LLaMA: Models de llenguatge base oberts i eficients
Aquesta secció està en desenvolupament intensiu.
Què hi ha de nou?
Aquest article presenta una col·lecció de models de llenguatge base que oscil·len entre 7B i 65B de paràmetres.
Els models s'entrenen en bilions de tokens amb conjunts de dades públicament disponibles.
El treball de (Hoffman et al. 2022) (opens in a new tab) mostra que, donat un pressupost de càlcul més petit, els models més petits entrenats en moltes més dades poden assolir un rendiment millor que els seus homòlegs més grans. Aquest treball recomana entrenar models de 10B en 200B de tokens. No obstant això, el document de LLaMA troba que el rendiment d'un model de 7B continua millorant fins i tot després de 1T de tokens.
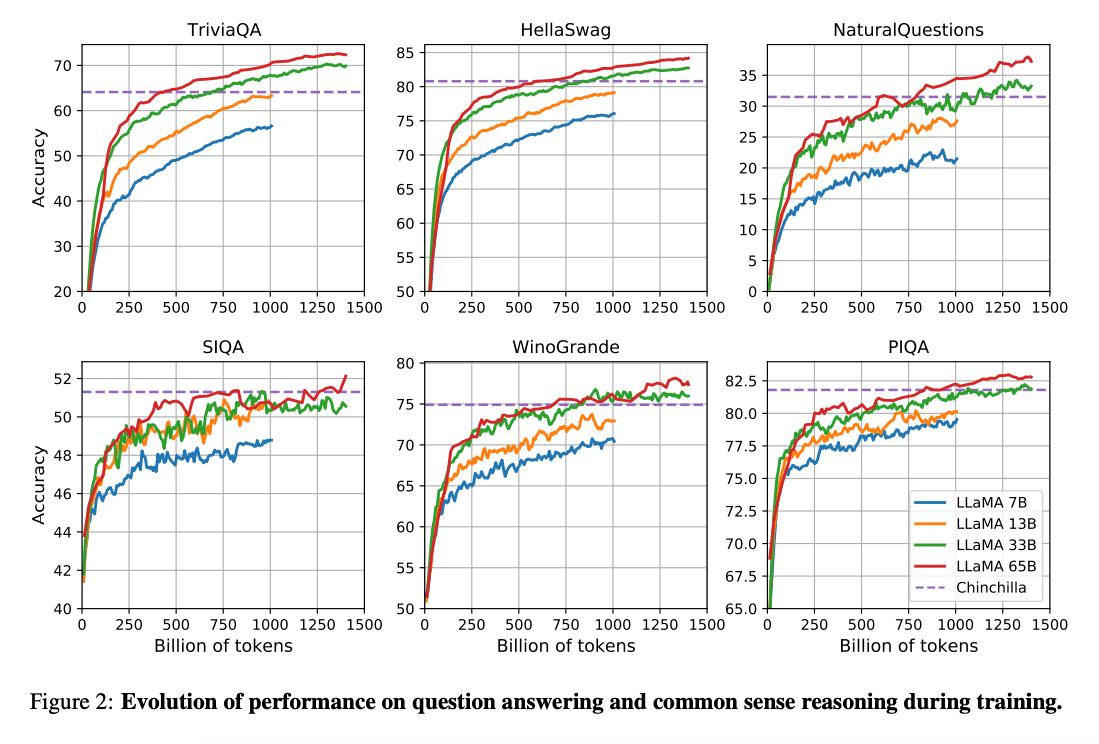
Aquest treball se centra en entrenar models (LLaMA) que obtinguin el millor rendiment possible en diversos pressupostos d'inferència, entrenant-se en més tokens.
Capacitats i resultats clau
En general, LLaMA-13B supera GPT-3(175B) en molts indicadors de referència, tot i ser 10 vegades més petit i possible d'executar-se en una única GPU. LLaMA 65B és competitiu amb models com Chinchilla-70B i PaLM-540B.
Article: LLaMA: Open and Efficient Foundation Language Models (opens in a new tab)
Codi: https://github.com/facebookresearch/llama (opens in a new tab)
Referències
- Koala: A Dialogue Model for Academic Research (opens in a new tab) (Abril 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (opens in a new tab) (Abril 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (opens in a new tab) (Març 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (opens in a new tab) (Març 2023)
- GPT4All (opens in a new tab) (Març 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (opens in a new tab) (Març 2023)
- Stanford Alpaca (opens in a new tab) (Març 2023)