Escalat de models de llenguatge amb ajust fi per instruccions
Què hi ha de nou?
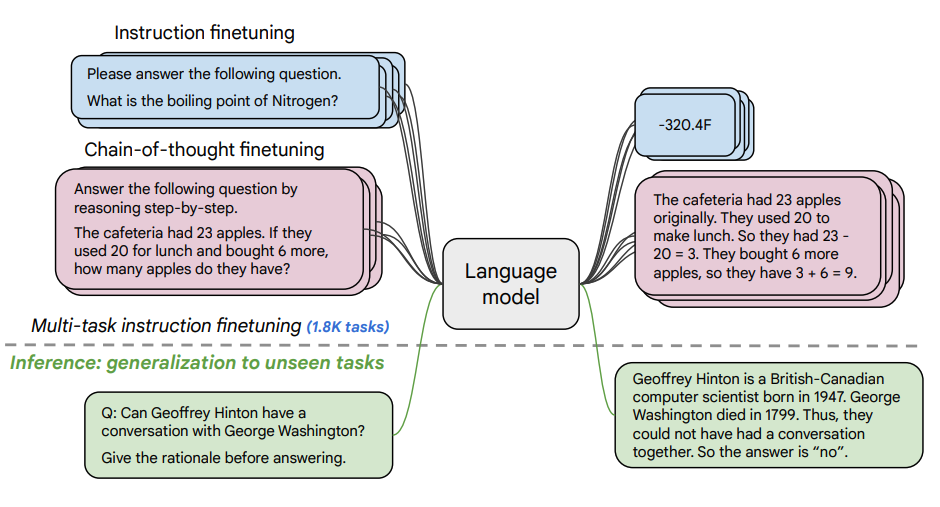
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Aquest article explora els avantatges de l'escalat de l'ajust fi per instruccions (opens in a new tab) i com millora el rendiment en una varietat de models (PaLM, T5), configuracions de sol·licitud (zero-shot, few-shot, CoT) i avaluacions (MMLU, TyDiQA). Això s'explora amb els següents aspectes: escalat del nombre de tasques (1.8K tasques), escalat de la mida del model i ajust fi en dades de cadena de pensament (9 conjunts de dades utilitzats).
Procediment d'ajust fi:
- Es van formular 1.8K tasques com a instruccions i es van utilitzar per ajustar fi el model.
- S'utilitzen amb i sense exemplars, i amb i sense CoT.
A continuació es mostren les tasques d'ajust fi i les tasques retingudes:
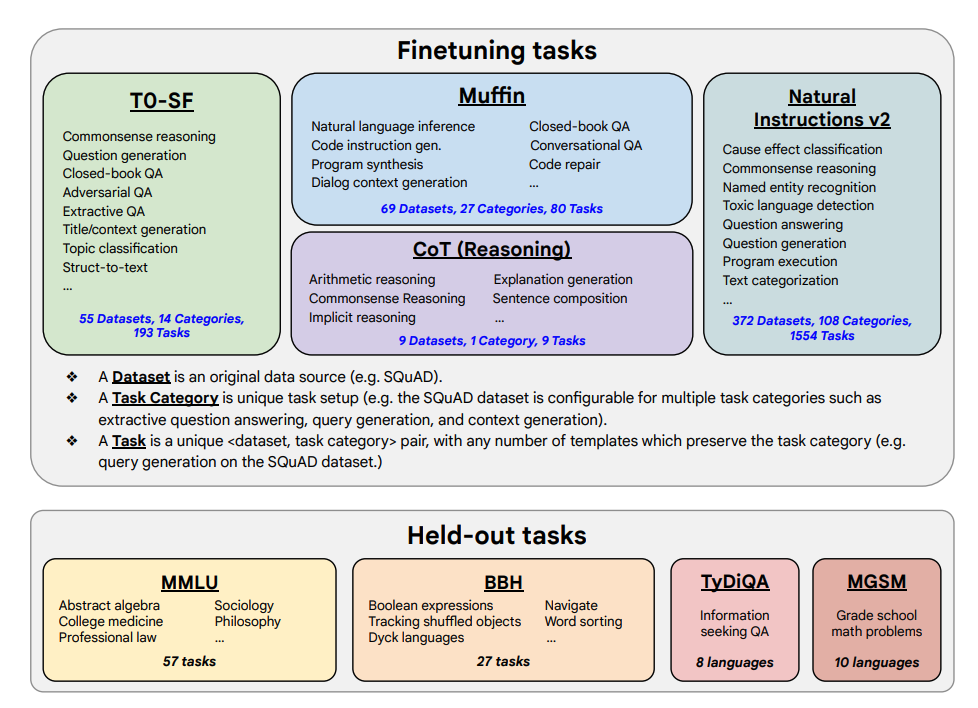
Capacitats i resultats clau
- L'ajust fi per instruccions escala bé amb el nombre de tasques i la mida del model; això suggereix la necessitat d'escalar encara més el nombre de tasques i la mida del model.
- Afegir conjunts de dades CoT a l'ajust fi permet obtenir un bon rendiment en tasques de raonament.
- Flan-PaLM té millorades habilitats multilingües; 14,9% de millora en TyDiQA amb un sol exemple; 8,1% de millora en raonament aritmètic en llengües poc representades.
- El Plan-PaLM també funciona bé en preguntes de generació obertes, la qual cosa és un bon indicador de millora en la usabilitat.
- Millora el rendiment en les avaluacions de IA responsable (RAI).
- Els models Flan-T5 ajustats per instruccions demostren fortes capacitats de few-shot i superen els punts de control públics com T5.
Els resultats quan s'escala el nombre de tasques d'ajust fi i la mida del model: s'espera que escalar tant la mida del model com el nombre de tasques d'ajust fi continuï millorant el rendiment, encara que escalar el nombre de tasques té rendiments decreixents.
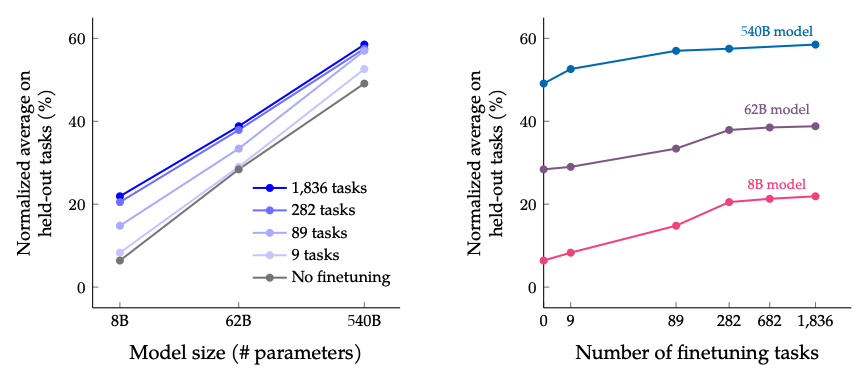
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Els resultats quan s'ajusta fi amb dades no-CoT i CoT: ajustar-se conjuntament en dades no-CoT i CoT millora el rendiment en ambdues avaluacions, en comparació amb ajustar-se només en una o l'altra.
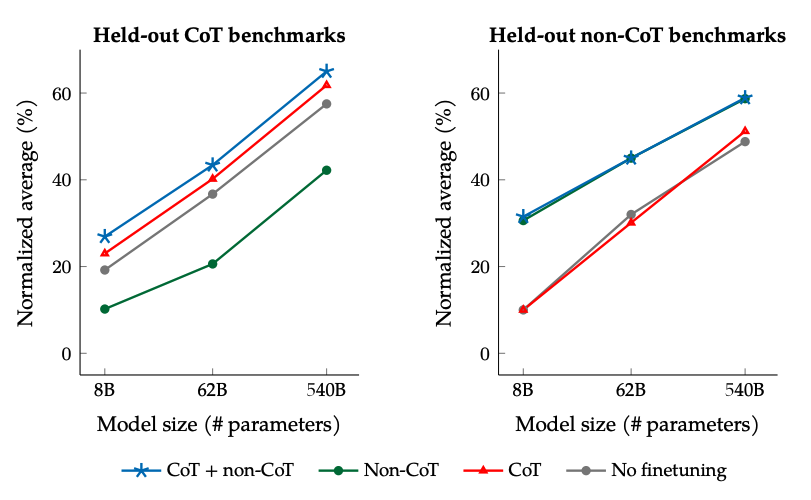
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A més, la consistència pròpia combinada amb CoT aconsegueix resultats SoTA en diversos avaluacions. CoT + autoconsistència també millora significativament els resultats en avaluacions que involucren problemes matemàtics (per exemple, MGSM, GSM8K).
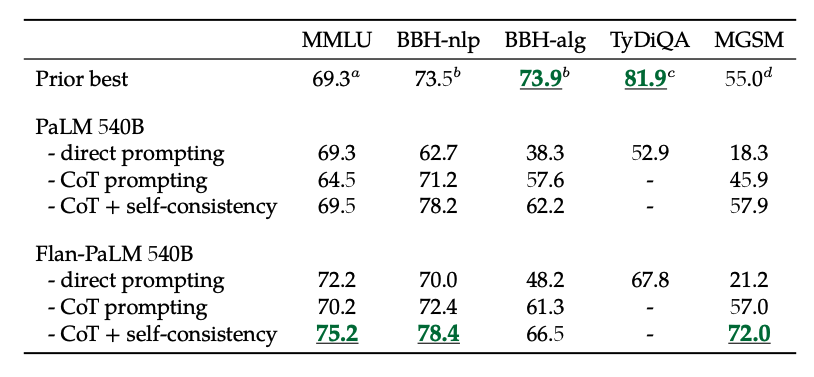
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
L'ajust fi CoT desbloqueja el raonament en zero-shot, activat per la frase "anem a pensar pas a pas", en tasques BIG-Bench. En general, el Flan-PaLM zero-shot CoT supera el PaLM zero-shot CoT sense ajust fi.
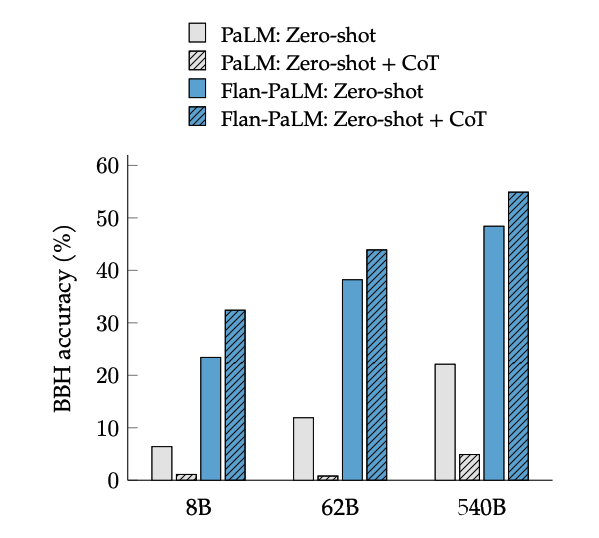
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuació es mostren algunes demostracions de CoT zero-shot per a PaLM i Flan-PaLM en tasques no vistes.
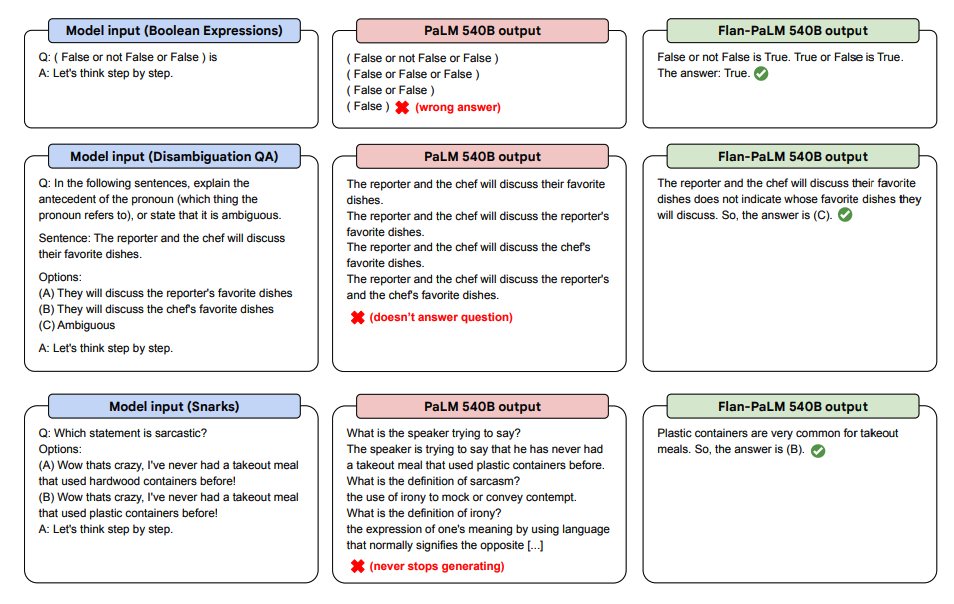
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuació es mostren més exemples de sol·licitud zero-shot. Es mostra com el model PaLM té problemes amb les repeticions i no respon a les instruccions en l'entorn zero-shot, mentre que el Flan-PaLM és capaç de funcionar bé. Els exemplars de few-shot poden mitigar aquests errors.
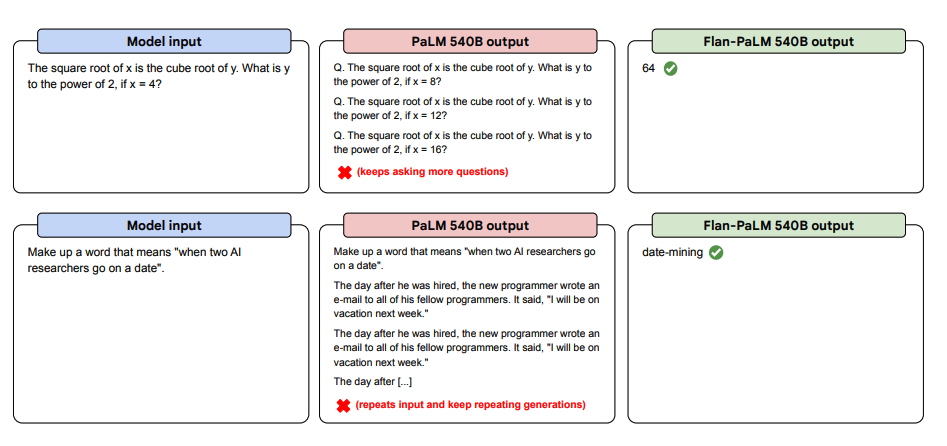
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
A continuació es mostren alguns exemples que demostren més capacitats zero-shot del model Flan-PALM en diversos tipus de preguntes obertes i desafiantes:
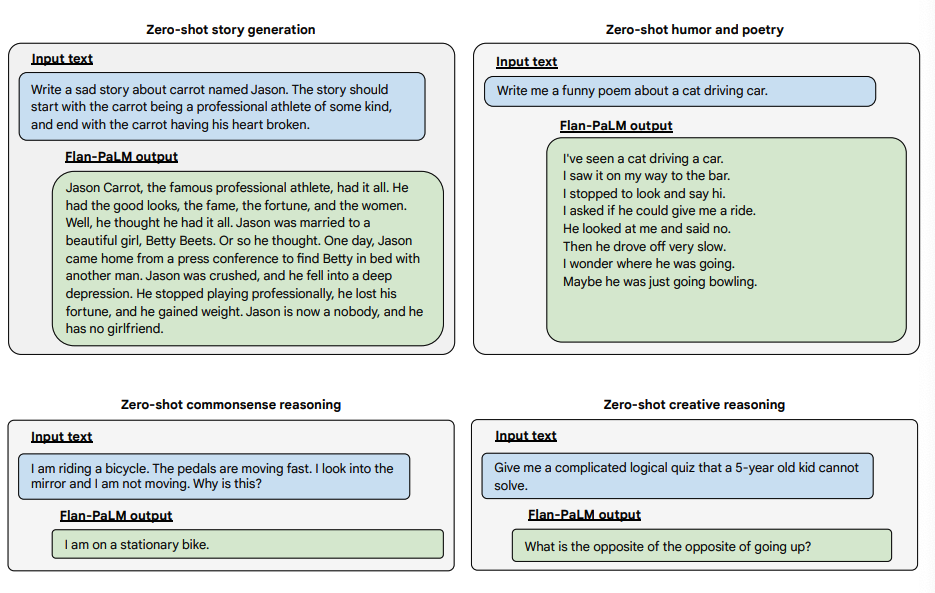
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
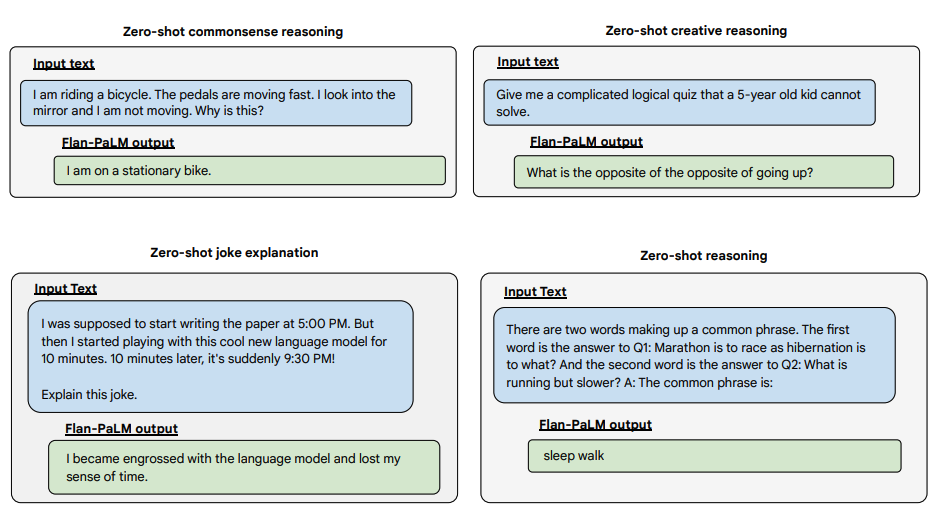
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
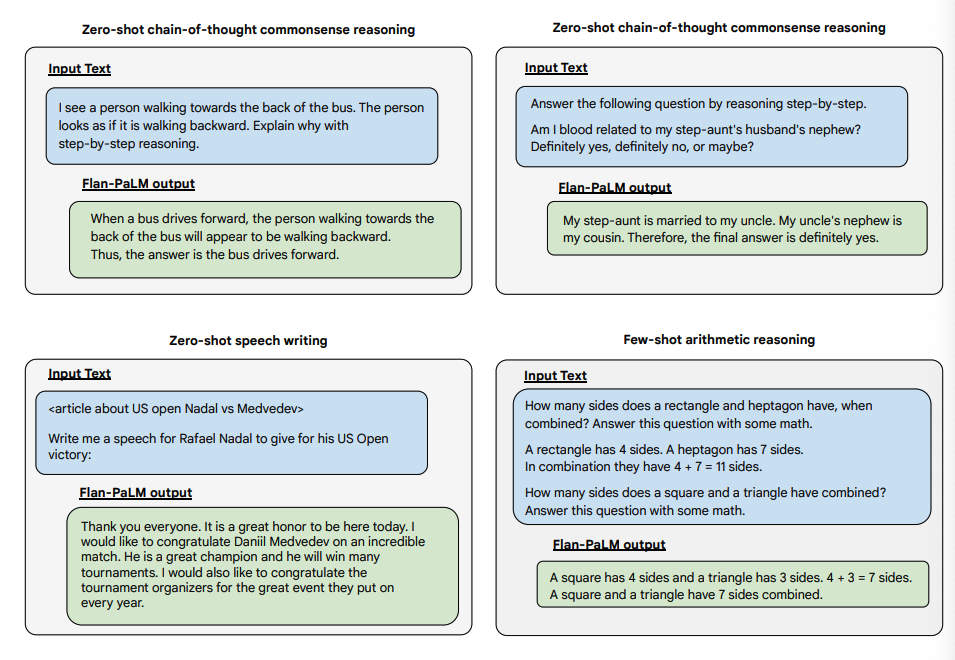
Font de la imatge: Scaling Instruction-Finetuned Language Models (opens in a new tab)
Podeu provar els models Flan-T5 a Hugging Face Hub (opens in a new tab).