Generación de Recuperación Aumentada (RAG, por sus siglas en inglés)
Los modelos de lenguaje de propósito general pueden ajustarse para realizar varias tareas comunes, como el análisis de sentimientos y el reconocimiento de entidades nombradas. Por lo general, estas tareas no requieren conocimientos adicionales de fondo.
Para tareas más complejas y que requieren un mayor conocimiento, es posible construir un sistema basado en un modelo de lenguaje que acceda a fuentes de conocimiento externas para completar las tareas. Esto permite una mayor consistencia factual, mejora la fiabilidad de las respuestas generadas y ayuda a mitigar el problema de la "alucinación".
Los investigadores de Inteligencia Artificial de Meta introdujeron un método llamado Generación de Recuperación Aumentada (RAG, por sus siglas en inglés) (opens in a new tab) para abordar estas tareas que requieren un mayor conocimiento. RAG combina un componente de recuperación de información con un modelo generador de texto. RAG puede ajustarse con precisión y su conocimiento interno puede modificarse de manera eficiente sin necesidad de volver a entrenar todo el modelo.
RAG toma una entrada y recupera un conjunto de documentos relevantes o de apoyo dada una fuente (por ejemplo, Wikipedia). Los documentos se concatenan como contexto con la solicitud original y alimentan al generador de texto que produce la respuesta final. Esto hace que RAG sea adaptable para situaciones en las que los hechos pueden evolucionar con el tiempo. Esto es muy útil, ya que el conocimiento paramétrico de los grandes modelos de lenguaje es estático. RAG permite a los modelos de lenguaje evitar el proceso de reentrenamiento, lo que permite el acceso a la información más actual para generar información fiable a través de la generación basada en recuperación.
Lewis et al. (2021) propusieron una receta de ajuste de propósito general para RAG. Se utiliza un modelo preentrenado de secuencia a secuencia (seq2seq, por sus siglas en inglés) como memoria paramétrica y un índice de vectores densos de Wikipedia como memoria no paramétrica (al que se accede mediante un recuperador preentrenado neuronal). A continuación, se muestra una descripción general de cómo funciona el enfoque:
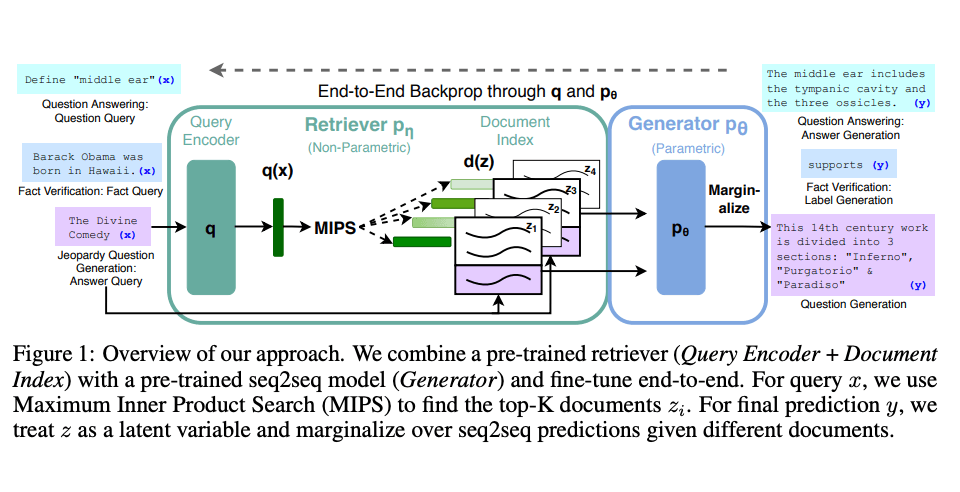
Image Source: Lewis et el. (2021) (opens in a new tab)
RAG tiene un buen rendimiento según varios indicadores, como Preguntas Naturales (abrir en una nueva pestaña), Preguntas de la Web (abrir en una nueva pestaña) y CuratedTrec. RAG genera respuestas que son más factuales, específicas y diversas cuando se prueba en preguntas de MS-MARCO y Jeopardy. RAG también mejora los resultados en la verificación de datos de FEVER.
Esto muestra el potencial de RAG como una opción viable para mejorar la información generada por los modelos de lenguaje en tareas que requiere muchos conocimientos.
Más recientemente, estos enfoques basados en recuperadores se han vuelto más populares y se combinan con modelos de lenguaje de última generación como ChatGPT para mejorar las capacidades y la consistencia factual.
En la documentación de LangChain puede encontrar un ejemplo sencillo de cómo utilizar recuperadores y modelos de lenguaje de última generación para responder preguntas apoyándose en referencias. (opens in a new tab)