimensione del modello: si prevede che il ridimensionamento sia della dimensione del modello che del numero di attività di fine tuning continui a migliorare le prestazioni, sebbene il ridimensionamento del numero di attività abbia ridotto i rendimenti.
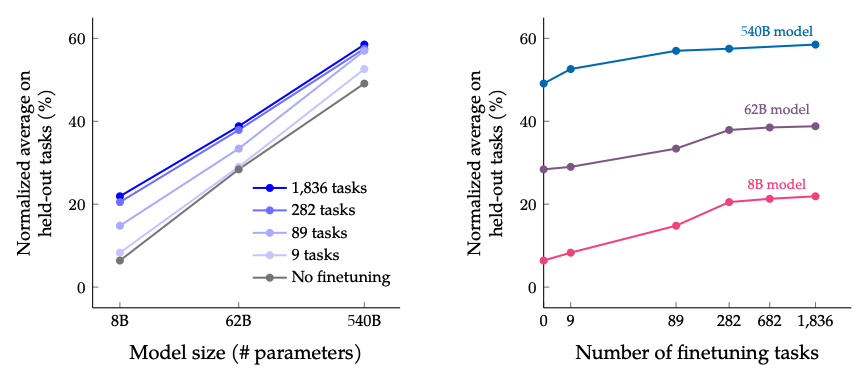
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
I risultati della messa a punto con dati non-CoT e CoT: la messa a punto congiunta di dati non-CoT e CoT migliora le prestazioni in entrambe le valutazioni, rispetto alla messa a punto solo di una o dell'altra.
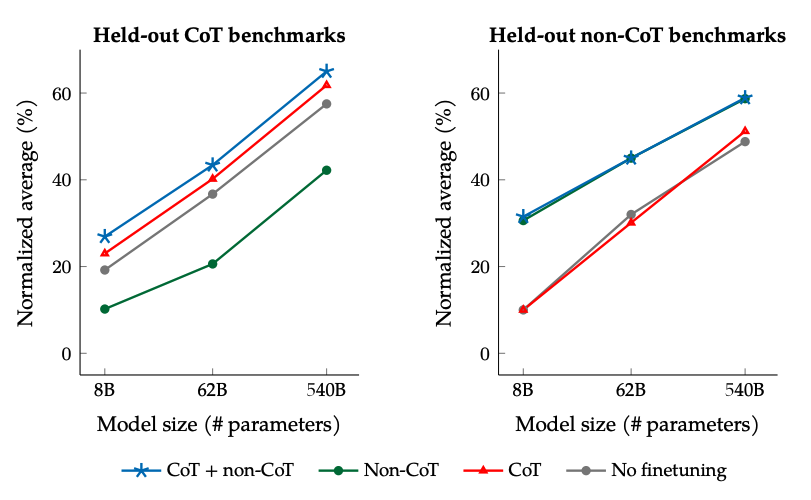
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Inoltre, l'autocoerenza unita al CoT raggiunge risultati SoTA su diversi benchmark. L'autocoerenza CoT + migliora anche significativamente i risultati sui benchmark che coinvolgono problemi matematici (ad esempio, MGSM, GSM8K).
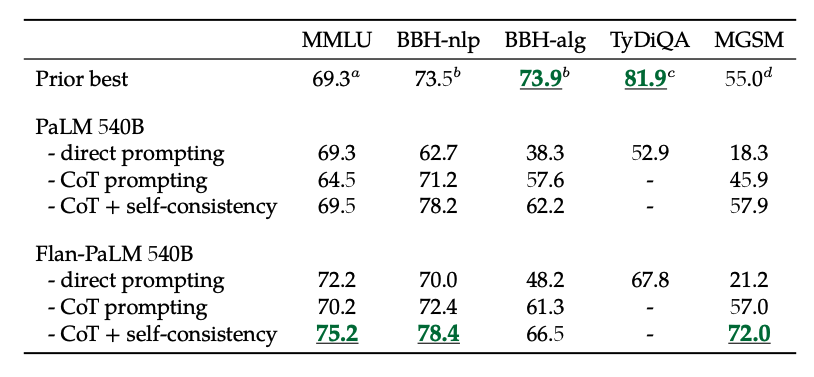
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
La messa a punto CoT sblocca il ragionamento zero-shot, attivato dalla frase "pensiamo passo dopo passo", sui compiti BIG-Bench. In generale, il CoT Flan-PaLM a zero-shot supera le prestazioni del CoT PaLM a zero-shot senza messa a punto.
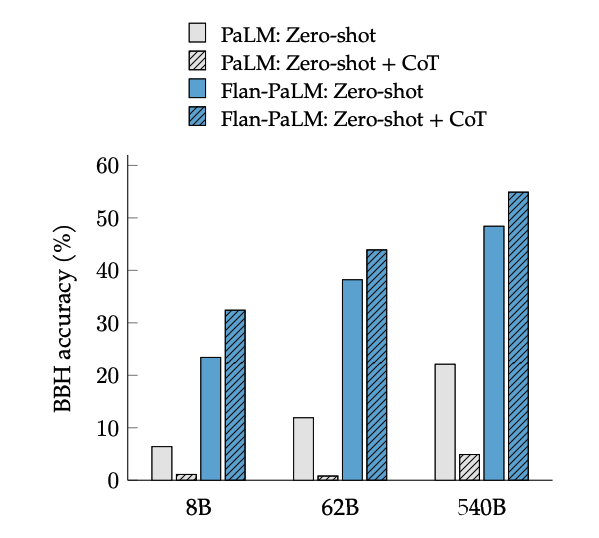
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Di seguito sono riportate alcune dimostrazioni di CoT a zero-shot per PaLM e Flan-PaLM in attività invisibili.
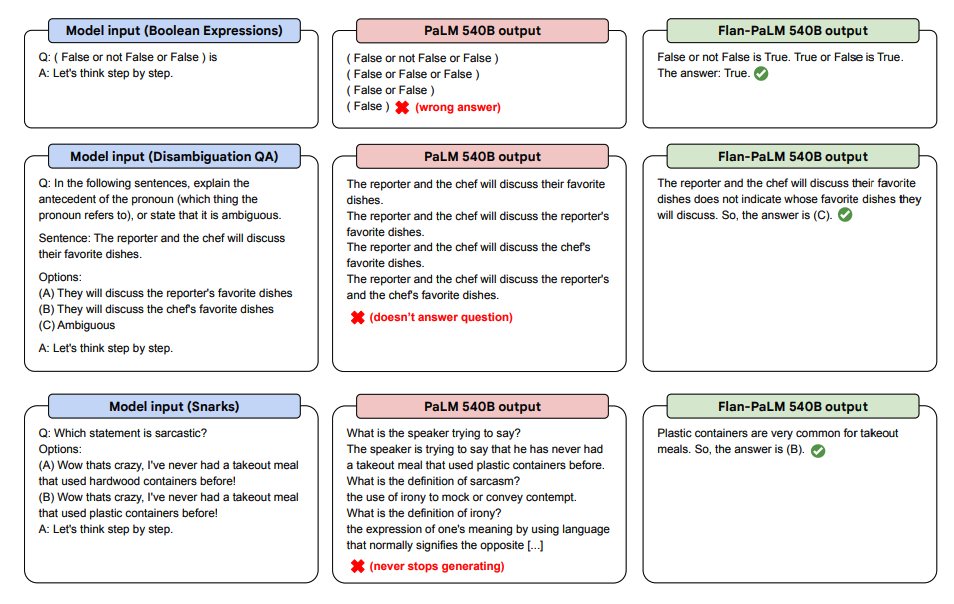
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Di seguito sono riportati altri esempi per il prompt a zero-shot. Mostra come il modello PaLM lotti con le ripetizioni e non risponda alle istruzioni nell'impostazione a zero-shot dove il Flan-PaLM è in grado di funzionare bene. Gli esemplari a few-shot possono mitigare questi errori.
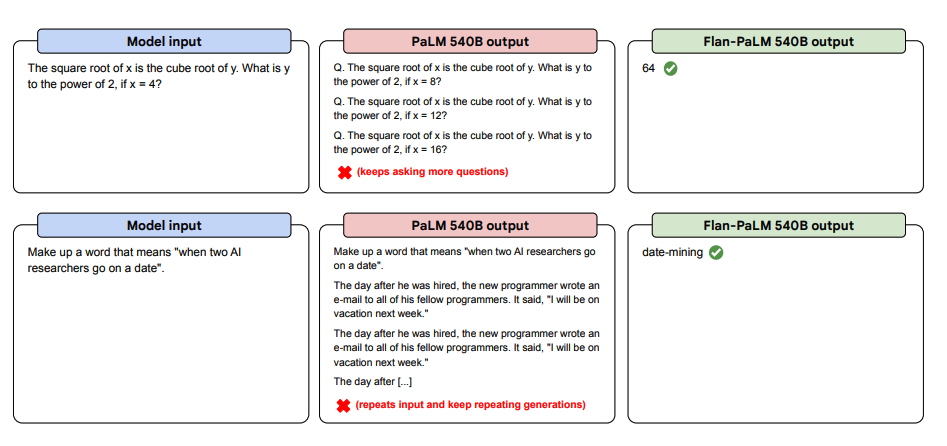
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Di seguito sono riportati alcuni esempi che dimostrano più capacità zero-shot del modello Flan-PALM su diversi tipi di domande aperte impegnative:
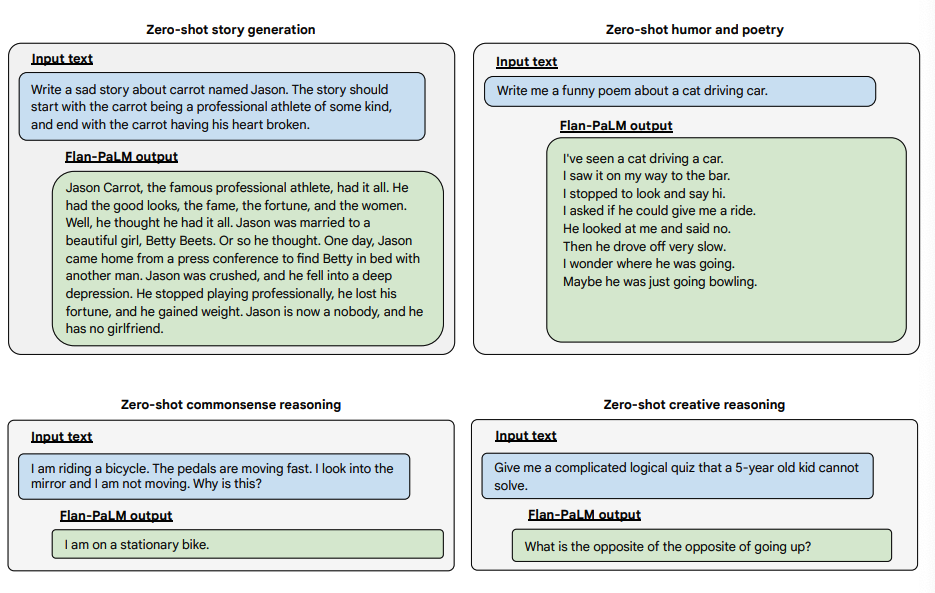
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
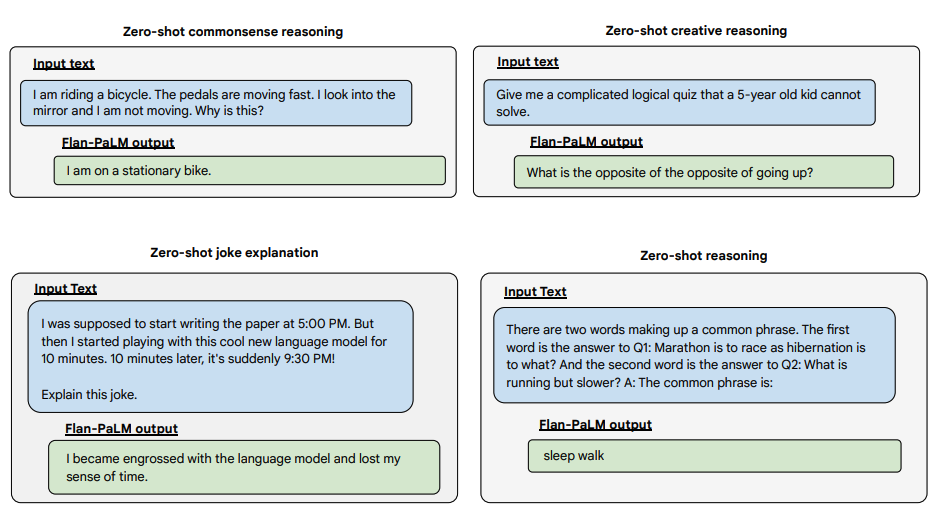
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
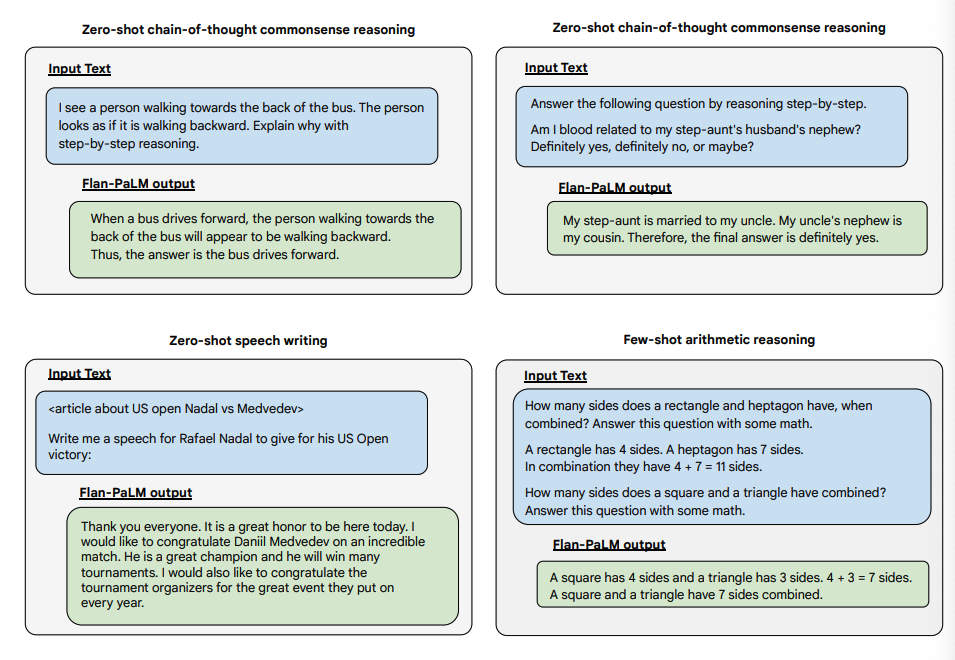
fonte dell'immagine: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Puoi provare i modelli Flan-T5 su Hugging Face Hub (opens in a new tab).